
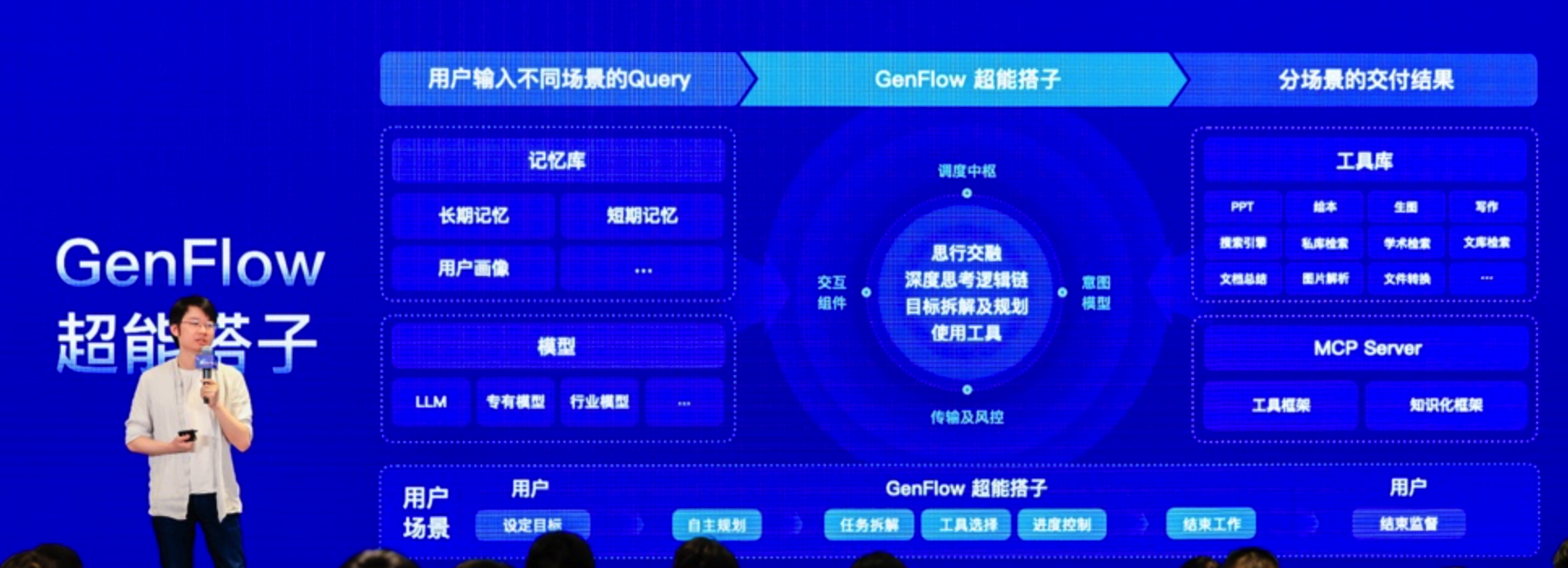

AI 时代的“数据之困”,什么是 AI-Ready Data
人工智能(AI)无疑是当今科技领域最激动人心的变革力量,它横跨各个行业,展现出重塑未来的巨大潜力。从智能客服到精准医疗,从自动驾驶到个性化推荐,AI的触角几乎无所不至。然而,在这股AI浪潮之下,一个普遍的困境也日益凸显:许多雄心勃勃的AI项目在起步后便步履维艰,难以实现预期的投资回报,甚至大量试点项目最终未能成功转化为生产力。 这种“雷声大,雨点小”的现象,不禁让人深思:AI的理想与现实之间,究竟横亘着怎样的鸿沟? 追根溯源,这一困境的核心往往直指AI的“食粮”——数据。数据是驱动AI系统洞察、预测和决策的燃料。然而,企业在将数据应用于AI时,普遍面临着一系列严峻挑战: 数据质量参差不齐:不准确、不完整、标签错误或充满噪声的数据是AI项目失败的常见元凶。 数据孤岛与集成难题:数据往往散落在企业内部各个孤立的系统中,格式各异,难以有效整合和统一访问。 缺乏标准化与有效治理:数据格式不统一、元数据缺失、数据血缘关系不清晰以及数据治理机制的薄弱,都为AI应用埋下了隐患。 这些普遍存在的数据问题,实际上反映了许多企业在AI战略上的一个深层错位:即,对AI技术本身抱有极高期望,却忽视了构建坚实数...