来自用户分享
在某事业单位做了五年运维,我和同事两个人管着十几人开发团队,还有 8 家厂商的外采系统(加起来有 30 多个应用)。两年前领导拍板上 K8s,我们熬夜搭集群、配 Jenkins 流水线,本以为能告别传统部署,结果掉进了新坑:每天 80% 时间都耗在敲 Kubectl 命令上,部署应用、调资源、查日志成了家常便饭。我们的开发团队里只有个别人懂 K8s,改完代码总得来找我们运维部署。厂商更离谱,供应商坚持要 ssh 进服务器改配置。
现状:K8s 用成了运维专属工具
我们的现状是:
为什么不用 PaaS 容器平台?
起初拒绝 PaaS 容器平台有两个执念:
- 习惯了命令行:觉得敲 Kubectl 比点鼠标快,YAML 配置出错了直接 vim 修改更直接。
- 担心开发越权:怕开放 PaaS 平台后,开发误删 Namespace 或改坏配置。
现在想想,这就是典型的技术自负……
痛点爆发,30 + 应用逼出平台工程需求
今年初新接 5 个外采系统后,运维组彻底绷不住了:
- 人力告急:我和同事每天加班到 9 点,还是处理不完部署需求,某次厂商更新导致集群崩溃,我们通宵抢救。
- 开发抱怨:前端改个页面要等运维 2 小时,开发组长甩来一句:你们运维是不是该扩招了?
- 领导卡成本:申请招人被驳回,理由是数字化转型要降本增效,试试平台工程,这词我还是第一次听说。
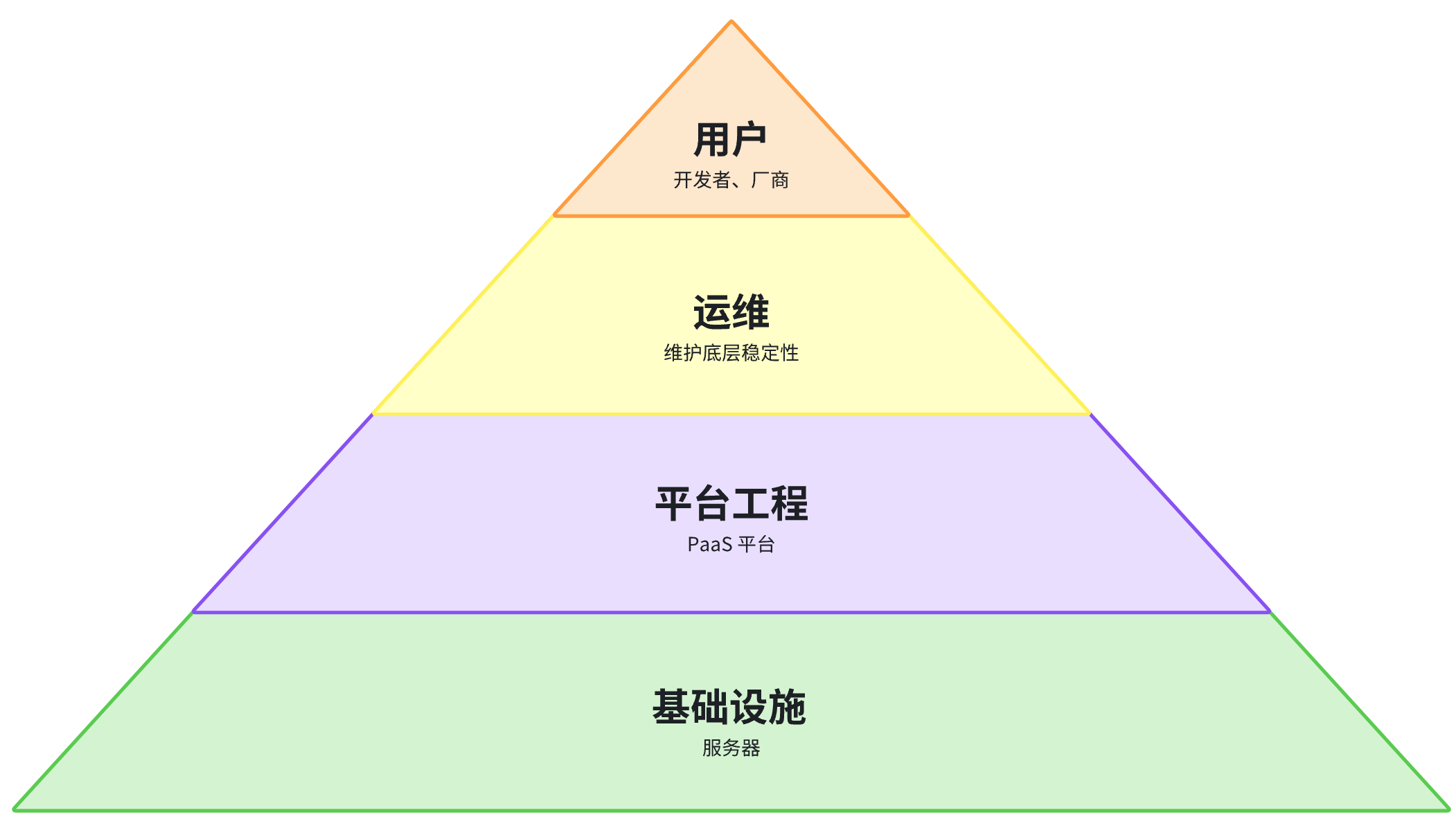
平台工程初探索
查资料发现平台工程说白了就是让专业的人干专业的事。开发专注写业务代码,不用学 K8s 术语。厂商专注交付应用,不用懂容器技术。运维专注底层稳定性。就像餐馆里,服务员不用会炒菜,厨师不用擦桌子,老板不用端盘子,各干各的,效率才高。
![]()
于是我尝试了国内热门的容器平台:
这俩平台都像给运维用的高级 K8s 管理工具,跟平台工程理念还差点意思。
偶然发现 Rainbond
在技术论坛刷到一篇讲述平台工程的文章,其中就提到了 Rainbond 能让开发不用学 K8s 也能自服务。抱着死马当活马医的心态试了试,结果被我需要的三个功能惊艳到:
开发自服务:拖代码就能部署,不用写 YAML
- 开发把 Java 代码拖进界面,直接下一步点点点,平台自动生成镜像 + 部署。
- 前端部署 Vue 项目,直接上传打包后的静态资源,平台自动生成 Nginx 配置。
厂商自助接入:独立空间 + 模板化部署
- 给每家厂商开独立团队空间,限制 CPU / 内存使用。
- 某厂商交来 JAR 包,他们自己上传部署,也是下一步点点点,15 分钟完成部署。
运维解放:从执行者变规则制定者
- 把常用中间件(Redis/MySQL)做成应用模板放到 Rainbond 内部的组件库,开发直接安装复用。
- 平台本身就包含了应用部署的规范,不管是开发还是厂商都按照这个执行。
现在的运维组
2 个人管 50 + 应用不是梦。
|
以前(原生 K8s) |
现在(Rainbond) |
| 应用部署 |
2 小时(运维全包) |
15 分钟(开发自助) |
| 厂商对接效率 |
每次 4 小时(远程协助) |
每次 30 分钟(自助部署) |
最后
这是我从传统运维转型平台工程的真实经历,说实话,单位里的业务系统涉及敏感信息,截图就不往外放了,但踩过的坑和尝到的甜头必须唠唠:
- 效率提升是真的香:以前 2 个人管 30 个应用累到吐血,现在管 50 + 应用还能准点下班,开发自己部署、厂商自助更新,运维只负责底层不出问题就好。
- 平台工程不是噱头:Rainbond 把 K8s 封装成了傻瓜式,开发不用学 YAML,厂商不用懂容器,这才是该有的降本增效。
- 踩过的坑不想让你再踩:Rancher 和 KubeSphere 不是不好,只是更适合大团队,像我们这种 2 个运维 + 十几开发的配置,Rainbond 的轻量级适配性更强。
如果你们单位也在搞云原生转型,尤其是运维人力紧张、开发对 K8s 不熟悉的情况,真心建议试试 Rainbond 社区版(开源免费的!)
做了五年运维,最深刻的感悟是:技术自负是效率的天敌。以前总觉得懂 Kubectl 命令才专业,直到被平台工程打脸,真正的专业不是炫技,而是让复杂技术为业务服务。现在我常跟新人说:能让开发和厂商爽的运维,才是好运维,而 Rainbond,就是那个让所有人都爽的神器。