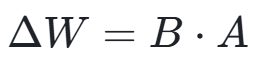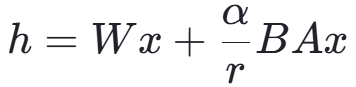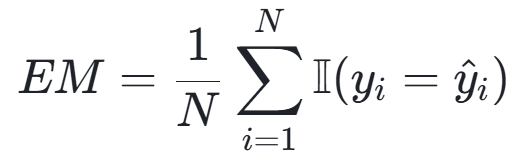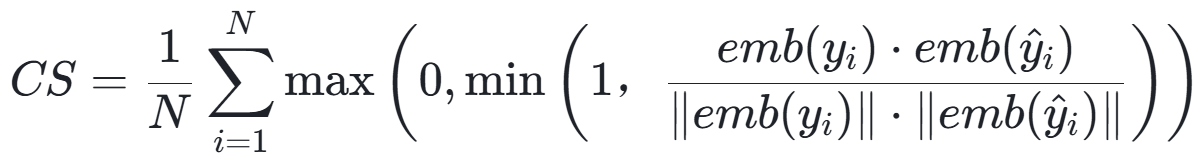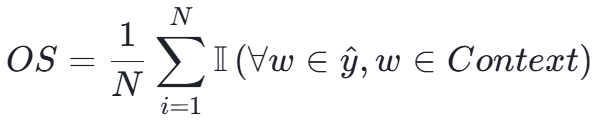在前面的教程中,我们通过优化检索器和召回策略,提升了RAG系统的检索精度。但要生成高质量的回复,大模型的能力同样关键。这就像烹饪,不仅需要优质食材(优化的检索模块),还需要优秀的厨师(强大的LLM)。
尽管掌握了基础,但在实际应用中,我们仍可能遇到问题:
🙋♂️“模型回复不够好,怎么办?”
🙋♂️“如何提升模型的理解和生成能力?”
光有大模型还不够,咱得让它更懂我们的业务、更贴地飞才行!
第 9、10 讲就是专门为此准备的——聚焦模型微调和知识蒸馏,让你的 RAG 系统既聪明又高效,真正从能用走向好用,稳稳拿捏复杂任务!
如何通过微调提升RAG系统的大模型能力?
影响RAG系统精度主要有两个因素:召回的效果 + 模型内容生成的能力
Why - 为什么做微调?
- 提升模型适应性:微调就像是给模型量身定制的“训练计划”,让模型在特定领域变得更加专业和强大。通过微调,模型能够更好地理解和处理特定领域的知识和任务。
- 增强生成能力:微调不仅提升模型的理解能力,还能增强其生成内容的质量和准确性。这对于需要高质量输出的应用场景尤为重要。
What - 微调是什么?
微调是通过在特定领域的数据上进一步训练预训练模型,使其更好地适应特定任务。这包括:
- 监督微调(SFT):通过注入领域特定的问答数据,让模型学习特定领域的知识表达模式。
- 领域自适应:使用LoRA等技术,冻结部分参数,仅训练适配层,以实现高效微调。
![]()
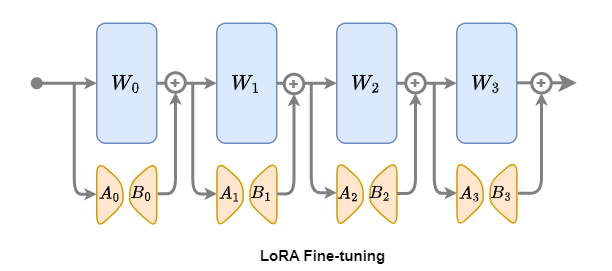
LoRA微调是一种针对Transformer模型设计的先进微调技术,其核心思想是在保持预训练模型参数W ∈ Rd×k固定不变的基础上,通过引入低秩矩阵A和B来模拟并实现微调过程。这种方法的独特之处在于,它并非直接调整原模型中的参数W ∈ Rd×k(如 W0、W1、W2、W3),而是为每一层额外引入可训练的参数——橙色矩阵B ∈ Rd×r和A ∈ Rr×k,仅对这些低秩矩阵进行微调。
数学解析
LoRA(Low-Rank Adaptation)方法基于低秩矩阵近似理论,通过冻结预训练模型的参数并注入可训练的低秩矩阵,实现了参数的高效微调。在数学层面,对于预训练权重矩阵W ∈ Rd×k,LoRA 将其更新量分解为两个低秩矩阵的乘积:
![]()
其中,B ∈ Rd×r,A ∈ Rr×k,且 r ≪ min(d,k)。这样的分解使得更新量具有更低的秩,从而减少了需要训练的参数数量。
在前向传播过程中,模型的输出变为:
![]()
其中:
- W 是预训练模型的原始权重矩阵
- x 是输入
- B 和 A 是低秩矩阵(秩为r)
- α 是缩放因子,用于灵活控制低秩矩阵对原始权重的调整强度。
- r 是秩
How - 如何进行微调?
Step1:选择合适的模型和数据集
选择一个适合的预训练模型,并准备一个包含特定领域问题的数据集。
Step2:配置微调参数
设置微调的参数,如学习率、批次大小和训练轮次。
Step3:执行微调
使用LazyLLM等工具进行微调,监控训练过程,确保模型逐步优化。
Step4:评估和优化
通过评测集评估微调后的模型性能,并根据结果进行进一步优化。
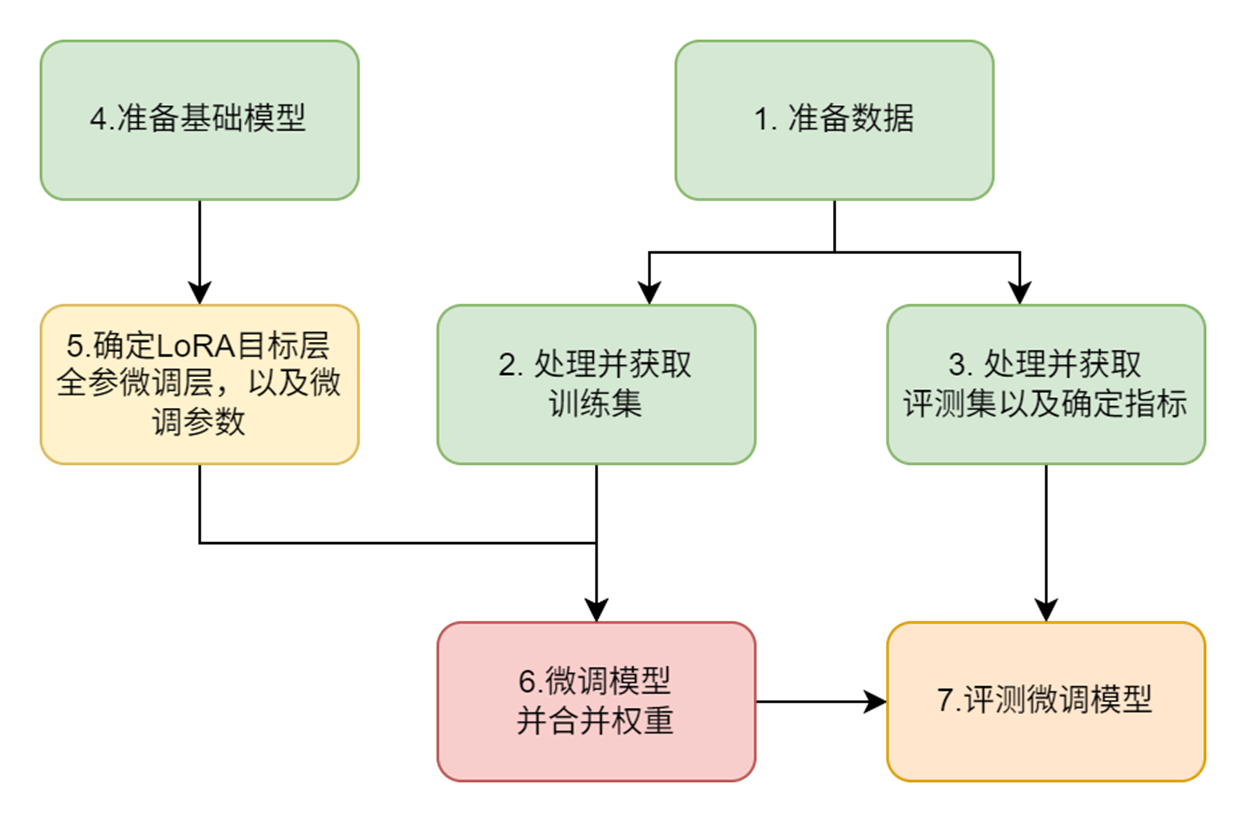
![]()
基于LazyLLM对大模型进行微调的整体框架
大模型微调实践举例
数据示例:
[
{
"instruction": "请用下面的文段的原文来回答问题\n\n### 已知文段:黄独(学名:)为薯蓣科薯蓣属的植物。多年生缠绕藤本。地下有球形或圆锥形块茎。叶腋内常生球形或卵圆形珠芽,大小不一,外皮黄褐色。心状卵形的叶子互生,先端尖锐,具有方格状小横脉,全缘,叶脉明显,7-9条,基出;叶柄基部扭曲而稍宽,与叶片等长或稍短。夏秋开花,单性,雌雄异株,穗状花序丛生。果期9-10月。分布于大洋洲、朝鲜、非洲、印度、日本、台湾、缅甸以及中国的江苏、广东、广西、安徽、江西、四川、甘肃、云南、湖南、西藏、河南、福建、浙江、贵州、湖北、陕西等地,生长于海拔300米至2,000米的地区,多生于河谷边、山谷阴沟或杂木林边缘,目前尚未由人工引种栽培。在美洲也可发现其踪迹,对美洲而言是外来种,有机会在农田大量繁殖,攀上高树争取日照。英文别名为air potato。黄药(本草原始),山慈姑(植物名实图考),零余子薯蓣(俄、拉、汉种子植物名称),零余薯(广州植物志、海南植物志),黄药子(江苏、安徽、浙江、云南等省药材名),山慈姑(云南楚雄)\n\n### 问题:黄独的外皮是什么颜色的?\n",
"input": "",
"output": "外皮黄褐色"
},
...
运行代码:
import lazyllm
from lazyllm import finetune, deploy, launchers
model = lazyllm.TrainableModule(model_path)\
.mode('finetune')\
.trainset(train_data_path)\
.finetune_method((finetune.llamafactory, {
'learning_rate': 1e-4,
'cutoff_len': 5120,
'max_samples': 20000,
'val_size': 0.01,
'per_device_train_batch_size': 2,
'num_train_epochs': 2.0,
'launcher': launchers.sco(ngpus=8)
}))\
.prompt(dict(system='You are a helpful assistant.', drop_builtin_system=True))\
.deploy_method(deploy.Vllm)
model.evalset(eval_data)
model.update()
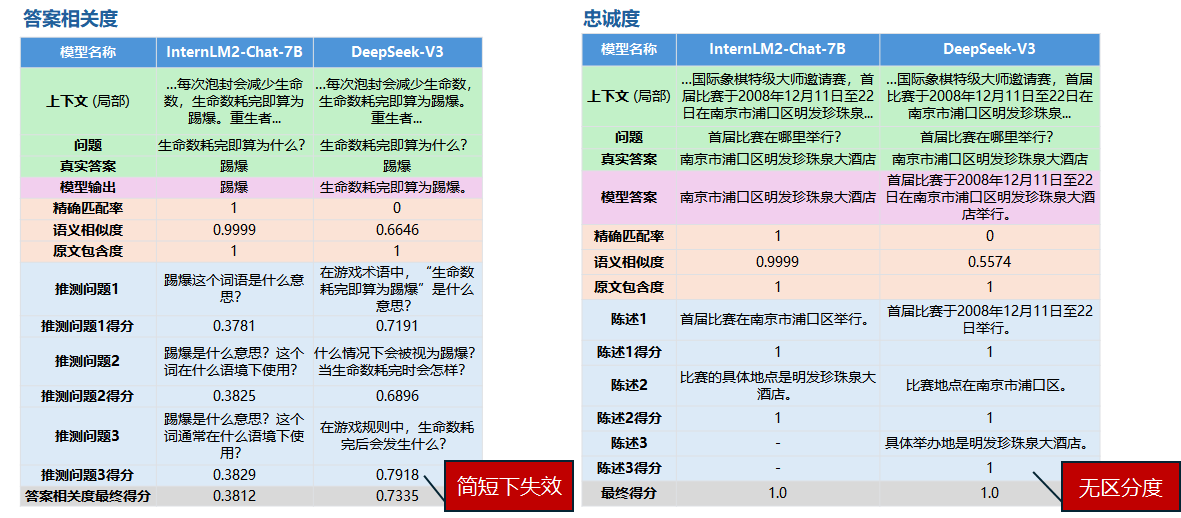
评价指标设计:
![]()
原始评价指标的缺陷
这里,针对我们的任务特点,设计了三个维度的评价指标:
![]()
![]()
![]()
指标对比分析
|
指标维度 |
取值范围
(单项) |
理想值
(单项) |
数值特征
(单项) |
优势 |
局限性 |
任务评价维度说明 |
|
精确匹配率 |
{0, 1} |
1.0 |
二元判断 |
结果明确,无歧义 |
对表述差异零容忍 |
有多少推理能100%忠于答案 |
|
语义相似度 |
[0, 1] |
1.0 |
连续数值 |
捕捉语义相似性 |
依赖编码模型质量 |
由于选取片段范围,或者表述有改变,所以用相似度来评价同一内容的不同表述; |
|
原文包含度 |
{0, 1} |
1.0 |
二元判断 |
确保答案忠实原文 |
忽略合理同义替换 |
任务要求,回答必须是用原文,此指标可反映答案是否都源自原文; |
评测结果对比:
|
模型 |
精确匹配率 |
语义相似度 |
原文包含度 |
|
Internlm2-Chat-7B |
2.10%
(21) |
74.51%
(746.6) |
5.19%
(52) |
|
DeepSeek-V3 |
5.29%
(53) |
74.85%
(750.0) |
15.17%
(152) |
|
Internlm2-Chat-7B训练后 |
39.72%
(398) |
86.19%
(863.6) |
94.91%
(951) |
从上面的评测结果我们可以看出,微调后的模型要比微调前,甚至是在线大模型的各项指标都要明显好。
- 精确匹配率飞跃
- 微调后提升 37.62个百分点(2.10% → 39.72%),超过在线模型近8倍
- 说明模型学会遵循特定答案格式
- 语义相关性优化
- 相似度提升11.68个百分点(74.51% → 86.19%)
- 与在线模型(600多B的大模型)对比:+11.34个百分点优势
- 原文依赖度质变
- 包含度从5.19%跃升至94.91%,提升幅度达18.3倍
- 表明模型已掌握:
- ✅ 关键信息定位能力
- ✅ 原文提取策略
- ✅ 知识边界控制(避免幻觉)
基于实验数据我们可以得出结论:
RAG系统中,在召回模块准确和召回无误的前提下,生成模块中模型对任务的适应程度大大影响着最终的效果,而微调是一个有效的手段可以提升模型适应下游任务的能力,甚至通过微调后提升的该能力是可以很好超过通用大模型的。
Embedding微调实践举例
数据示例:
{"query":"What was the total stockholder's equity (deficit) for Peloton Interactive, Inc. as of June 30, 2021?","pos":["As of June 30, 2021, Peloton Interactive, Inc.'s consolidated statements reflected a total stockholder's equity (deficit) of $1,754.1 million."],"neg":["In June 2023, the company entered into an ASR agreement to repurchase $500 million of its common stock with a completion date no later than August 2023, and in 2024, the company expects to repurchase $2.0 billion of its common stock.",...,"\u2022Overhead costs as a percentage of net sales increased 40 basis points due to wage inflation and other cost increases, partially offset by the positive scale impacts of the net sales increase and productivity savings."],"prompt":"Represent this sentence for searching relevant passages: "}
运行代码:
embed = lazyllm.TrainableModule(embed_path)\
.mode('finetune').trainset(train_data_path)\
.finetune_method((
lazyllm.finetune.flagembedding,
{
'launcher': lazyllm.launchers.remote(nnode=1, nproc=1, ngpus=4),
'per_device_train_batch_size': 16,
'num_train_epochs': 2,
}
))
docs = Document(kb_path, embed=embed, manager=False)
docs.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
retriever = lazyllm.Retriever(doc=docs, group_name="split_sent", similarity="cosine", topk=1)
retriever.update()
效果评测:
|
|
微调前
bge-large-zh-v1.5 |
微调后
bge-large-zh-v1.5 |
|
上下文召回率 |
78.28 |
88.57 |
|
上下文相关度 |
75.71 |
86.57 |
可以看到,在微调后,两个指标都得到了显著的提升。说明微调是有效的!整体的评估流程为:加载评测集 →
使用检索服务(微调后部署起来的服务)→ 执行批量推理 → 计算双指标。
如何通过思维链蒸馏增强RAG系统的小模型推理能力?
为什么要做思维链蒸馏?
- 提升推理能力:思维链蒸馏通过让模型学习推理过程,显著提升其解决复杂问题的能力。
- 增强小模型表现:即使是小模型,通过思维链蒸馏也能具备强大的推理能力,适合资源受限的环境。
思维链蒸馏究竟是什么?
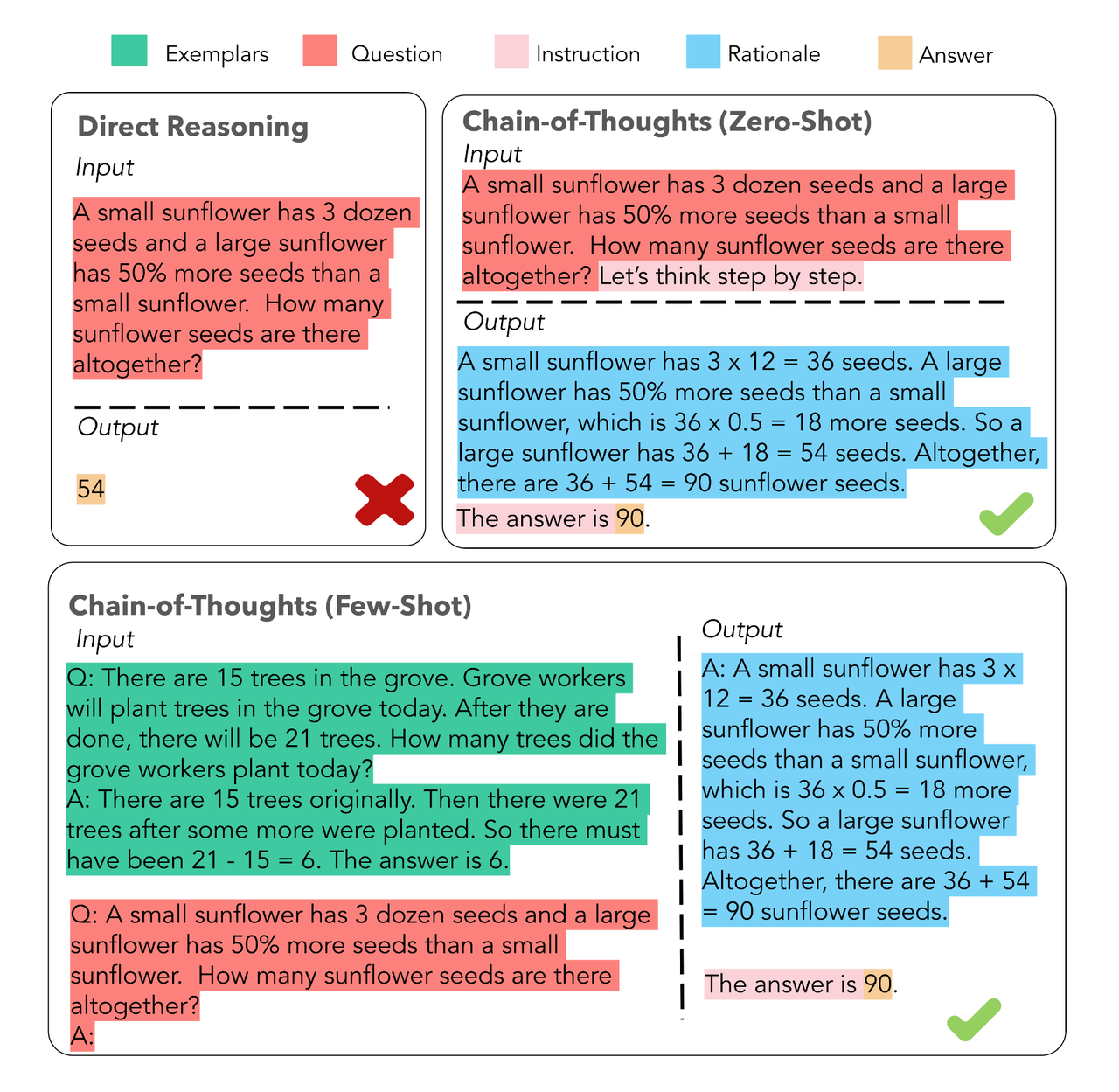
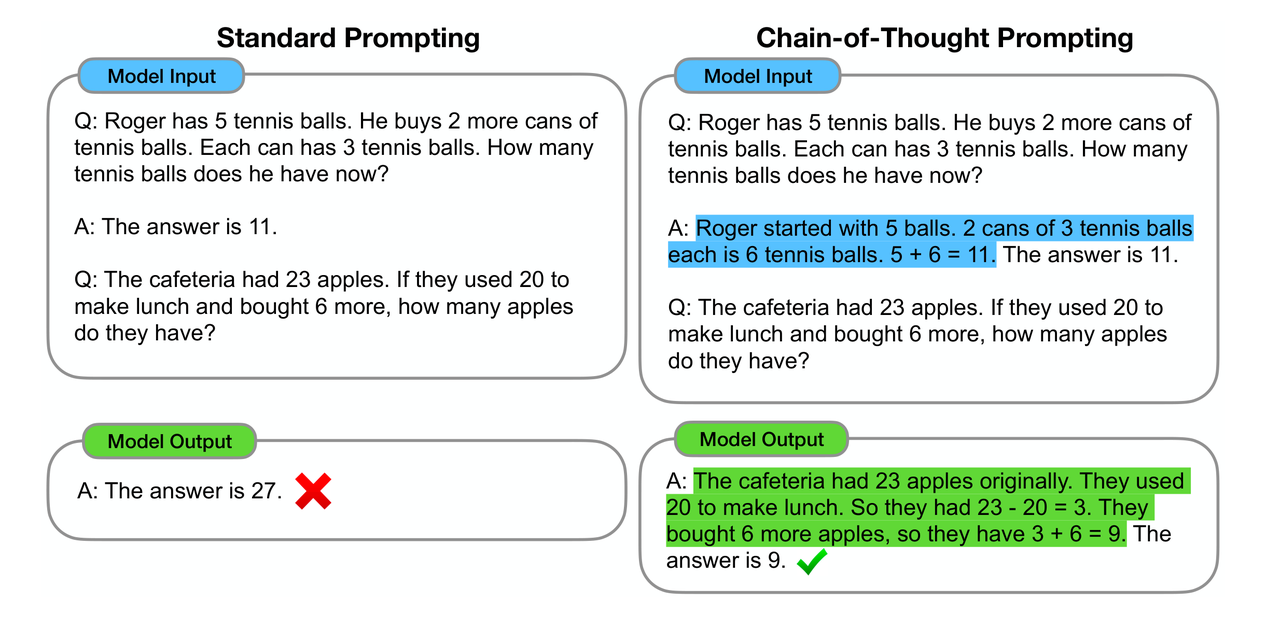
思维链CoT
![]()
一个完整的包含 CoT 的 Prompt 往往由三部分组成:
- 指令(Instruction):明确任务目标与输出格式规范(如JSON/Markdown结构化要求);
- 逻辑(Rationale):包含多跳推理路径、领域知识调用及中间验证步骤;
- 示例(Exemplars):提供少样本(Few-Shot)的解题范式,每个示例包含完整的问题-推理-答案三元组。
思维链蒸馏
思维链蒸馏通过让大模型生成推理链,然后让小模型学习这些推理链,从而提升小模型的推理能力。这包括:
![]()
- 知识蒸馏:通过监督微调,让小模型学习大模型的推理过程。
- 生成思维链:大模型在生成答案时,逐步展示其推理过程,帮助小模型学习。
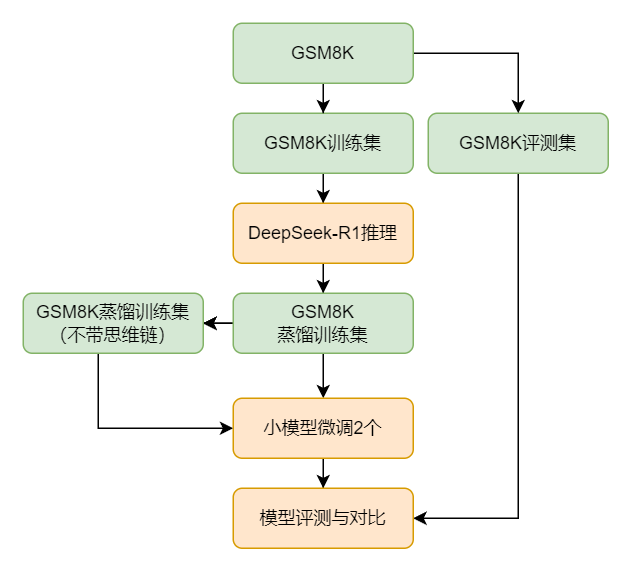
如何进行思维链蒸馏?
Step1:准备数据集
准备一个数据集,在划分训练集和评测集后,使用DeepSeek-R1对训练集进行推理生成蒸馏训练集(带思维链)。
Step2:配置蒸馏参数
设置蒸馏的参数,如学习率和训练轮次。
Step3:执行蒸馏
使用LazyLLM里封装的工具进行蒸馏,监控训练过程,确保小模型逐步学习推理能力。
Step4:评估和优化
通过评测集评估蒸馏后的小模型性能,并根据结果进行进一步优化。
![]()
基于DeepSeek-R1对小模型蒸馏的整体流程
实现代码
蒸馏数据
基于预处理好的训练集,将它处理后喂给DeepSeek-R1来实现数据的蒸馏,以构造出新的训练集。
import json
from lazyllm import warp
def load_data(data_path):
with open(data_path, 'r') as file:
dataset = json.load(file)
return dataset
def save_res(data, file_path):
with open(file_path, 'w') as file:
json.dump(data, file, ensure_ascii=False, indent=4)
def distill_dataset(data_path, model=None, demo=False):
inputs = load_data(data_path)[:1] if demo else load_data(data_path)
with warp(_concurrent=1) as wp:
wp.func = model
res_list = []
try_n = 0
while inputs:
print(">>>" * 12, f"{try_n+1} times left: ", len(inputs))
querys = [item['instruction'] for item in inputs]
results = wp(querys)
valid_data, inputs = filter(inputs, results)
res_list.extend(valid_data)
try_n += 1
if try_n == 15:
break
res_list = res_list * 120 if demo else res_list
distilled_train_set_path = build_data_path('distilled_train_data.json')
save_res(res_list, distilled_train_set_path)
save_res(inputs, build_data_path('left_data.json'))
return distilled_train_set_path
数据示例:
{
"instruction": "Mel is three years younger than Katherine. When Katherine is two dozen years old, how old will Mel be in years?",
"output": "<think>\nOkay, let's see. The problem says Mel is three years younger than Katherine. So, if I figure out Katherine's age first, then I can subtract three to get Mel's age. \n\nThe question is asking, when Katherine is two dozen years old, how old will Mel be? Hmm, a dozen is 12, so two dozen would be 24. Wait, is that right? Yeah, 12 times 2 is definitely 24. So Katherine will be 24 years old at that time.\n\nSince Mel is three years younger, I need to subtract 3 from Katherine's age. Let me do the math here: 24 minus 3 equals 21. So that should be Mel's age when Katherine is 24. Let me double-check. If Mel is always three years younger, then no matter when, the difference stays the same. So when Katherine is 24, subtracting 3 gives 21. Yeah, that makes sense. I think that's the answer.\n</think>\n\nWhen Katherine is two dozen (24) years old, Mel, being three years younger, will be:\n\n\\boxed{21}",
"input": ""
}
微调模型
在上一步获得训练集的基础上,我们可以基于LazyLLM来实现微调、推理和评测。
import lazyllm
from lazyllm import finetune, deploy, launchers
# 获取数据
train_set_path, eval_set_path = get_dataset()
eval_set = load_data(eval_set_path)
# 蒸馏数据
teacher_model = lazyllm.OnlineChatModule('DeepSeek-R1')
sft_data_path = distill_dataset(train_set_path, teacher_model)
# 微调模型
infer_data = [item['instruction'] for item in eval_set]
student_model = lazyllm.TrainableModule('internlm2-chat-7b')\
.mode('finetune')\
.trainset(sft_data_path)\
.finetune_method((finetune.llamafactory, {
'learning_rate': 1e-4,
'cutoff_len': 5120,
'max_samples': 20000,
'val_size': 0.01,
'per_device_train_batch_size': 2,
'num_train_epochs': 2.0,
'launcher': launchers.sco(nnode=1, nproc=8, ngpus=8)
}))\
.prompt(dict(system='You are a helpful assistant.', drop_builtin_system=True))\
.deploy_method(deploy.Vllm)
student_model._prompt._soa = '<|im_start|>assistant\n\n<think>'
student_model.evalset(infer_data)
student_model.update()
## 评测模型
score = caculate_score(eval_set, student_model.eval_result)
print("All Done. Score is: ", score)
效果评测:
|
模型 |
InternLM2-7B-Chat
【原始】 |
InternLM2-7B-Chat
【蒸馏后-不带思维链】 |
InternLM2-7B-Chat
【蒸馏后】 |
DeepSeek-R1
【教师模型】 |
|
答对题数 |
331 |
839 |
951 |
1201 |
|
准确率(1319题) |
25.09% |
63.61% |
72.10% |
91.05% |
基于上面表格我们可以看出:
- 基础蒸馏增益:无思维链的蒸馏使准确率从25.09%跃升至63.61%,绝对提升达38.5个百分点,证明基础蒸馏是有效的;
- 思维链附加值:引入CoT机制后准确率再提升8.5个百分点,验证思维链对知识迁移的强化作用;
- 师生差距:学生模型(72.1%)与教师模型(91.05%)存在18.95个百分点的性能差,揭示模型容量对推理能力的关键影响;
- 规模效率比:7B蒸馏模型达到671B教师模型79.2%的准确率水平,以近1/100参数量实现4/5的性能表现!
综合:RAG 文理助手系统的搭建
结合数学推理能力 + 阅读理解能力。基于InternLM2-7B-Chat重新使用混合数据集(蒸馏使用的带思维链的GSM8k数据集和微调使用的CMRC2018训练集)进行微调过程。
效果评测:
|
任务
(数据集) |
阅读理解信息抽取能力
(CMRC2018) |
数学推理能力
(GSM8K) |
|
模型 |
精确匹配率 |
语义相似度 |
原文包含度 |
准确度 |
|
Internlm2-Chat-7B |
2.10%
(21) |
74.51%
(746.6) |
5.19%
(52) |
25.09%
(331) |
|
DeepSeek-R1 |
2.3%
(23) |
69.62%
(697.56) |
7.78%
(78) |
91.05%
(1201) |
|
Internlm2-Chat-7B
训练后(仅CMRC2018数据) |
39.72%
(398) |
86.19%
(863.6) |
94.91%
(951) |
-
(-) |
|
Internlm2-Chat-7B
训练后(仅GSM8K蒸馏数据) |
-
(-) |
-
(-) |
-
(-) |
72.10%
(951) |
|
Internlm2-Chat-7B
训练后(混合数据) |
39.22%
(393) |
86.22%
(863.9) |
93.71%
(939) |
73.24%
(966) |
使用微调后的模型来搭建RAG文理助手系统:
import lazyllm
from lazyllm import bind
from lazyllm.tools import IntentClassifier
template = "请用下面的文段的原文来回答问题\n\n### 已知文段:{context}\n\n### 问题:{question}\n"
base_model = 'path/to/internlm2-chat-7b-chinese-math2'
base_llm = lazyllm.TrainableModule(base_model)
# 文档加载
documents = lazyllm.Document(dataset_path="path/to/cmrc2018/data_kb")
with lazyllm.pipeline() as ppl:
# 检索组件定义
ppl.retriever = lazyllm.Retriever(doc=documents, group_name="CoarseChunk", similarity="bm25_chinese", topk=3)
ppl.formatter = (lambda nodes, query: template.format(context="".join([node.get_content() for node in nodes]), question=query)) | bind(query=ppl.input)
# 生成组件定义
ppl.llm = base_llm
with IntentClassifier(lazyllm.OnlineChatModule()) as ic:
ic.case['Math', base_llm]
ic.case['Default', ppl]
lazyllm.WebModule(ic, port=23496).start().wait()
视频中的问题来自于GSM8K和CMRC2018的评测集(注意训练集和评测集是完全隔离的!)
更多信息,欢迎移步LazyLLM gzh!