背景
最近我们收到用户反馈,Sentry Web 无法正常刷数据,过一会儿又好了。经过初步排查,发现问题根源在于 ClickHouse 的 CPU 使用率居高不下,甚至达到了 100%,导致系统性能瓶颈。以下是我们对问题的详细分析、解决过程以及后续优化的总结,希望对遇到类似问题的团队有所帮助。
问题现象
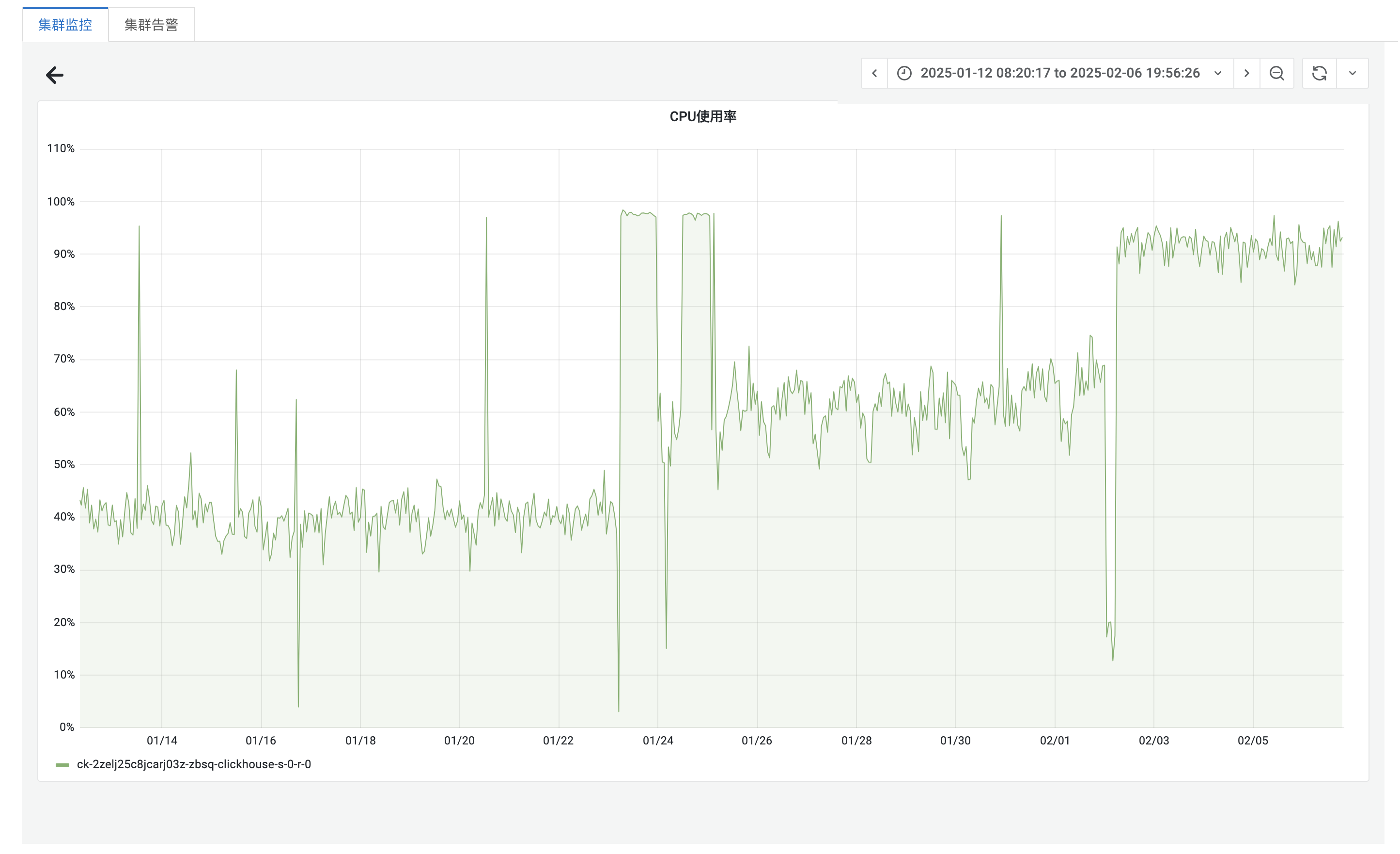
从用户的反馈来看,Sentry Web 数据无法及时刷新,表现为页面加载缓慢甚至无响应。通过监控仪表盘,我们注意到 ClickHouse 的 CPU 使用率异常高,长时间维持在 90%-100% 之间,且 24 小时内变化不明显(如下图所示)。 ![]() 上图显示,CPU 使用率波动在 90%-100% 之间。更值得注意的是,即使在凌晨流量较低的预期的流量波动规律不符。通常情况下,凌晨流量减少时,CPU 使用率应该随之下降,但实际情况并非如此。这让我们初步判断,CPU 高负载可能与流量没有直接关系,而是由其他因素导致。
上图显示,CPU 使用率波动在 90%-100% 之间。更值得注意的是,即使在凌晨流量较低的预期的流量波动规律不符。通常情况下,凌晨流量减少时,CPU 使用率应该随之下降,但实际情况并非如此。这让我们初步判断,CPU 高负载可能与流量没有直接关系,而是由其他因素导致。
原因分析
为了找到 CPU 打满的根本原因,我们从多个维度展开了排查。
1. CPU 使用率趋势与流量无关的初步判断
通过观察 24 小时的 CPU 使用率趋势,我们发现其波动幅度很小,始终维持在 90%-100% 的高水位。即使在凌晨(例如 03:00-05:00)流量较低时,CPU 使用率也没有明显下降。这与我们对流量波动的预期不符,因此我们初步判断,CPU 高负载可能与业务流量没有直接关系,而是由某些后台任务或数据处理逻辑导致。
为了进一步验证这一猜测,我们决定深入分析凌晨时间段的 CPU 使用情况,找出具体消耗 CPU 的查询或操作。
2. 使用 SQL 分析凌晨 CPU 使用情况
我们通过 ClickHouse 的 system.query_log 表,查询了 2025 年 3 月 13 日凌晨 02:42:35 至 04:42:35 的 CPU 使用详情,SQL 如下:
SELECT
type,
`initial_user`,
query,
read_rows,
written_rows,
toDateTime(`event_time`) + INTERVAL 8 HOUR as time,
formatReadableSize(memory_usage) AS memory,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'UserTimeMicroseconds')] AS userCPU,
ProfileEvents.Values[indexOf(ProfileEvents.Names, 'SystemTimeMicroseconds')] AS systemCPU,
query_duration_ms,
normalizedQueryHash(query) AS normalized_query_hash
FROM
system.query_log
WHERE
time >= '2025-03-13 02:42:35'
AND time <= '2025-03-13 04:42:35'
ORDER BY `userCPU` DESC
LIMIT 100
通过查询结果,我们发现 CPU 使用率主要被一类插入操作占据,具体查询如下:
INSERT INTO default.sessions_raw_local FORMAT JSONEachRow
这一插入操作频繁执行,且每次操作的 userCPU 和 systemCPU 消耗都较高。结合上下文,我们推测这一操作可能与 Kafka 的数据消费有关,因为 sessions_raw_local 表通常用于存储从 Kafka 消费的原始会话数据。
3. 排查 TPS 变化与数据行数的对比
在发现 CPU 从 2025 年 1 月 23 日开始被打满时,我们进一步分析了同一时期的其他指标。通过监控数据,我们发现:
- TPS 翻倍:从 1 月 23 日起,ClickHouse 的每秒事务数(TPS)显著增加,翻倍至平均 9.87(如下图所示),而在此之前 TPS 平均为 4.9。
- 写入数据行数无变化 :尽管 TPS 翻倍,但
written_rows(写入行数)指标没有显著变化,表明总的数据量并未增加。
![]() 上图显示,TPS 在 1 月 23 日后急剧上升,而 QPS(每秒查询数)变化较小,这进一步印证了问题可能与插入操作的频率增加有关,而非数据量的增长。
上图显示,TPS 在 1 月 23 日后急剧上升,而 QPS(每秒查询数)变化较小,这进一步印证了问题可能与插入操作的频率增加有关,而非数据量的增长。
4. CPU 使用率趋势与 Kafka 消息堆积的反向关联
结合 TPS 变化,我们进一步分析了 Kafka 的消息堆积情况(如下图),发现其趋势与 CPU 使用率呈现反向关联。
![]()
![]()
从图中可以看到:
- 在 2025 年 1 月 23 日,Kafka 消息堆积到底顶峰,ClickHouse 的 CPU 使用率掉到 10% 以下。
- 1 月 23 日之后,Kafka 消息堆积开始减少,而 ClickHouse 的 CPU 使用率却急剧上升至 100%。
- 1 月 23 日 ~ 2 月 2 日之间,随着消息堆积幅度,Clickhouse 的 CPU 使用率也随着起伏
- 到了 2 月 2 日,Kafka 消息不在堆积,CPU 使用率一直保持高位
5. 关键变更:Sentry-session-consumer 副本数调整
通过进一步排查,我们发现问题的起因与 2025 年 1 月 23 日的一次变更密切相关。当天,Sentry-session-consumer 的消费副本数从 1 增加到 12,目的是提升消费速度,减少 Kafka 消息堆积。然而,这一调整带来了意想不到的后果:
- 副本数增加导致 TPS 激增 :副本数的增加使得
INSERT INTO default.sessions_raw_local FORMAT JSONEachRow 操作的频率显著上升,尽管总的写入数据量(written_rows)未变,但 TPS 翻倍直接推高了 CPU 负载。
- 后台 Merge 负担加重:ClickHouse 的 MergeTree 引擎需要频繁合并数据分片以保持查询性能。TPS 的增加导致后台 Merge 操作的负担加重,进而导致 CPU 使用率飙升至 90%-100%。
2 月 2日后,看消息不在堆积,Sentry-session-consumer 的消费副本从 12 个副本缩到 2 个副本
6. 根本原因总结
通过以上分析,我们得出结论:
- 凌晨 CPU 高负载的原因 :即使在流量低谷时,
INSERT INTO default.sessions_raw_local FORMAT JSONEachRow 操作仍然频繁执行,导致 CPU 使用率居高不下。这与 Sentry-session-consumer 的消费逻辑直接相关。
- TPS 翻倍的影响:1 月 23 日副本数从 1 增加到 12,导致 TPS 翻倍,尽管写入数据行数未变,但频繁的插入操作显著增加了 ClickHouse 的 Merge 负担,最终使得 CPU 使用率飙升。2 月 2 日副本数从 12 缩减到 2 个后,还是比之前的 TPS 高,导致 CPU 使用率一直维持高位。
解决方案
为了解决 CPU 打满的问题,我们采取了以下措施:
- 调整 Sentry-session-consumer 副本数:将副本数从 2 进一步降低至 1,通过减少副本数,尽量让数据以批量的形式发送,降低总的 TPS 数量,从而减轻 ClickHouse 的 Merge 压力。
调整后的效果非常显著。如下图所示,ClickHouse 的 CPU 使用率下降了大约 40%,稳定在 50%-60% 的区间,系统性能恢复正常,Sentry Web 的数据刷新问题也随之解决。 ![]()
后续优化与反思
尽管问题得到了解决,但整个排查过程耗费了大量时间,主要原因在于:
- 问题发现不及时:由于缺乏有效的 CPU 使用率告警机制,我们未能第一时间发现 1 月 23 日副本数调整带来的异常。从问题发生,到博主排查,已经过去了 1.5个月。期间肯定也影响用户使用了,但是还没到无法容忍的地步
- 上下文复杂:该 ClickHouse 实例的使用方众多,涉及多个团队,排查时需要协调大量信息,增加了难度。
- 凌晨 CPU 高负载的误判:我们最初认为 CPU 使用率会随流量波动,但实际与 Kafka 消费逻辑和 TPS 增加相关,这一误判延长了排查时间。
为了避免类似问题再次发生,我们采取了以下改进措施:
- 补充 CPU 使用率告警:在 Prometheus 监控系统中为 ClickHouse 的 CPU 使用率设置告警规则,确保异常情况能够及时通知到。
- 优化变更管理:在进行类似副本数调整的变更时,提前评估对下游系统(ClickHouse)的潜在影响,并实时监控关键指标。
总结
ClickHouse 作为高性能的分析型数据库,对 TPS 和 Merge 负载非常敏感。在调整上游消费者(如 Sentry-session-consumer)时,必须综合考虑对下游数据库的潜在影响。
- 关键教训 :
- TPS 的增加可能对 ClickHouse 的 Merge 负担产生显著影响,进而导致 CPU 打满,即使写入数据行数未变。
- CPU 使用率不一定与业务流量直接相关,需结合
system.query_log 和 TPS 指标深入分析。
- 解决思路:通过减少 TPS(如降低消费者副本数、优化批处理)可以有效缓解 ClickHouse 的压力。
- 预防措施:完善的监控告警和变更评估机制是避免类似问题的关键。
希望这篇总结能为其他团队提供参考。如果你在使用 ClickHouse 或类似系统中遇到过类似问题,欢迎留言交流!
 上图显示,CPU 使用率波动在 90%-100% 之间。更值得注意的是,即使在凌晨流量较低的预期的流量波动规律不符。通常情况下,凌晨流量减少时,CPU 使用率应该随之下降,但实际情况并非如此。这让我们初步判断,CPU 高负载可能与流量没有直接关系,而是由其他因素导致。
上图显示,CPU 使用率波动在 90%-100% 之间。更值得注意的是,即使在凌晨流量较低的预期的流量波动规律不符。通常情况下,凌晨流量减少时,CPU 使用率应该随之下降,但实际情况并非如此。这让我们初步判断,CPU 高负载可能与流量没有直接关系,而是由其他因素导致。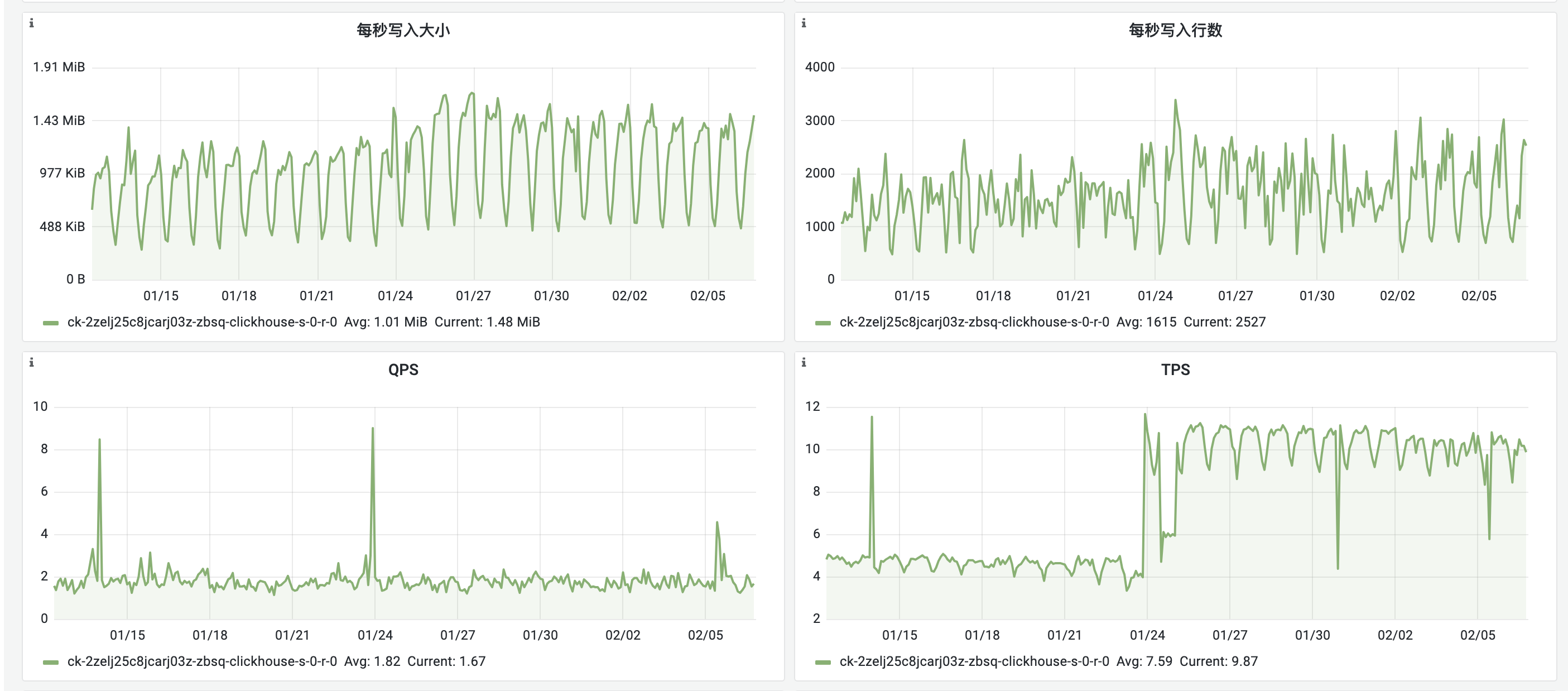 上图显示,TPS 在 1 月 23 日后急剧上升,而 QPS(每秒查询数)变化较小,这进一步印证了问题可能与插入操作的频率增加有关,而非数据量的增长。
上图显示,TPS 在 1 月 23 日后急剧上升,而 QPS(每秒查询数)变化较小,这进一步印证了问题可能与插入操作的频率增加有关,而非数据量的增长。