![]()
随着物联网 (IoT)、工业自动化、智能能源等领域的迅猛发展,数据量呈现爆炸式增长。如何高效管理这些时序数据并实现实时监控,已成为各行业面临的关键挑战。Datalayers 作为一款专为工业 IoT 和连接车辆等场景优化的时序数据库,提供了强大的分布式存储和计算能力。而通过与Grafana 的集成,用户可以将这些复杂的时序数据以可视化的形式呈现出来,帮助实现实时数据洞察。
本文将介绍如何将 Datalayers 与 Grafana 集成,以实现数据存储、可视化,以下是具体的集成步骤:
我们将以手动配置和零配置两种方式进行介绍。
Datalayers 支持多种安装方式,具体安装请参考官方文档。
此处我们以 Ubuntu 操作系统、amd64 平台为例,先下载对应平台的deb安装包。
安装完成后,可以通过我们提供的命令行工具写入一些示例数据:
首先,通过以下命令连接到数据库:
dlsql -u admin -p public
然后创建一个示例数据库:
create database demo;
再创建一个表:
CREATE TABLE demo.sensor_info (
ts TIMESTAMP(9) NOT NULL DEFAULT CURRENT_TIMESTAMP,
sn STRING,
speed DOUBLE,
temperature DOUBLE,
timestamp KEY (ts))
PARTITION BY HASH(sn) PARTITIONS 8
ENGINE=TimeSeries
with (ttl='10d');
写入一些示例数据,当然为了数据更丰富,你可以多写入一点随机数据:
INSERT INTO sensor_info(sn, speed, temperature) VALUES('100', 22.12, 30.8), ('101', 34.12, 40.6), ('102', 56.12, 52.3);
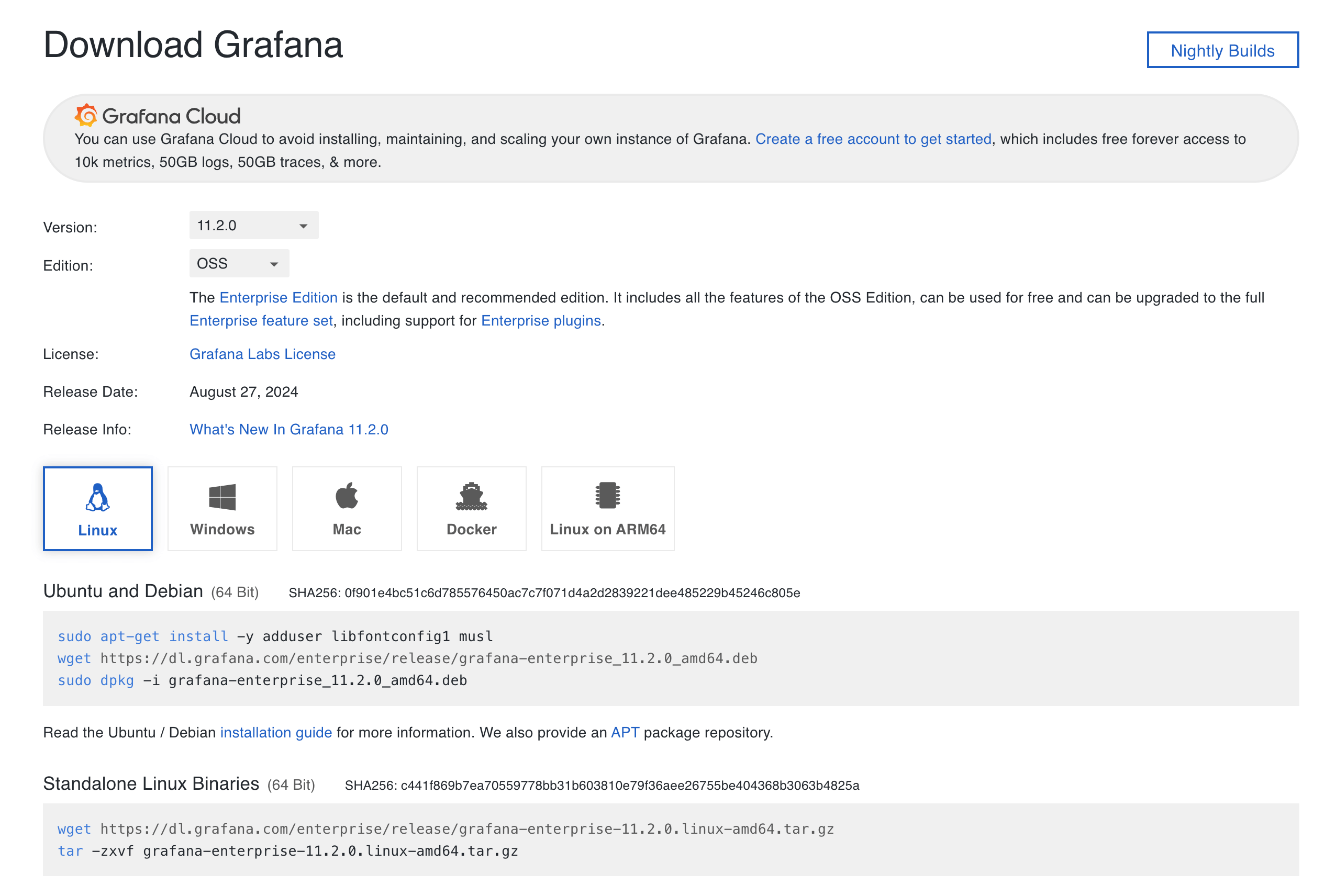
目前 Datalayers 支持 Grafana >=9.2.5 版本。请前往Grafana 官网下载页。
此处我们下载并安装 Linux 的 开源版本 11.2.0:
![download grafana]()
更多安装方法详见官方文档。
为了让 Grafana 能够连接到我们的 Datalayers 数据库服务以便进行读写操作,需要额外安装 Datalayers 插件。
请注意,安装插件建议先停止你的 Grafana 服务,安装完成后重新启动 Grafana 服务。
此处使用我们提供的一个脚本来快速安装插件:
bash -c "$(curl -fsSL \
https://raw.githubusercontent.com/datalayers-io/grafana-datalayers-datasource/main/install.sh)" -- \
-h localhost:8360 \
-u admin \
-p public
注:参数 -h 为地址和端口, -u 为用户名,-p 为密码,请根据实际情况修改。
更多安装方法详见官方文档
安装完成后,重新启动 Grafana 服务,然后通过本地浏览器访问你的 Grafana 服务,通常是默认的3000端口。
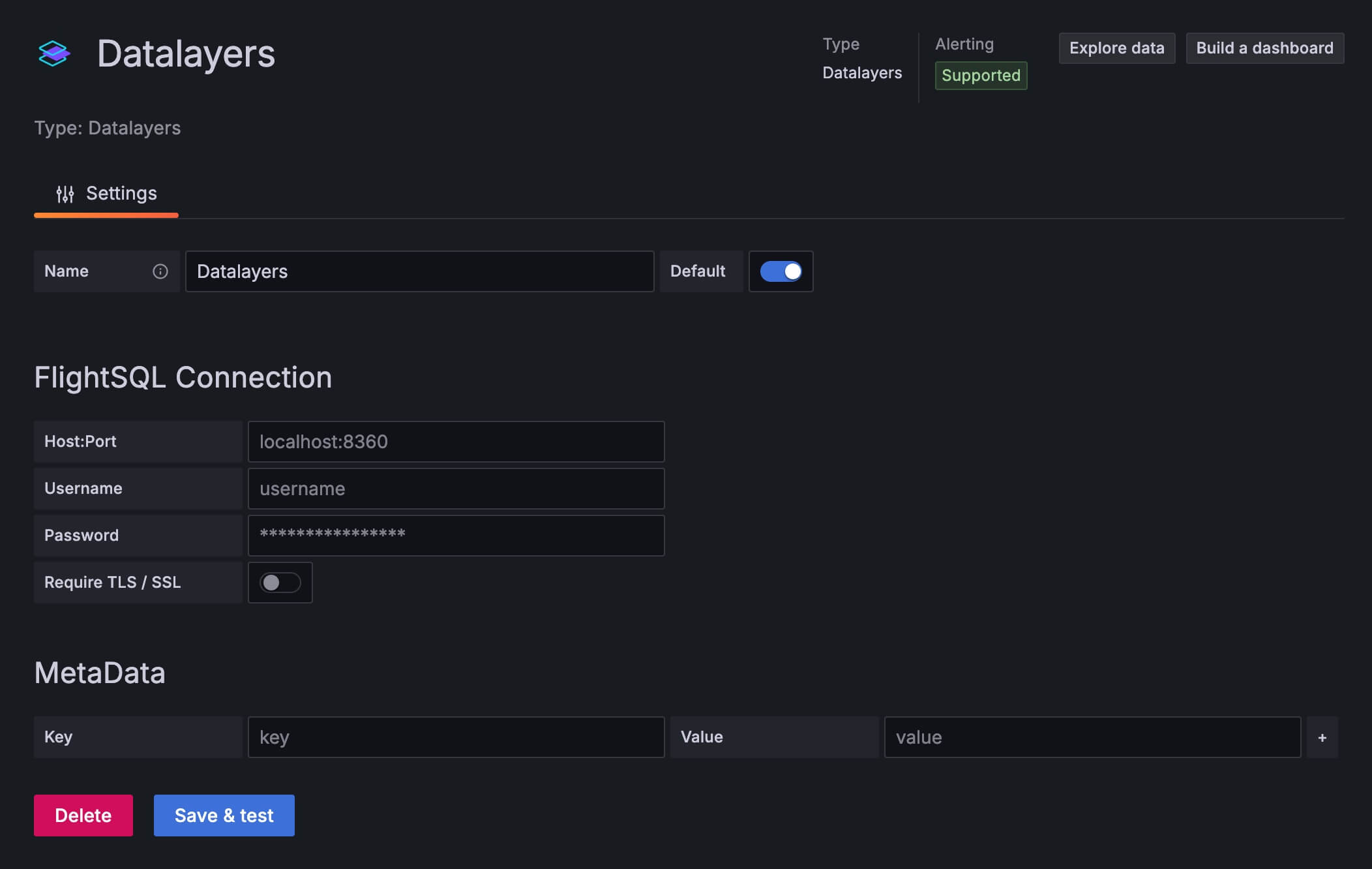
此时 Grafana 和 Datalayers 数据源插件均已就绪。请按照下方图示填入对应的数据库地址+端口、用户名+密码,如果开启了 TLS 还需要填写证书。
![config plugin]()
推荐填写 metaData 部分,key 为'database',value 为'数据库名称',填写后在使用查询语句时可以免写数据库名。
配置完成后,你可以点击Save & test按钮保存并测试连通性。
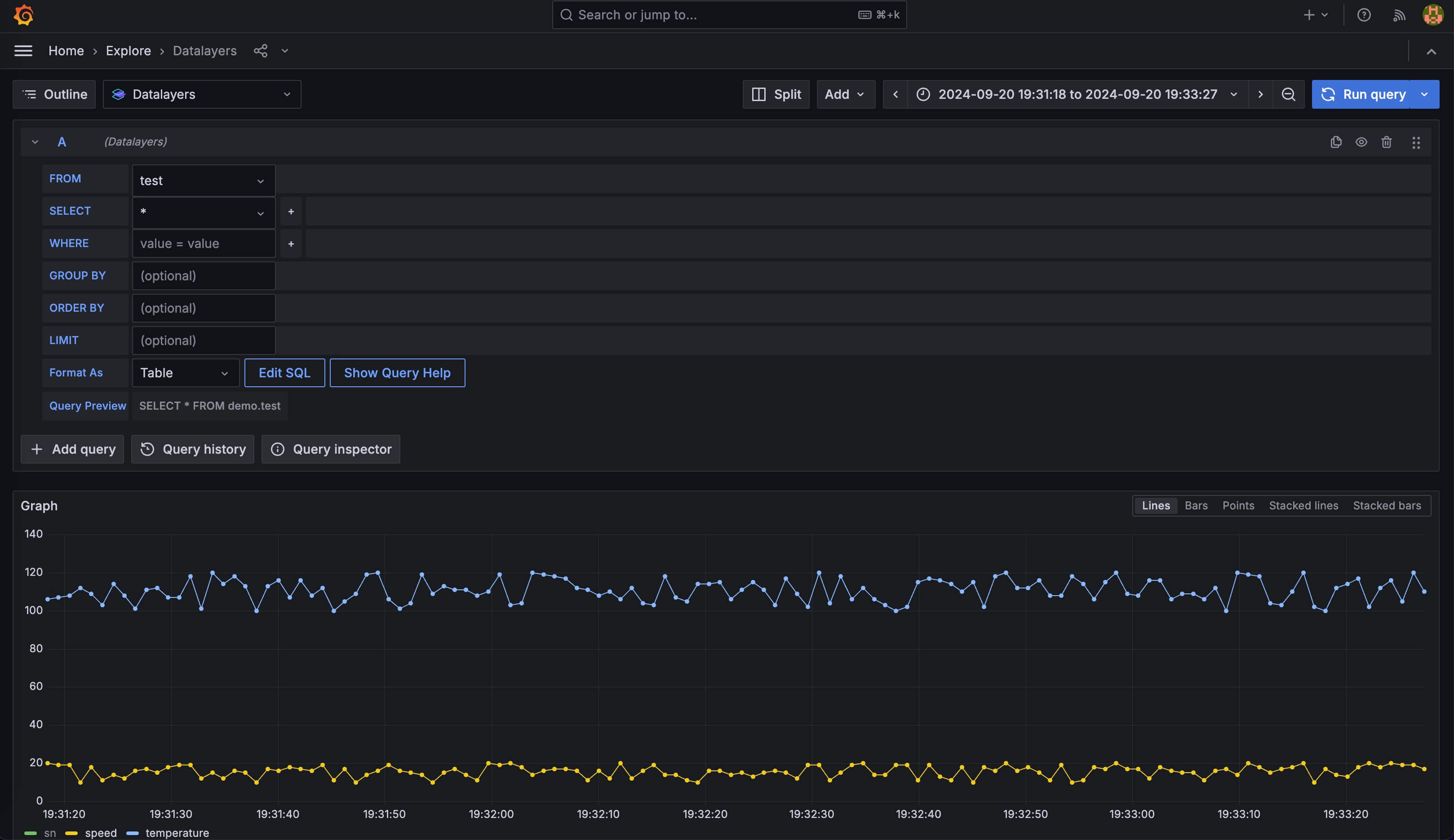
我们之前已经写入了一些示例数据,你可以通过 Datalayers 数据源插件进行一些查询。
![select all]()
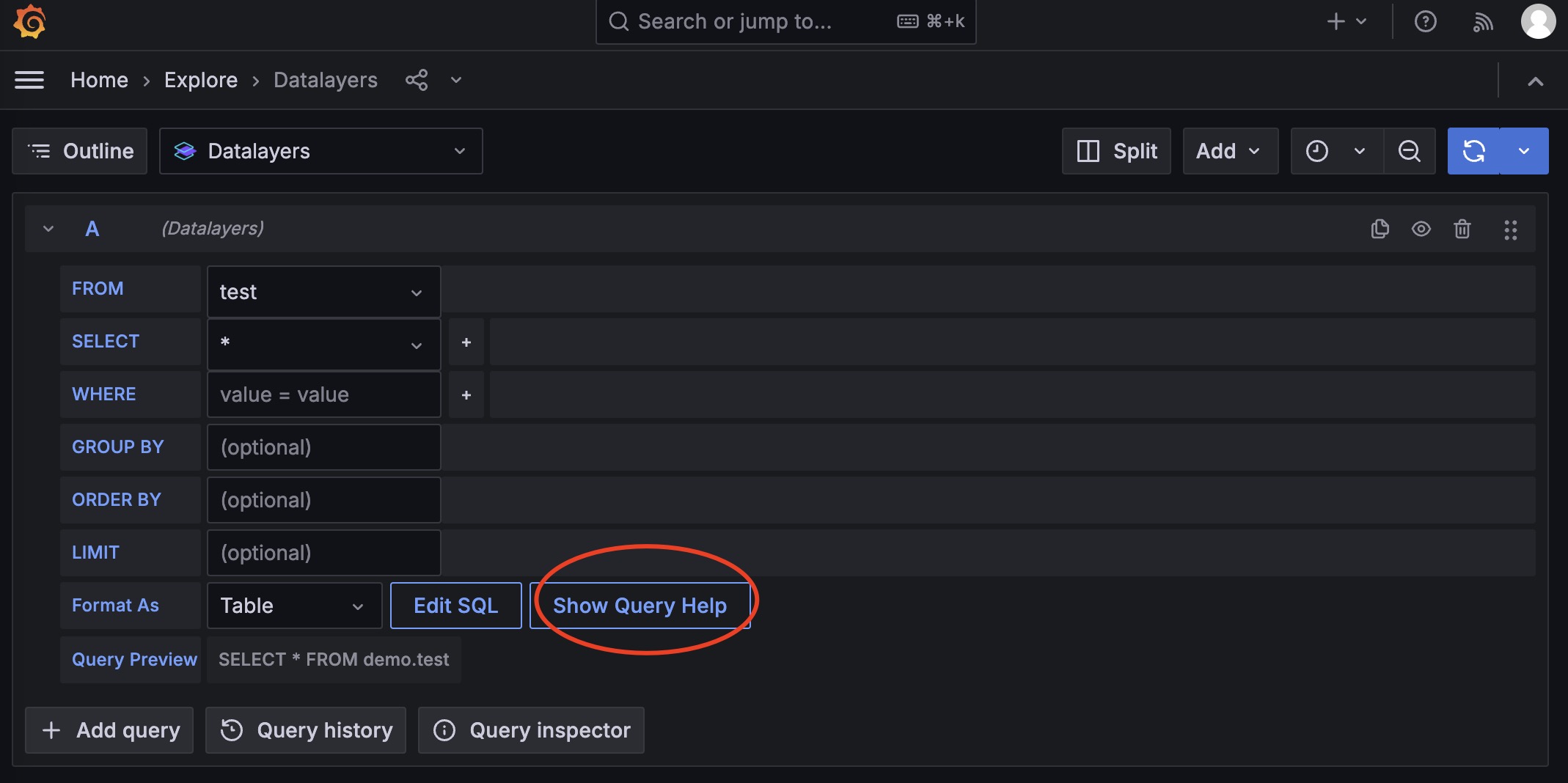
图中使用Home - Explore面板查询数据,使用默认的界面模式试图拼出select * from demo.test这样的查询语句。
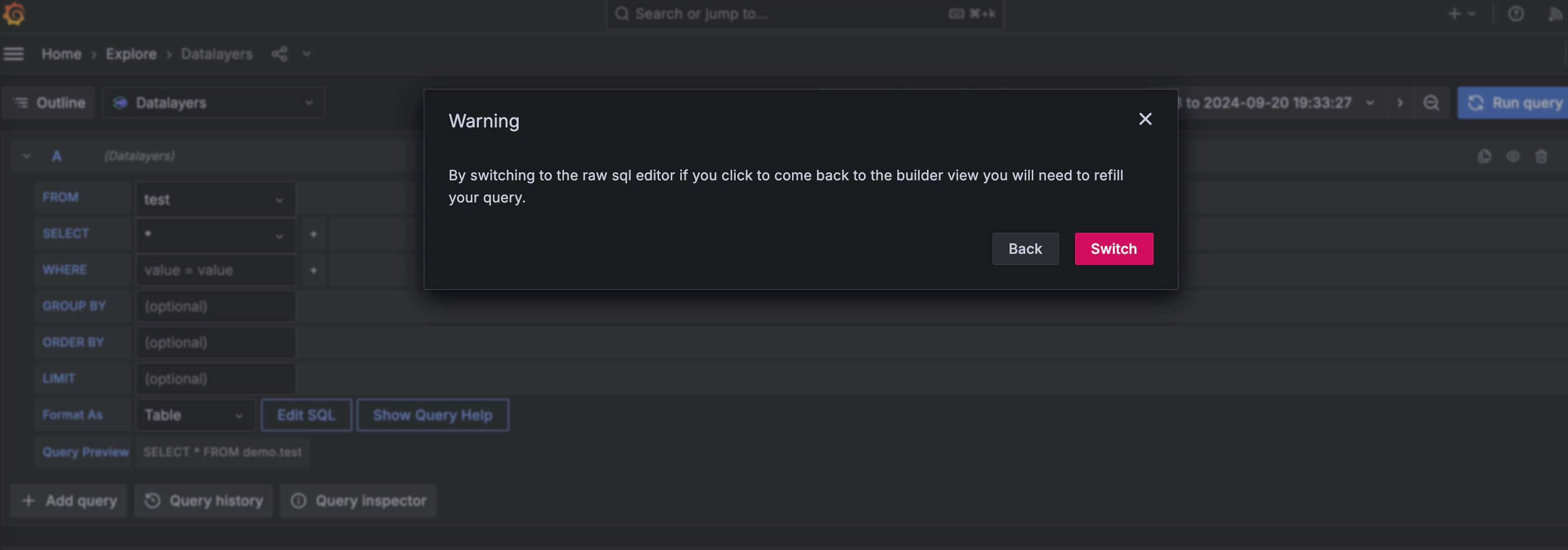
当然也可以切换到 SQL 编辑器模式,编写更复杂的查询语句。
![select data use sql-editor]()
你也可以使用函数对数据进行聚合等操作,详见SQL函数。
在插件的编辑器模式中,你可以使用一些 Grafana 变量,请点击帮助按钮查看:
![help button]()
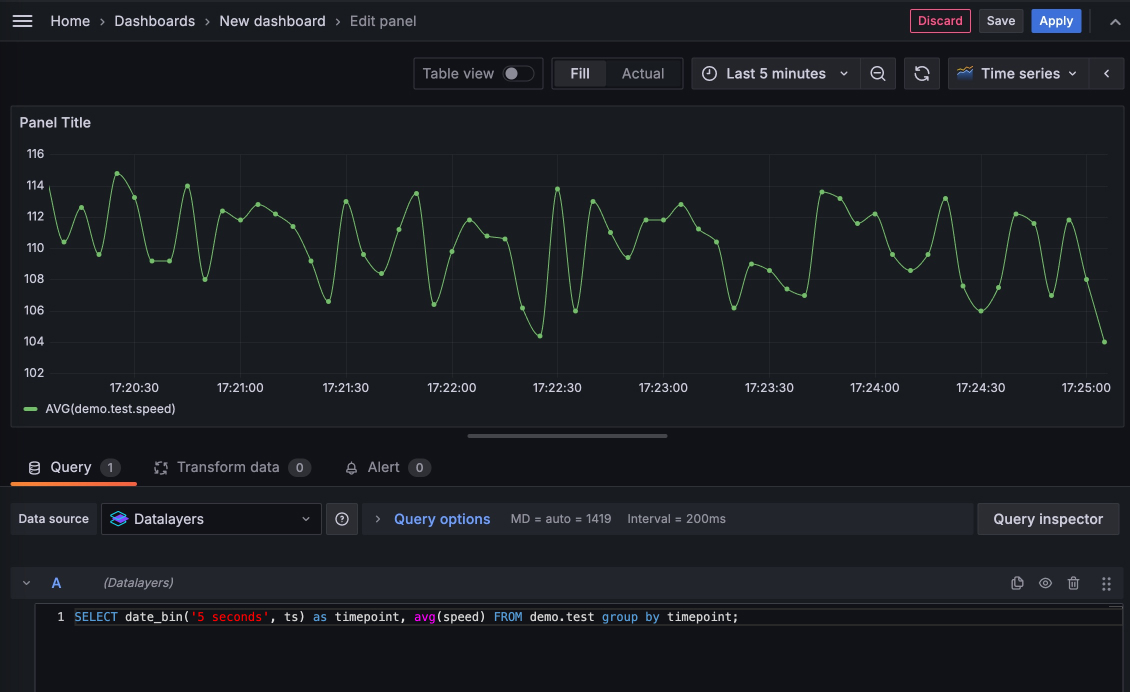
现在,你也可以使用Grafana - Dashboards功能开始添加一个 Dashboard,如下图:
![select data use sql-editor]()
在此界面可进行更精细的调整,调整完成后可以点击Apply应用这个Panel,当你添加了较多的Panel,就可以通过 Grafana 强大的自定义编辑功能组合成一个丰富的 Dashboard。
如果你想免去安装和配置 Datalayers 与 Grafana,可以通过我们提供的 docker compose 零配置快速体验。
首先你需要拉取这个开源项目。 它使用 Docker 将 Datalayers、Datalayers 对应的镜像整合到一个 docker-compose 文件中,这样可以快速启动这些服务。
git clone https://github.com/datalayers-io/datalayers-with-grafana.git
然后请跟随 README 文档完成启动、快速写入示例数据的过程。
当你完成上述步骤后,就已经自动完成了上述所有的安装、配置、写入示例数据步骤,你可以直接进行数据查询、添加 Dashboard 相关操作。
将 Datalayers 与 Grafana 集成,不仅能够大幅提升时序数据的管理与分析效率,还能通过灵活的可视化工具为用户提供更加直观的业务洞察。无论是在工业 IoT 还是智能能源等领域,Datalayers 与 Grafana 的结合都能帮助企业实现数据驱动的决策和优化,推动业务智能化转型。
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接:https://datalayers.cn/blog/datalayers-with-grafana