检索器(retrievers)是 Elasticsearch 中搜索 API 中添加的新抽象层。它们提供了在单个 _search API 调用中配置多阶段检索管道的便利。此架构通过消除对复杂搜索查询的多个 Elasticsearch API 调用的需求,简化了应用程序中的搜索逻辑。它还减少了对客户端逻辑的需求,而客户端逻辑通常需要组合来自多个查询的结果。
![]()
Retrivers
检索器是 8.14.0 版中添加到搜索 API 中的抽象,并在 8.16.0 版中正式推出。此抽象允许在单个 _search 调用中配置多阶段检索管道。这简化了你的搜索应用程序逻辑,因为你不再需要通过多个 Elasticsearch 调用来配置复杂的搜索,也不再需要实现额外的客户端逻辑来组合来自不同查询的结果。
检索器类型
检索器有多种类型,每种类型都针对不同的搜索操作量身定制。目前可用的检索器如下:
- 标准检索器(Standard Retriver)。从传统查询返回顶级文档。模仿传统查询(query),但在检索器框架的上下文中。这确保了向后兼容性,因为现有的 _search 请求仍然受支持。这样,你可以按照自己的节奏过渡到新的抽象,而无需混合语法。
- kNN 检索器(Knn Retriver)。在检索器框架的上下文中,从 knn 搜索(knn search)返回顶级文档。
- RRF 检索器(RRF Retriver)。使用倒数排序融合 (RRF) 算法组合和排名多个第一阶段检索器。允许你将具有不同相关性指标的多个结果集组合成一个结果集。RRF 检索器是一种复合检索器,其过滤元素会传播到其子检索器。
- 文本相似性重新排序器检索器(Text Similarity Re-ranker Retriever)。用于语义重新排序(semantic reranking)。需要首先使用 Elasticsearch 推理 API 创建重新排序任务。
是什么让检索器变得有用?
以下概述了是什么让检索器变得有用以及它们与常规查询有何不同。
- 简化的用户体验。检索器通过允许在单个 API 调用中配置整个检索管道来简化用户体验。这通过自动将它们转换为适当的检索器来保持与传统查询元素的向后兼容性。
- 结构化检索。检索器提供了一种更结构化的方式来定义搜索操作。它们允许使用 “检索器树” 来描述搜索,这是一种层次结构,可以阐明操作的顺序和逻辑,使复杂的搜索更易于理解和管理。
- 可组合性和灵活性。检索器支持灵活的可组合性,允许你构建管道并将不同的检索策略无缝集成到这些管道中。检索器可以轻松测试不同的检索策略组合。
- 复合操作。检索器可以有子检索器。这允许复杂的嵌套搜索,其中一个检索器的结果输入到另一个检索器中,支持可能涉及多个阶段或条件的复杂查询策略。
- 检索是一流概念。与传统查询不同,传统查询是大型搜索 API(Search API) 调用的一部分,而检索器被设计为独立实体,可以组合或单独使用。这使得构建搜索的方法更加模块化和灵活。
- 增强对文档评分和排名的控制。检索器允许更明确地控制文档的评分和筛选方式。例如,你可以指定最低分数阈值,应用复杂的筛选器而不影响评分,并使用诸如 terminate_after 之类的参数进行性能优化。
- 与现有 Elasticsearch 功能集成。尽管可以使用检索器代替现有的 _search API 语法(如 query 和 knn),但它们旨在与分页(search_after)和排序等无缝集成。它们还通过将所有叶检索器的组合视为布尔查询中的 should 子句来保持与聚合操作的兼容性。
- 更清晰的关注点分离。使用复合检索器时,只允许查询元素,这可以强制更清晰地分离关注点并防止过度嵌套或相互依赖的配置可能产生的复杂性。
示例
以下示例演示了如何使用检索器简化 RRF 排名查询的可组合性。
GET example-index/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"sparse_vector": {
"field": "vector.tokens",
"inference_id": "my-elser-endpoint",
"query": "What blue shoes are on sale?"
}
}
}
},
{
"standard": {
"query": {
"match": {
"text": "blue shoes sale"
}
}
}
}
]
}
}
}
此示例演示如何将不同的检索策略组合到单个检索器管道中。
Retriver
检索器(retriever)是一种规范,用于描述从搜索中返回的顶部文档。检索器取代了搜索 API(search API) 中其他也能返回顶部文档的元素,例如查询(query)和近邻搜索(knn)。检索器可以拥有子检索器,其中具有两个或更多子检索器的检索器被视为复合检索器(compound retriever)。这允许通过树状结构(称为检索器树)来描述复杂的行为,以更清晰地展示搜索过程中发生的操作顺序。
可用的检索器如下:
- standard
- knn
- rrf
- text_similarity_reranker
- 使用机器学习模型,根据与指定推理文本的语义相似性对文档进行重新排名,从而增强搜索结果的检索器。
标准检索器 - standard retriever
标准检索器返回传统查询(query)中的顶级文档。
参数:
参数
| 参数 |
描述 |
| query |
(可选,查询对象/ query object)
定义查询以检索一组顶级文档。 |
| filter |
(可选,查询对象/query object或查询对象列表/list of query objects)
将布尔查询过滤器应用于此检索器,其中所有文档必须与此查询匹配但不计入分数。 |
| search_after |
(可选,search after 对象)
定义用于分页的对象搜索参数。 |
| terminate_after |
(可选,整数)每个分片可收集的最大文档数。如果查询达到此限制,Elasticsearch 将提前终止查询。Elasticsearch 在排序之前收集文档。
重要:请谨慎使用。Elasticsearch 将此参数应用于处理请求的每个分片。如果可能,请让 Elasticsearch 自动执行提前终止。避免为针对跨多个数据层的支持索引的数据流的请求指定此参数。 |
| sort |
(可选,sort 对象)指定匹配文档顺序的排序对象。 |
| min_score |
(可选,浮点数)
匹配文档的最低 _score。 _score 较低的文档不包含在顶级文档中。 |
| collapse |
(可选,collaps 对象)
按指定键将顶部文档折叠为每个键的单个顶部文档 |
限制
当检索器树包含复合检索器(具有两个或多个子检索器的检索器)时,不支持参数 search after 的搜索。
示例
GET /restaurants/_search
{
"retriever": { /* 1 */
"standard": { /* 2 */
"query": { /* 3 */
"bool": { /* 4 */
"should": [ /* 5 */
{
"match": { /* 6 */
"region": "Austria"
}
}
],
"filter": [ /* 7 */
{
"term": { /* 8 */
"year": "2019" /* 9 */
}
}
]
}
}
}
}
}
- 打开 retriever 对象。
- standard 检索器用于定义传统的 Elasticsearch 查询。
- 定义搜索查询的入口点。
- bool 对象允许逻辑地组合多个查询子句。
- should 数组指示文档匹配的条件。符合这些条件的文档将增加其相关性得分。
- match 对象查找区域字段包含单词 “Austria” 的文档。
- filter 数组提供必须满足但不会影响相关性得分的过滤条件。
- term 对象用于精确匹配,在本例中,按 year 字段过滤文档。
- year 字段中要匹配的精确值。
kNN 检索器 - kNN retriever
kNN 检索器返回来自 k 最近邻搜索 (kNN) 的顶级文档。
参数
参数
| 参数 |
描述 |
| field |
(必需,字符串)
要搜索的向量字段的名称。必须是启用了索引(ndexing enabled)的密集向量(dense_vector)字段 |
| query_vector |
(如果未定义 query_vector_builder,则为必需,浮点数组)
查询向量。必须具有与搜索的向量字段相同的维数。必须是浮点数组或十六进制编码的字节向量 |
| query_vector_builder |
(如果未定义 query_vector,则为必需,查询向量构建器对象)
定义一个模型(model)来构建查询向量。 |
| k |
(必填,整数)
作为热门匹配返回的最近邻居的数量。此值必须小于或等于 num_candidates。 |
| num_candidates |
(必需,整数)
每个分片要考虑的最近邻候选数。需要大于 k,如果省略 k,则为 size,但不能超过 10,000。Elasticsearch 从每个分片收集 num_candidates 个结果,然后合并它们以找到前 k 个结果。增加 num_candidates 往往会提高最终 k 个结果的准确性。默认为 Math.min(1.5 * k, 10_000)。 |
| filter |
(可选,查询对象/query object或查询对象列表/list of query objects)
查询以过滤可匹配的文档。kNN 搜索将返回也符合此过滤器的前 k 个文档。该值可以是单个查询或查询列表。如果未提供过滤器,则允许所有文档匹配。 |
| similarity |
(可选,浮点数)
文档被视为匹配所需的最小相似度。计算出的相似度值(similarity)与使用的原始相似度有关。而不是文档分数。然后根据相似度对匹配的文档进行评分,并应用提供的提升。
相似度参数是直接向量相似度计算。
- l2_norm:也称为欧几里得,将包括向量位于 dims 维超球面内的文档,其半径相似度与 query_vector 的原点相似。
- cosine、dot_product 和 max_inner_product:仅返回余弦相似度或点积至少为提供的相似度的向量。更多描述,请参阅文章。
|
限制
query_vector 和 query_vector_builder 参数不能一起使用。
示例
GET /restaurants/_search
{
"retriever": {
"knn": { /* 1 */
"field": "vector", /* 2 */
"query_vector": [10, 22, 77], /* 3 */
"k": 10, /* 4 */
"num_candidates": 10 /* 5 */
}
}
}
- 基于向量相似性的 k-最近邻 (knn) 搜索的配置。
- 指定包含向量的字段名称。
- 在 knn 搜索中与文档向量进行比较的查询向量。
- 作为顶级匹配返回的最近邻居的数量。此值必须小于或等于 num_candidates。
- 从中选择最终 k 个最近邻居的初始候选集的大小。
RRF 检索器 - RRF retriever
RRF 检索器根据 RRF 公式返回排名靠前的文档,对两个或多个子检索器赋予同等权重。倒数排序融合 (RRF) 是一种将具有不同相关性指标的多个结果集组合成单个结果集的方法。有关 RRF 的更多描述,请参阅文章 “Elasticsearch:倒数排序融合 - Reciprocal rank fusion (RRF)”。
参数
参数
| 参数 |
描述 |
| retrievers |
(必需,检索器对象数组)
子检索器列表,用于指定哪些返回的顶级文档集将应用 RRF 公式。每个子检索器作为 RRF 公式的一部分具有相等的权重。需要两个或更多个子检索器。 |
| rank_constant |
(可选,整数)
此值决定每个查询中单个结果集中的文档对最终排名结果集的影响程度。值越高,排名越低的文档影响力越大。此值必须大于或等于 1。默认为 60。 |
| rank_window_size |
(可选,整数)
此值决定每个查询的单个结果集的大小。较高的值将提高结果相关性,但会降低性能。最终排名的结果集将缩减为搜索请求的 size。rank_window_size 必须大于或等于 size 且大于或等于 1。默认为 size 参数。 |
| filter |
(可选,查询对象/query object或查询对象列表/list of query objects)
根据每个检索器的规范,将指定的布尔查询过滤器应用于所有指定的子检索器。 |
示例:混合搜索
一个简单的混合搜索示例(词汇搜索 + 密集向量搜索),使用 RRF 将标准检索器与 knn 检索器相结合:
GET /restaurants/_search
{
"retriever": {
"rrf": { /* 1 */
"retrievers": [ /* 2 */
{
"standard": { /* 3 */
"query": {
"multi_match": {
"query": "Austria",
"fields": [
"city",
"region"
]
}
}
}
},
{
"knn": { /* 4 */
"field": "vector",
"query_vector": [10, 22, 77],
"k": 10,
"num_candidates": 10
}
}
],
"rank_constant": 1, /* 5 */
"rank_window_size": 50
}
}
}
- 定义带有 RRF 检索器的检索器树。
- 子检索器数组。
- 第一个子检索器是 standard 检索器。
- 第二个子检索器是 knn 检索器。
- RRF 检索器的 rank 常量。
- RRF 检索器的 rank 窗口大小。
示例:使用稀疏向量的混合搜索
使用 RRF 的更复杂的混合搜索示例(词汇搜索 + ELSER 稀疏向量搜索 + 密集向量搜索):
GET movies/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"sparse_vector": {
"field": "plot_embedding",
"inference_id": "my-elser-model",
"query": "films that explore psychological depths"
}
}
}
},
{
"standard": {
"query": {
"multi_match": {
"query": "crime",
"fields": [
"plot",
"title"
]
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [10, 22, 77],
"k": 10,
"num_candidates": 10
}
}
]
}
}
}
文本相似性重排检索器 - Text Similarity Re-ranker Retriever
text_similarity_reranker 检索器使用 NLP 模型,通过根据与查询的语义相似性对前 k 个文档进行重新排序来改进搜索结果。
先决条件
要使用 text_similarity_reranker,你必须首先使用 Create inference API 设置重新排名/rerank 任务。重新排名任务应使用可以计算文本相似度的机器学习模型进行设置。请参阅 Elastic NLP 模型参考,了解 Elasticsearch 支持的第三方文本相似度模型列表。
目前你可以:
参数
参数
| 参数 |
描述 |
| retriever |
(必需,检索器)
生成要重新排序的初始顶级文档集的子检索器。 |
| field |
(必需,字符串)
用于文本相似性比较的文档字段。此字段应包含将根据 inference_text 进行评估的文本。 |
| inference_id |
(必需,字符串)
使用推理 API 创建的推理端点的唯一标识符。 |
| inference_text |
(必需,字符串)
用作相似性比较依据的文本片段。 |
| rank_window_size |
(可选,整数)
重新排序过程中要考虑的顶级文档数量。默认为 10。 |
| min_score |
(可选,浮点数)
设置将文档纳入重新排序结果的最低阈值分数。相似度分数低于此阈值的文档将被排除。请注意,分数计算因所用模型而异。 |
| filter |
(可选,查询对象/query object或查询对象列表/list of query objects)
将指定的布尔查询过滤器(boolean query filter)应用于子检索器。如果子检索器已指定任何过滤器,则此顶级过滤器将与子检索器中定义的过滤器一起应用。 |
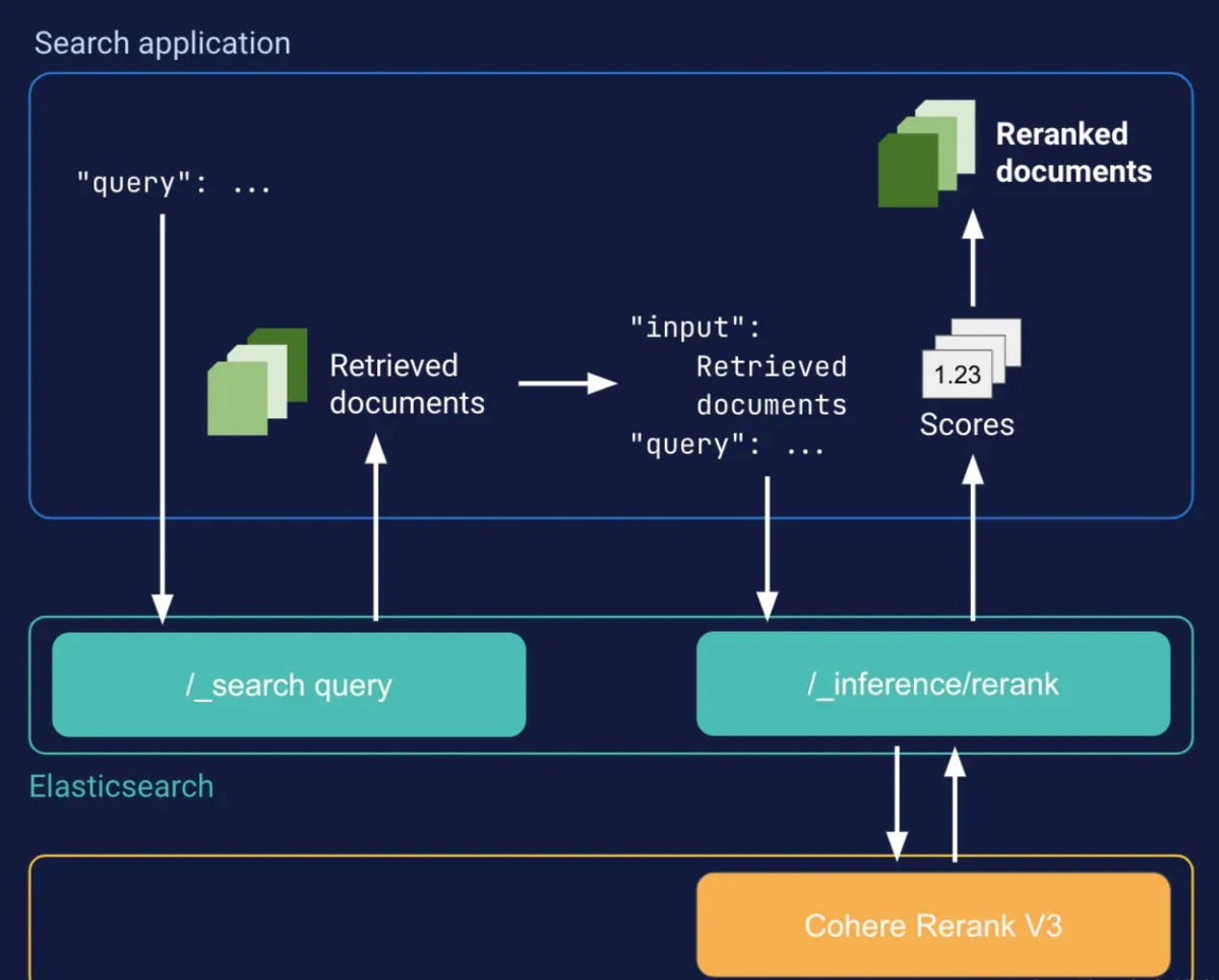
示例:Cohere Rerank
此示例通过使用 Cohere Rerank API 对顶级文档进行重新排名,实现了开箱即用的语义搜索。此方法无需为所有索引文档生成和存储嵌入。这需要使用 rerank 任务类型的 Cohere Rerank 推理端点。
GET /index/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"match_phrase": {
"text": "landmark in Paris"
}
}
}
},
"field": "text",
"inference_id": "my-cohere-rerank-model",
"inference_text": "Most famous landmark in Paris",
"rank_window_size": 100,
"min_score": 0.5
}
}
}
示例:使用 Hugging Face 模型进行语义重新排序
以下示例使用 Hugging Face 的 cross-encoder/ms-marco-MiniLM-L-6-v2 模型根据语义相似性对搜索结果进行重新排序。必须使用 Eland 将模型上传到 Elasticsearch。
提示:请参阅 Elastic NLP 模型参考,了解 Elasticsearch 支持的第三方文本相似度模型列表。
按照以下步骤加载模型并创建语义重新排序器。
1)使用 pip 安装 Eland
python -m pip install eland[pytorch]
2)使用 Eland 将模型上传到 Elasticsearch。此示例假设你拥有 Elastic Cloud 部署和 API 密钥。请参阅 Eland 文档了解更多身份验证选项。
eland_import_hub_model \
--cloud-id $CLOUD_ID \
--es-api-key $ES_API_KEY \
--hub-model-id cross-encoder/ms-marco-MiniLM-L-6-v2 \
--task-type text_similarity \
--clear-previous \
--start
3)为 rerank 任务创建推理端点
PUT _inference/rerank/my-msmarco-minilm-model
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": "cross-encoder__ms-marco-minilm-l-6-v2"
}
}
4)定义一个 text_similarity_rerank 检索器。
POST movies/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"match": {
"genre": "drama"
}
}
}
},
"field": "plot",
"inference_id": "my-msmarco-minilm-model",
"inference_text": "films that explore psychological depths"
}
}
}
该检索器使用 standard match 查询在 movie 索引中搜索标记为 “drama” 类型的电影。然后,它使用我们上传到 Elasticsearch 的模型,根据与 inference_text 参数中的文本的语义相似性对结果进行重新排序。
更多阅读,请参阅文章 “使用 HuggingFace 提供的 Elasticsearch 托管交叉编码器进行重新排名”。
在检索器树中使用 from 和 size
from 和 size 参数作为通用 search API 的一部分全局提供。它们适用于检索器树中的所有检索器,除非特定检索器使用其他参数(例如 rank_window_size)覆盖 size 参数。不过,最终的搜索结果始终受限于 size。
使用带有检索器树的聚合
聚合是作为搜索请求的一部分全局指定的。用于聚合的查询是所有叶检索器的组合,就像布尔查询(boolean query)中的 should 子句一样。
指定检索器时对搜索参数的限制
当将检索器指定为搜索的一部分时,以下元素不允许出现在顶层,而只能作为特定检索器的元素:
检索器示例
在这些动手示例中了解如何组合不同的检索器。为了展示检索器的全部功能,这些示例需要访问使用 Elastic inference APIs 设置的语义重新排名模型( semantic reranking model)。
添加示例数据
首先,我们将设置必要的服务并将它们准备好以供日后使用。
// Setup rerank task stored as `my-rerank-model`
PUT _inference/rerank/my-rerank-model
{
"service": "cohere",
"service_settings": {
"model_id": "rerank-english-v3.0",
"api_key": "{
{COHERE_API_KEY}}"
}
}
如你还不知道如何获得这个 COHERE_API_KEY,请参阅文章 “将 Cohere 与 Elasticsearch 结合使用”。
![]()
现在我们已经有了重新排名服务,让我们创建 retrievers_example 索引,并向其中添加一些文档。
PUT retrievers_example
{
"mappings": {
"properties": {
"vector": {
"type": "dense_vector",
"dims": 3,
"similarity": "l2_norm",
"index": true
},
"text": {
"type": "text"
},
"year": {
"type": "integer"
},
"topic": {
"type": "keyword"
}
}
}
}
POST /retrievers_example/_doc/1
{
"vector": [0.23, 0.67, 0.89],
"text": "Large language models are revolutionizing information retrieval by boosting search precision, deepening contextual understanding, and reshaping user experiences in data-rich environments.",
"year": 2024,
"topic": ["llm", "ai", "information_retrieval"]
}
POST /retrievers_example/_doc/2
{
"vector": [0.12, 0.56, 0.78],
"text": "Artificial intelligence is transforming medicine, from advancing diagnostics and tailoring treatment plans to empowering predictive patient care for improved health outcomes.",
"year": 2023,
"topic": ["ai", "medicine"]
}
POST /retrievers_example/_doc/3
{
"vector": [0.45, 0.32, 0.91],
"text": "AI is redefining security by enabling advanced threat detection, proactive risk analysis, and dynamic defenses against increasingly sophisticated cyber threats.",
"year": 2024,
"topic": ["ai", "security"]
}
POST /retrievers_example/_doc/4
{
"vector": [0.34, 0.21, 0.98],
"text": "Elastic introduces Elastic AI Assistant, the open, generative AI sidekick powered by ESRE to democratize cybersecurity and enable users of every skill level.",
"year": 2023,
"topic": ["ai", "elastic", "assistant"]
}
POST /retrievers_example/_doc/5
{
"vector": [0.11, 0.65, 0.47],
"text": "Learn how to spin up a deployment of our hosted Elasticsearch Service and use Elastic Observability to gain deeper insight into the behavior of your applications and systems.",
"year": 2024,
"topic": ["documentation", "observability", "elastic"]
}
![]()
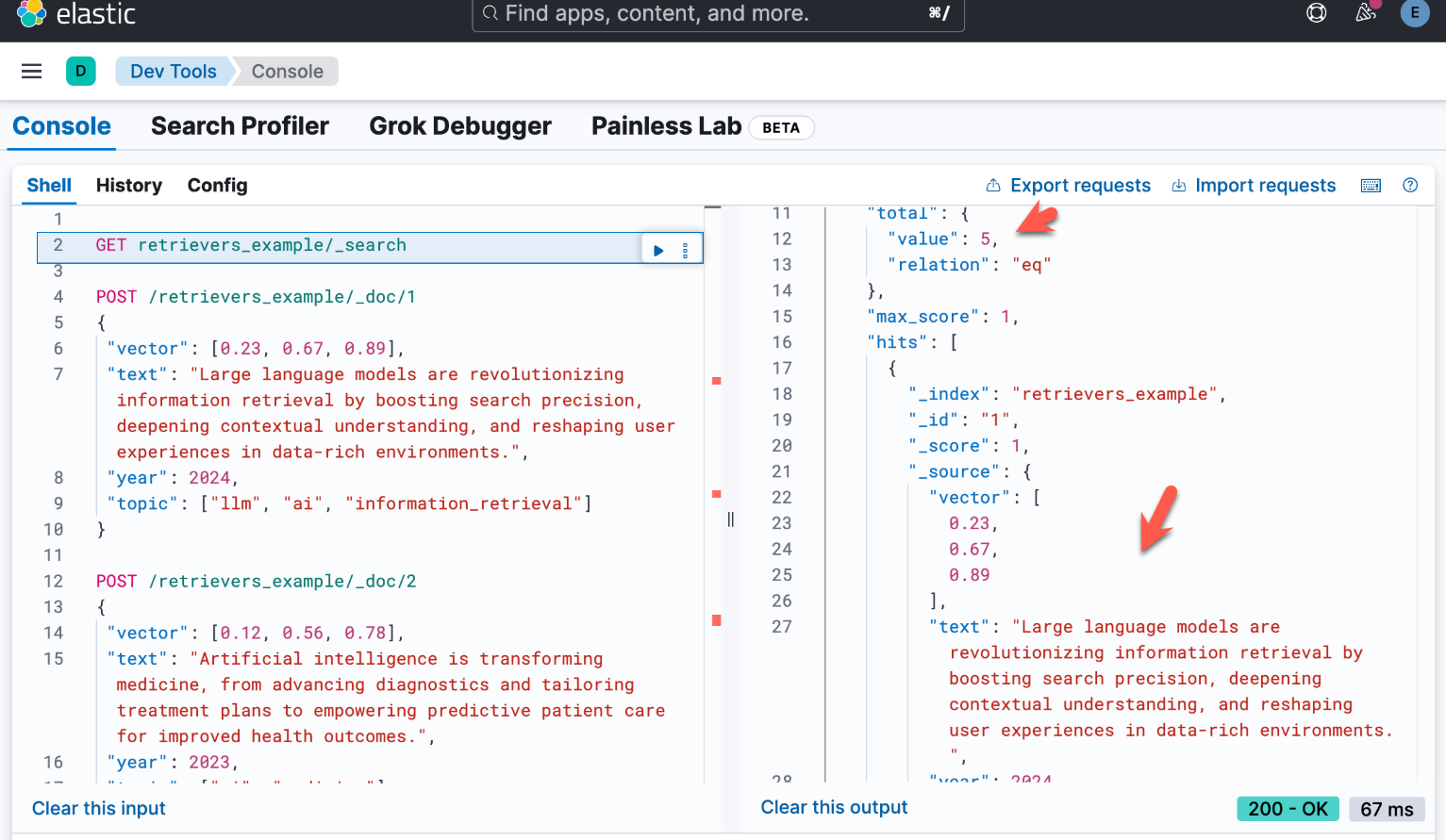
现在我们已经有了文档,让我们尝试使用检索器运行一些查询。
示例:使用 RRF 结合查询和 kNN
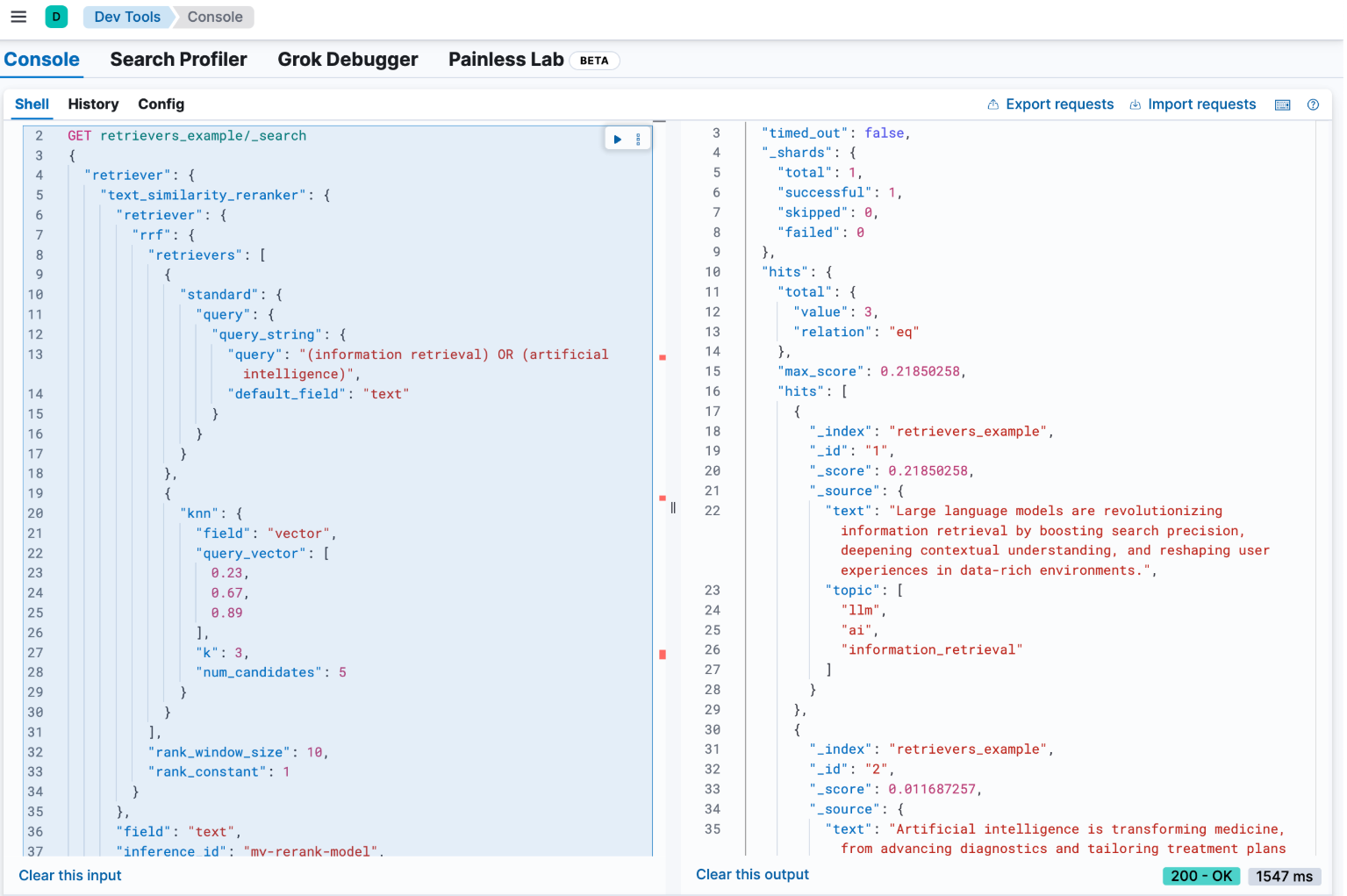
首先,让我们研究如何结合两种不同类型的查询:kNN 查询和 query_string 查询。虽然这些查询可能会产生不同范围内的分数,但我们可以使用倒数排名融合 (rrf) 来结合结果并生成合并的最终结果列表。
为了在检索器框架中实现这一点,我们从顶级元素开始:我们的 rrf 检索器。此检索器在另外两个检索器上运行:knn 检索器和 standard 检索器。我们的查询结构如下所示:
GET /retrievers_example/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"query_string": {
"query": "(information retrieval) OR (artificial intelligence)",
"default_field": "text"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [
0.23,
0.67,
0.89
],
"k": 3,
"num_candidates": 5
}
}
],
"rank_window_size": 10,
"rank_constant": 1
}
},
"_source": [
"text",
"topic"
]
}
![]()
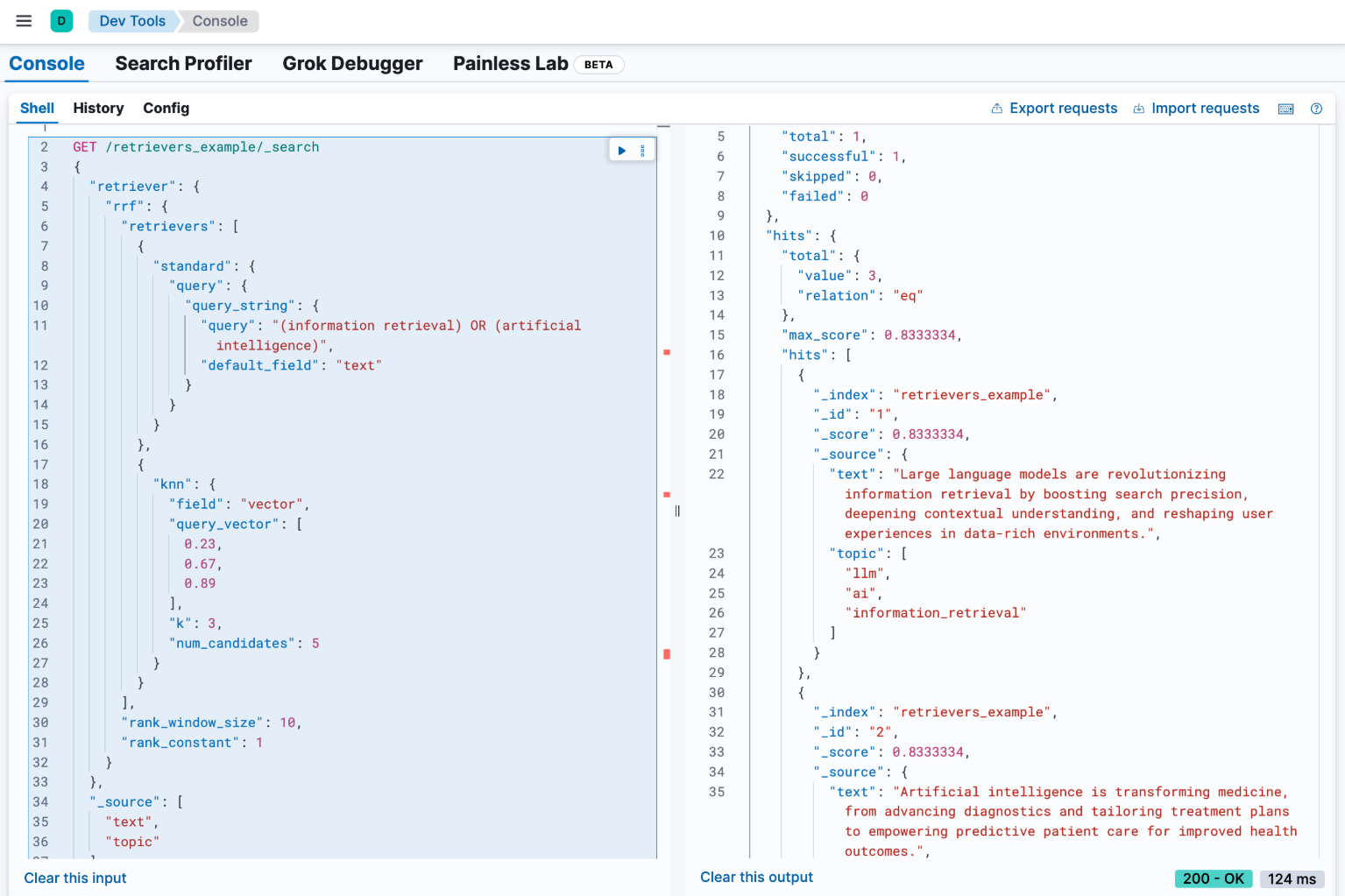
示例:使用 collapse 功能按年份对结果进行分组
在我们的结果集中,有许多文档的年份值相同。我们可以使用检索器的 collapse 参数来清理这些文档。这可以按任何字段对结果进行分组,并仅返回每个组中得分最高的文档。在此示例中,我们将根据 year 字段 collapse 结果。
GET /retrievers_example/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"query_string": {
"query": "(information retrieval) OR (artificial intelligence)",
"default_field": "text"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [
0.23,
0.67,
0.89
],
"k": 3,
"num_candidates": 5
}
}
],
"rank_window_size": 10,
"rank_constant": 1
}
},
"collapse": {
"field": "year",
"inner_hits": {
"name": "topic related documents",
"_source": [
"text",
"year"
]
}
},
"_source": [
"text",
"topic"
]
}
![]()
示例:对 RRF 检索器的结果进行重新排序
之前,我们在 rrf 检索器中使用了 text_similarity_reranker 检索器。由于检索器支持完全可组合性,因此我们还可以对 rrf 检索器的结果进行重新排序。让我们将其应用于我们的第一个示例。
GET retrievers_example/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"query_string": {
"query": "(information retrieval) OR (artificial intelligence)",
"default_field": "text"
}
}
}
},
{
"knn": {
"field": "vector",
"query_vector": [
0.23,
0.67,
0.89
],
"k": 3,
"num_candidates": 5
}
}
],
"rank_window_size": 10,
"rank_constant": 1
}
},
"field": "text",
"inference_id": "my-rerank-model",
"inference_text": "What are the state of the art applications of AI in information retrieval?"
}
},
"_source": [
"text",
"topic"
]
}
![]()
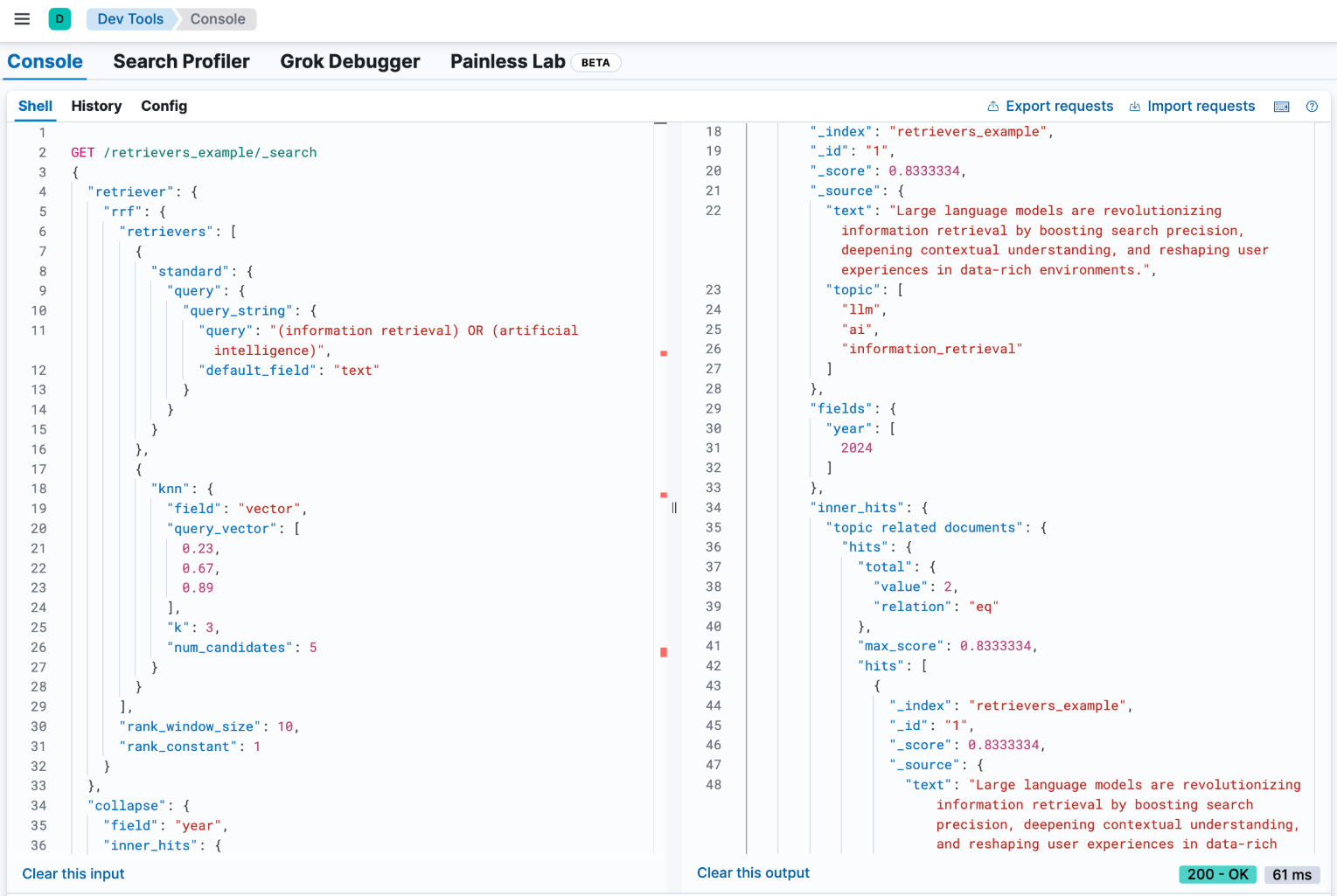
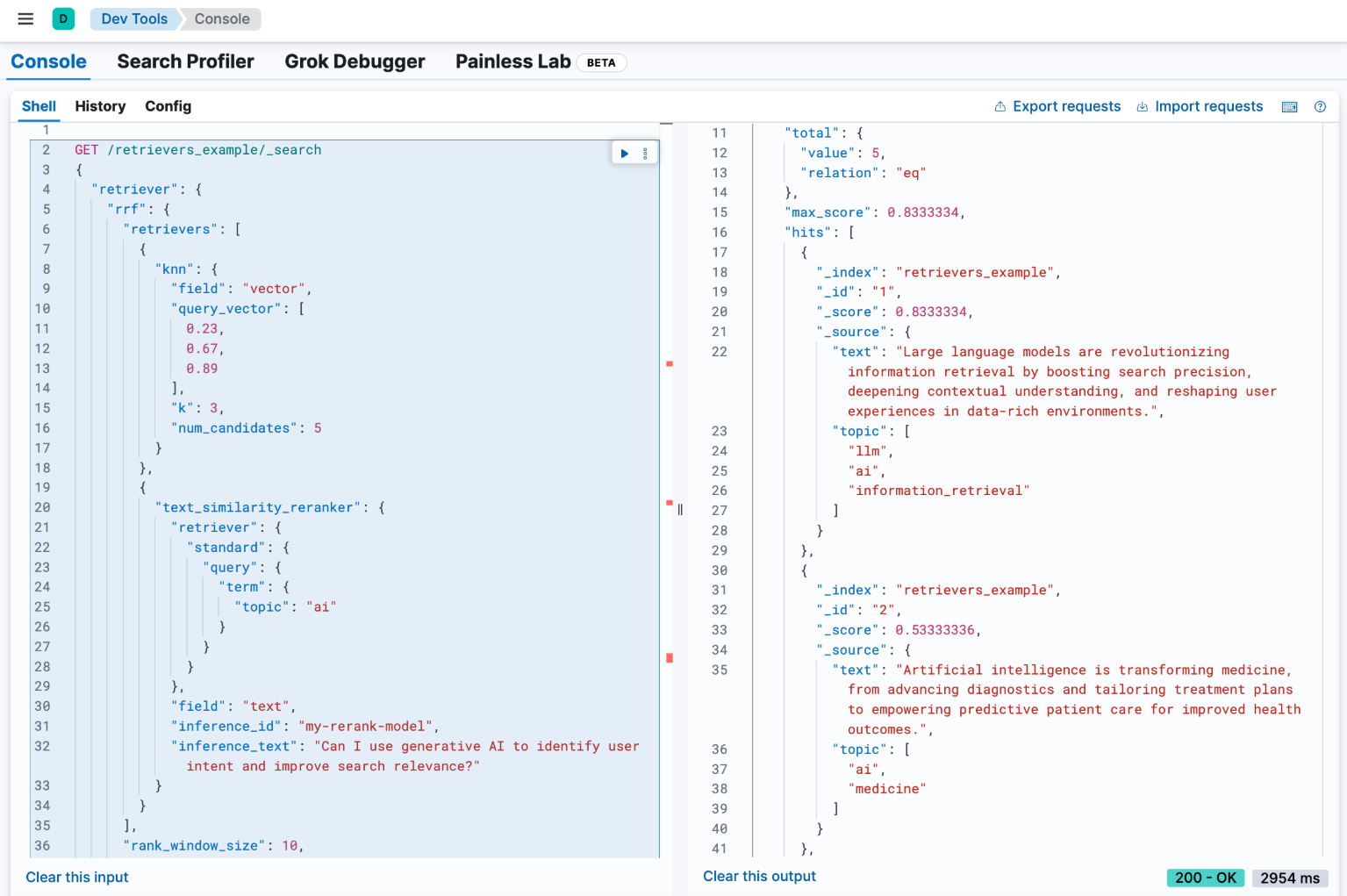
示例:带语义重排器的 RRF
在此示例中,我们将用之前配置的 my-rerank-model 重排器替换语义查询。由于这是一个重排器,因此它需要一个初始文档池来处理。在本例中,我们将筛选有关 ai 主题的文档。
![]()
GET /retrievers_example/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"knn": {
"field": "vector",
"query_vector": [
0.23,
0.67,
0.89
],
"k": 3,
"num_candidates": 5
}
},
{
"text_similarity_reranker": {
"retriever": {
"standard": {
"query": {
"term": {
"topic": "ai"
}
}
}
},
"field": "text",
"inference_id": "my-rerank-model",
"inference_text": "Can I use generative AI to identify user intent and improve search relevance?"
}
}
],
"rank_window_size": 10,
"rank_constant": 1
}
},
"_source": [
"text",
"topic"
]
}
![]()
示例:链接多个语义重排序器
完全可组合性意味着我们可以将多个相同类型的检索器链接在一起。例如,假设我们有一个专门用于 AI 内容的计算成本高昂的重排序器。我们可以使用另一个 text_similarity_reranker 检索器对 text_similarity_reranker 的结果进行重排序。每个重排序器都可以在不同的字段上运行和/或使用不同的推理服务。
![]()
GET retrievers_example/_search
{
"retriever": {
"text_similarity_reranker": {
"retriever": {
"text_similarity_reranker": {
"retriever": {
"knn": {
"field": "vector",
"query_vector": [
0.23,
0.67,
0.89
],
"k": 3,
"num_candidates": 5
}
},
"rank_window_size": 100,
"field": "text",
"inference_id": "my-rerank-model",
"inference_text": "What are the state of the art applications of AI in information retrieval?"
}
},
"rank_window_size": 10,
"field": "text",
"inference_id": "my-other-more-expensive-rerank-model",
"inference_text": "Applications of Large Language Models in technology and their impact on user satisfaction"
}
},
"_source": [
"text",
"topic"
]
}
请注意,我们的示例应用了两个重新排序步骤。首先,我们使用 my-rerank-model 重新排序器对来自 knn 搜索的前 100 个文档进行重新排序。然后我们挑选前 10 个结果并使用更细粒度的 my-other-more-expensive-rerank-model 对它们进行重新排序。
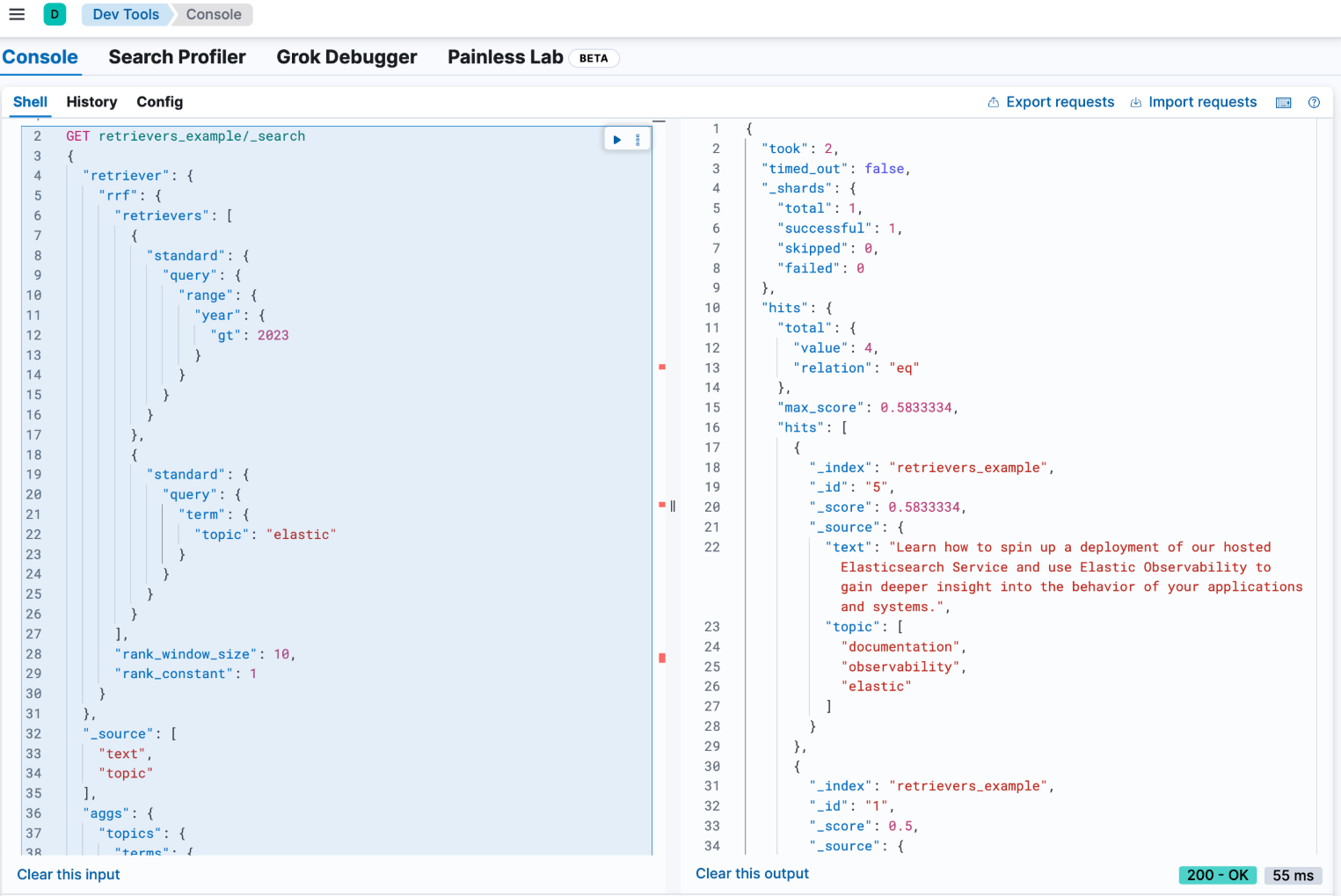
示例:将 RRF 与聚合相结合
检索器支持可组合性和大多数标准 _search 功能。例如,我们可以使用 rrf 检索器计算聚合。使用复合检索器时,聚合将基于其嵌套检索器进行计算。在以下示例中,主题字段的术语聚合将包括来自 2 个嵌套检索器的所有结果,而不仅仅是顶部的 rank_window_size,即 year 字段大于 2023 且主题字段与术语 elastic 匹配的所有文档。
GET retrievers_example/_search
{
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"range": {
"year": {
"gt": 2023
}
}
}
}
},
{
"standard": {
"query": {
"term": {
"topic": "elastic"
}
}
}
}
],
"rank_window_size": 10,
"rank_constant": 1
}
},
"_source": [
"text",
"topic"
],
"aggs": {
"topics": {
"terms": {
"field": "topic"
}
}
}
}
![]()
更多有关 retrievers 的阅读,请参考文章 “Elasticsearch:Retrievers 介绍 - Python Jupyter notebook”。
词汇表
以下是一些重要术语:
- 检索管道(Retrieval Pipeline)。定义整个检索和排名逻辑以产生顶级匹配。
- 检索器树(Retriever Tree)。定义检索器如何交互的层次结构。
- 第一阶段检索器(First-stage Retriever)。返回一组初始候选文档。
- 复合检索器(Compound Retriever)。基于一个或多个检索器构建,增强文档检索和排名逻辑。
- 合并器(Combiners)。将来自多个子检索器的热门匹配合并在一起的复合检索器。
- 重新排序器(Rerankers)。特殊的复合检索器,对匹配进行重新排序并可能调整匹配数量,第一阶段和第二阶段重新排序器之间有所区别。