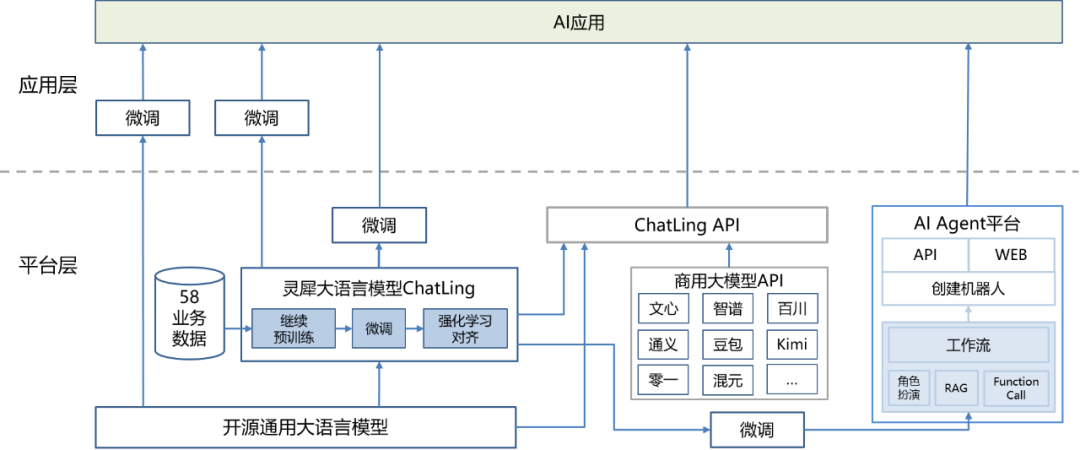
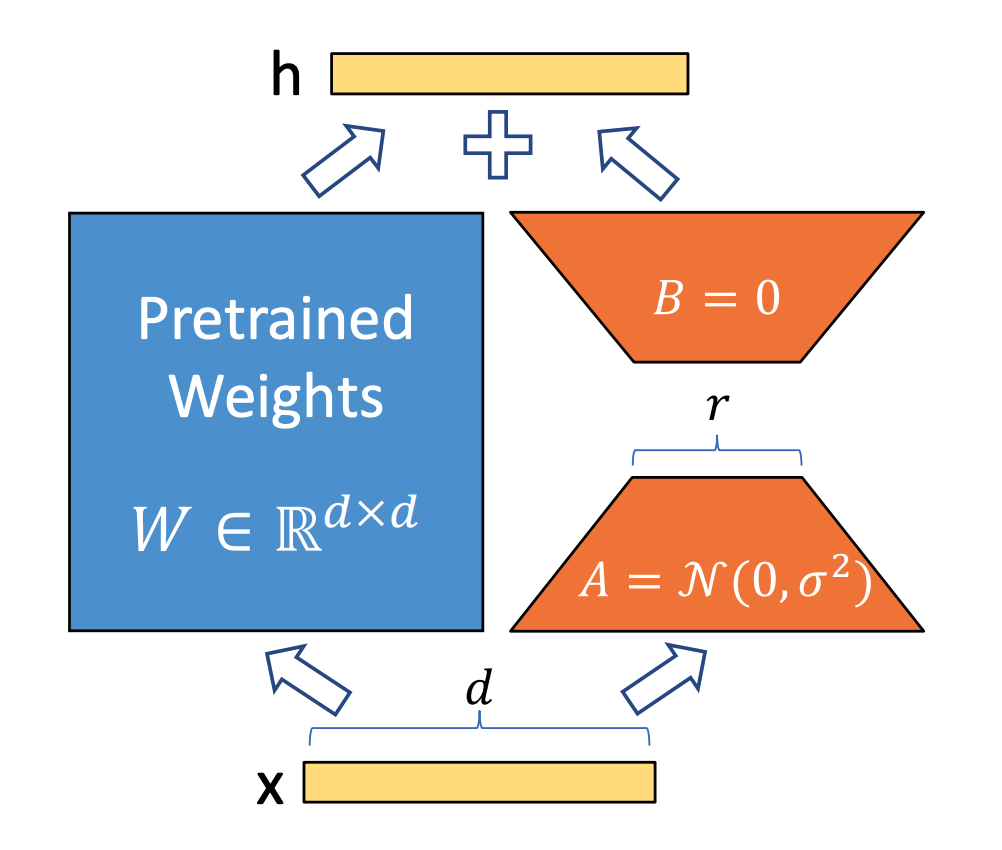
由于上面两种方法的劣势,我们希望找到一种方法既能像全参微调一样不增加额外输入或改变模型结构,又能大幅度减少训练参数量降低微调成本的方法。基于此LoRA(Low-Rank Adaptation,低秩适配器)第一个解决了这个问题。如下图是LoRA的整体架构,Lora通过在原始权重矩阵W的旁边新增一个旁路,这个旁路由低秩的两个矩阵 A 和 B 组成,这两个低秩矩阵组合用来近似模拟全参更新中的 ΔW 增量矩阵。在训练过程中,我们冻结住原始预训练模型的权重 W ,只更新LoRA的两个低秩参数矩阵 A 和 B 。为了在训练的初始时刻能保证加了LoRA Adapter之后不影响原始模型的能力,我们分别使用高斯初始化和零初始化来初始化 A 和 B 。
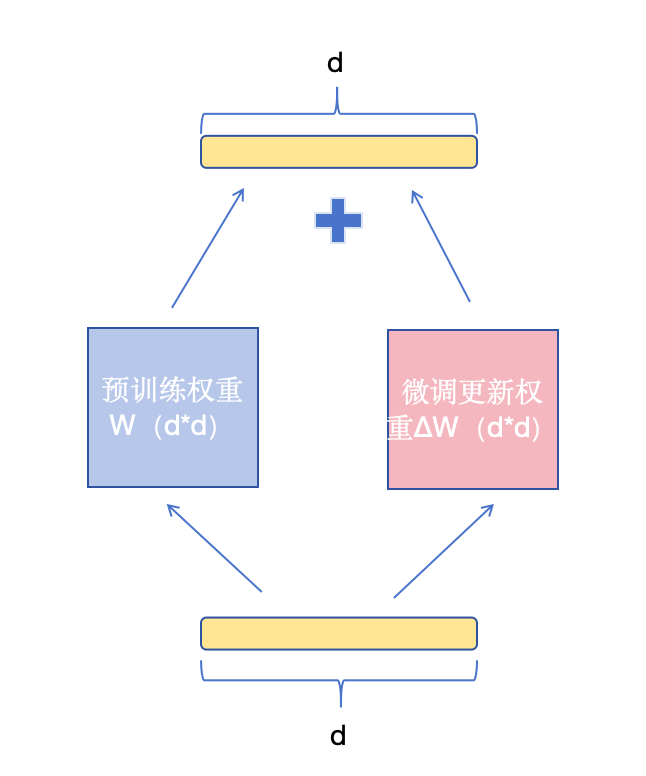
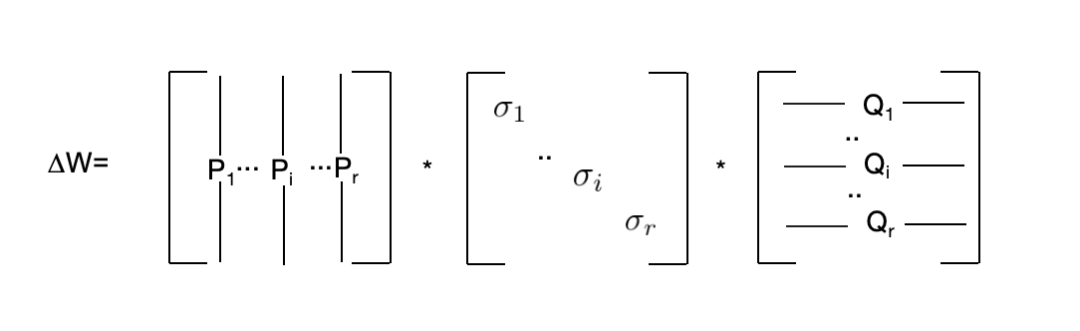
假设原始权重矩阵的维度是 d×d,LoRA低秩矩阵A的维度设置为 r×d,矩阵B的维度为 d×r,这里我们冻结原始权重,相当于只更新增量权重。可以理解为我们先通过A矩阵进行一个降维操作,然后再使用B矩阵进行升维操作。这样微调的参数就从原来的 d×d 降低到了 2×d×r。因为一般设置的参数 r 会远小于 d,所以这里能大大降低训练参数量。在训练过程中,由于预训练权重 W 被冻结,仅对低秩矩阵 A 和 B 进行训练。因此,在保存LoRA训练的权重时,仅需保存参数量相对较小的低秩部分即可。训练时,GPU显存通常存储以下内容:输入数据、模型权重、模型的中间结果、梯度以及优化器状态。相比全参数微调方法,LoRA训练中输入数据部分显存占用不变。而因为原始权重也需要参与计算,因此模型权重和中间结果的占用也不变(增加的LoRA部分权重几乎可以忽略不计)。关于梯度的显存占用分析则相对复杂,以反向传播时 B 的梯度计算为例进行具体分析如下:
h=Wx+BAx=Wmx∂B∂L=∂h∂L∂Wm∂h∂B∂Wm
考虑 B 梯度的前两项,梯度的维度和预训练权重的梯度相同,均为 d×d。然而,由于LoRA并不作用于模型的所有层,并且由于训练参数的减少,优化器状态的存储显著减少,因为通常像类似adam优化器需要存储一阶梯度和二阶动量,而且通常优化器状态中存储的都是fp32类型的值,所以这部分显存占用相比全参微调大大降低,总体上显著降低了显存的占用。在推理时,将LoRA权重与原始权重合并即 h=(W+BA)x 的方式得到与原始模型一样的结构。这意味着完全不需要改变模型的任何结构,微调后模型的推理参数量与原始模型参数量完全一致。且这种方式让我们可以根据不同的业务场景基于同一个基座模型训练不同的LoRA权重,然后在不同的应用上加载不同的LoRA权重,非常灵活,而且LoRA权重通常非常小,也很易于存储和加载。
LoRA特点总结:
• 对 A 采用高斯初始化,对 B 采用零初始化;
• 微调的参数就从原来的 d×d 降低到 2×d×r ; r << d。
• 推理时不增加任何计算量,与原始模型架构完全一致
• 可以基于同一个基座在不同的场景下训练不同的lora模型加载使用
实验
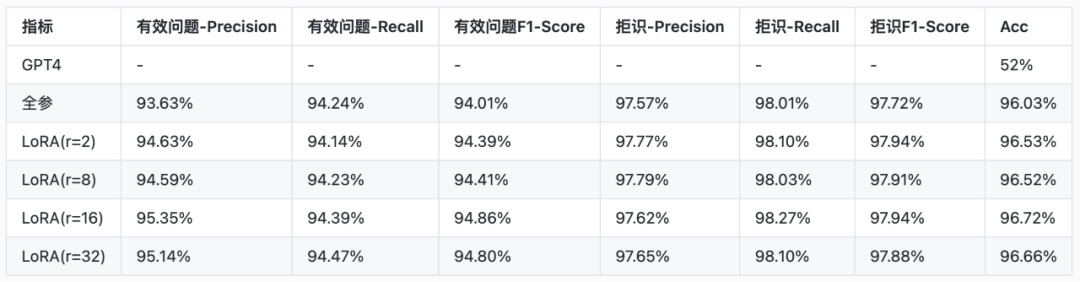
LoRA现已在业界广泛应用于各个场景的微调任务,在诸多任务中都被验证是有效且可行的。我们也基于两个业务场景做了单一任务的微调实践。LoRA的原理在于增量矩阵 ΔW 满足低秩假设, h=(W+ΔW)×x 中的 ΔW 确实是一个低秩矩阵。如果不满足该假设,那么LoRA的分解就一定会有精度损失,而达不到最好的微调效果。因此需要在任务中需要选择合适的 r,理论上说,针对复杂的任务可能需要更大的 r,但是 r 的值越大,可训练的参数量就越大,训练时长和显存占用就会同时变得更大。一般来说增大 r 的值会取得更好的微调效果,但是也不是一定如此,对于简单任务的微调太大的训练参数反而会使模型训练容易过拟合而导致效果变差。因此在实验阶段我们在两个NLU业务数据集上对比了全参训练、以及不同大小的 r 的训练效果,同时为了证明微调的效果,我们还加入了使用GPT4 zero-shot做该任务的效果对比。实验基座模型采用qwen1.5-7b-base,我们分别对比全参微调、LoRA不同 r 的微调以及直接使用GPT4的效果对比(业务数据集2中“有效问题”指除了标签为“其它”的数据,“拒识”指标签为“其它”的数据):
if use_extra_value: # one more positive value, this is an asymmetric type v1 = norm.ppf(torch.linspace(offset, 0.5, 9)[:-1]).tolist() # 正数部分 v2 = [0]*(16-15) ## we have 15 non-zero values in this data type v3 = (-norm.ppf(torch.linspace(offset, 0.5, 8)[:-1])).tolist() #负数部分 v = v1 + v2 + v3 else: v1 = norm.ppf(torch.linspace(offset, 0.5, 8)[:-1]).tolist() v2 = [0]*(16-14) ## we have 14 non-zero values in this data type v3 = (-norm.ppf(torch.linspace(offset, 0.5, 8)[:-1])).tolist() v = v1 + v2 + v3
for n, p in self.model.named_parameters(): if ("lora_A"in n or"lora_B"in n) and self.trainable_adapter_name in n: para_cov = p @ p.T if"lora_A"in n else p.T @ p I = torch.eye(*para_cov.size(), out=torch.empty_like(para_cov)) I.requires_grad = False num_param += 1 regu_loss += torch.norm(para_cov - I, p="fro") if num_param > 0: regu_loss = regu_loss / num_param else: regu_loss = 0 outputs.loss += orth_reg_weight * regu_loss
all_score = [] # 取到每个三元组的重要性分数 # Calculate the score for each triplet for name_m in vector_ipt: ipt_E = value_ipt[name_m] ipt_AB = torch.cat(vector_ipt[name_m], dim=1) # sum_ipt = self._combine_ipt(ipt_E, ipt_AB) name_E = name_m % "lora_E" triplet_ipt[name_E] = sum_ipt.view(-1, 1) all_score.append(sum_ipt.view(-1))
# 取到前budget个数的分数值做为mask的threshold阈值 # Get the threshold by ranking ipt mask_threshold = torch.kthvalue( torch.cat(all_score), k=self.init_bgt - budget, )[0].item()
rank_pattern = {} # 直接把小于threshold阈值的三元组置0 # Mask the unimportant triplets with torch.no_grad(): for n, p in model.named_parameters(): iff"lora_E.{self.adapter_name}"in n: p.masked_fill_(triplet_ipt[n] <= mask_threshold, 0.0) rank_pattern[n] = (~(triplet_ipt[n] <= mask_threshold)).view(-1).tolist() return rank_pattern
optimizer.step() lr_scheduler.step() # Update the importance of low-rank matrices # and allocate the budget accordingly. model.base_model.update_and_allocate(global_step)
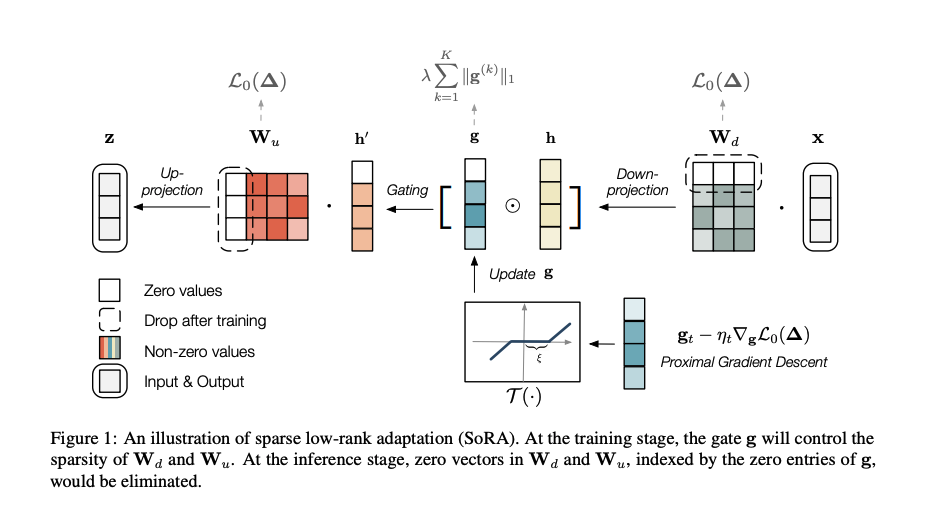
SoRA在普通LoRA的低秩分解中间加了一个门单元 g ,图中也可以看到,输入 X 先经过一个降维矩阵 Wd ,变成 h ,再经过门单元 g 控制 Wd 的秩(控制秩的操作在于门单元 g 部分值为0),类似于把 Wd 的某一行全部置为0,这个操作与adalora相比是自适应的,也就是不需要手动设置target r预算并根据阈值置0。门操作的更新函数如下:(这样设置的原因其实是因为这是求近端梯度下降算法LASSO问题的解析解:软阈值函数)
if self.args.train_sparse: sparse_loss = 0.0 p_total = 0 for n, p in model.named_parameters(): if"lora.gate"in n: sparse_loss += torch.sum(torch.abs(p)) p_total += torch.numel(p.data) loss += self.sparse_lambda * sparse_loss / p_total
[1] Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International conference on machine learning. PMLR, 2019: 2790-2799.
[2] Li X L, Liang P. Prefix-tuning: Optimizing continuous prompts for generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[3] Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language models[J]. arXiv preprint arXiv:2106.09685, 2021.
[4] Dettmers T, Pagnoni A, Holtzman A, et al. Qlora: Efficient finetuning of quantized llms[J]. Advances in Neural Information Processing Systems, 2024, 36.
[5] Zhang Q, Chen M, Bukharin A, et al. Adaptive budget allocation for parameter-efficient fine-tuning[C]//International Conference on Learning Representations. Openreview, 2023.
[6] Ding N, Lv X, Wang Q, et al. Sparse low-rank adaptation of pre-trained language models[J]. arXiv preprint arXiv:2311.11696, 2023.
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。