01 缘起
最近,我听到了有人用“皮实”来形容 RocketMQ,RocketMQ 一直给人简单、稳定和可靠的形象,其实稳定性的认可得来是最不容易的。
回想起来,2012 年是 RocketMQ 参与的第一次阿里双十一,成功处理了 10 亿级的消息量,算是小试牛刀,随后 RocketMQ 跟着阿里巴巴的电商业务逐渐从百亿、千亿、五千亿,直到 2016 年双十一当天,RocketMQ 零问题支撑了万亿级的消息量。
这四年,RocketMQ 积累了大量的稳定性经验,RocketMQ 团队从来不吝啬将这些经验开源到社区,所以今天如果大家仔细挖掘,可以在 RocketMQ 零散的代码片段里找到很多稳定性细节。比如客户端里面的小黑屋机制,Broker 侧的请求快速失败,os.sh 对内存、磁盘调度器、文件句柄等的调整,服务端时不时就有一类 RPC 请求拥有了自己的独立线程池。这些冰冷的代码变更背后,可能是 RocketMQ 团队背下的一个又一个的故障。
02 上云之路
时间来到了上云的时刻,技术人终于有一天能把技术变成产品,能直接给公司的营收做出贡献,RocketMQ 开始为云上数万的企业客户提供全托管的服务。相比较支撑阿里的双十一业务,我们开始意识到,即使在内部做到了万亿级的规模,实际上 RocketMQ 的客户也只有阿里巴巴这一个,在云上,不同的客户,不同的业务规模,不同的流量模型,加上彼时还并不怎么成熟的云,给我们带来了全新的挑战。
RocketMQ 上云后不久,就出了一次令我印象深刻的故障,出问题的时候我正挤在公交车上,有客户反馈消费出现了延迟,这个看似简单的问题排查起来并不那么容易:
最终,我们怀疑是不是因为有消费者在冷读,消耗了高效云盘为数不多的 IOPS,导致大量的消费者在排队拉取消息呢。在运维工具比较缺乏的那个时候,要验证这个猜想也并不容易,最终我现场写了一行获取拉取消息延迟 Top 5 的消费者组的命令:
grep GROUP_GET_LATENCY stats.log | grep "In One Minute" | sort -nk14 | tail -n 5
该命令验证了我们的猜想,确实有消费者组在冷读,很高的拉取耗时消耗了大部分的线程,导致其他消费者组出现了饥饿。
这条命令,随着我写过很多类似的命令和脚本,在团队流行了很长一段时间,以年为单位的时间,这是一个有趣的现象,这背后的原因**是因为很多团队对运维工具化和自动化的投入是严重不足的,运维人员靠着口口相传的经验与教训,苦苦支撑着关乎公司业务命脉的核心消息集群。**这其中的辛苦与压力,我是非常能感同身受的。
到今天,我一直在思考一个问题,我们运维过全球最大的 RocketMQ 集群,服务过数万的 RocketMQ 企业客户,我们对每一行的代码,不仅仅是代码,甚至是这行代码在不同环境下的不同表现都清清楚楚,我们能否把这些经验,把曾经凌晨处理过的故障,把不分昼夜的报警电话,以及烂熟于心的日志,都通过代码的形式沉淀下来,能够帮助 RocketMQ 的运维团队,高效、轻松地运维好 RocketMQ 集群,给业务提供高质量的 RocketMQ 服务。
所以,RocketMQ Copilot 来了。
03 RocketMQ Copilot
RocketMQ Copilot 是我们团队倾心打造的一款面向 Apache RocketMQ 的智能辅助运维系统,其核心理念是将团队十多年 RocketMQ 集群的生产实战经验以产品化形式呈现,在辅助广大企业开发者运维管理自建集群的同时,也能方便掌握 RocketMQ 集群运维的最佳实践。
目前 RocketMQ Copilot 主要包含系统巡检、专家诊断和集群治理三块功能。我们希望 RocketMQ 曾经出过的故障不再被更多开发者重复去踩坑,能在系统出现故障之前就能提前发现,提前治理,防患于未然。出现故障后,也能快速精准定位问题。即使对源码不熟悉,也能有足够信心敢于在生产系统上部署。
系统巡检
系统巡检主要用来解决一个问题:集群到底正不正常? 这个问题其实很难回答,因为集群的状态是动态的,流量的变化,集群的健康状态也会发生变化,我们在处理了数千个生产问题后,终于灵魂拷问了自己一把:我们到底能不能先于用户发现问题?这个问题的答案便是「系统巡检」这一功能模块。
我们规划了上百个系统巡检项,目前 RocketMQ Copilot 已经实现了 40+,涵盖:
-
内核参数巡检,确保 RocketMQ 运行的内核环境是处于最佳配置的状态。
-
集群参数巡检,RocketMQ 有数百个配置项,要充分掌握每一个配置项其实是相当有难度的,Copilot 会根据集群的情况,动态确保每一个参数项在当前负载下是属于最佳配置。
-
消费者组巡检,检查每一个客户端配置是否正确,比如最常见的订阅关系是否一致,让大家能发现你的客户,是否正在以推荐的实践使用 RocketMQ。
-
Topic 级巡检,比如 Topic 的路由是否是一致的,是否出现了热点分区等。
其实,这每一个巡检项,背后都有一个或多个的生产故事(不一定是事故),如果大家愿意听,我们后面会出一个 RocketMQ Copilot 运维手册,会讲一讲背后的故事。
专家诊断
有了 RocketMQ Copilot 实时对 RocketMQ 集群做着体检,我们终于对 RocketMQ 集群的健康状况做到“心里有数”了。但 RocketMQ 作为业界首选的业务消息中间件,是微服务架构的核心异步组件,所以我们接触到了大量来自客户的问题,面对这些问题我们一方面要快速“自证清白”,又要能尽最大的努力帮助客户定位到问题的根因。
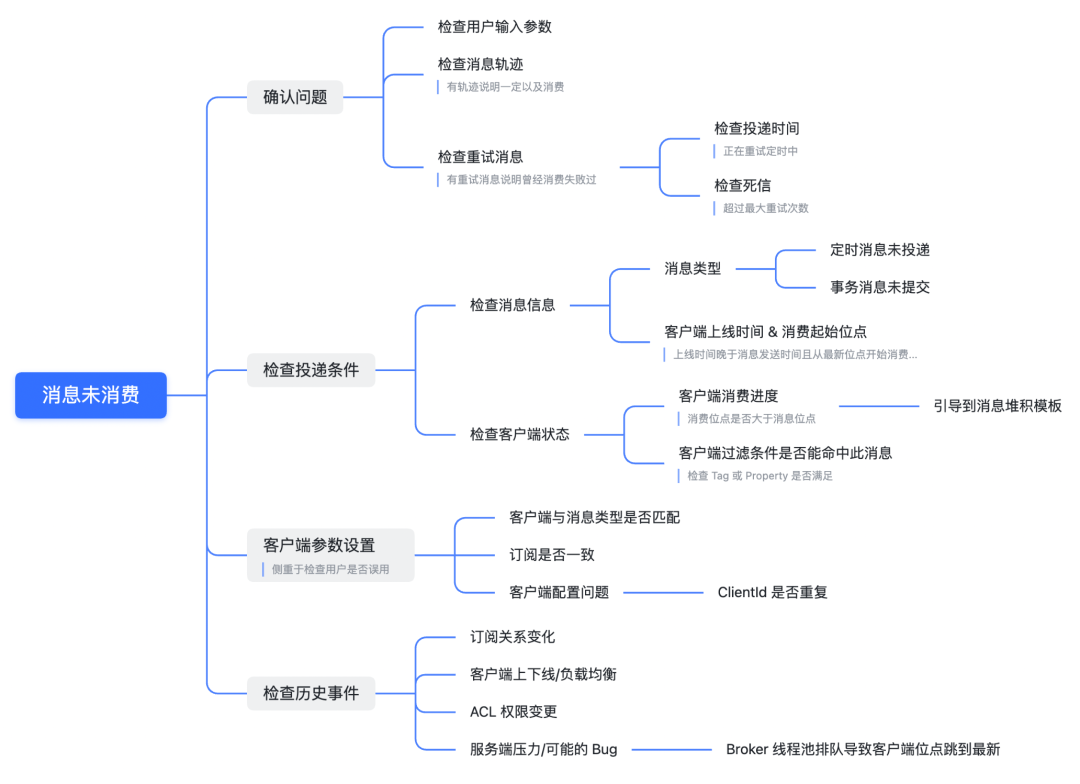
过去总是困扰我们的一个大的问题是客户反馈消息未消费,这到底是客户自身的问题,还是 RocketMQ 丢了消息?RocketMQ 保证至少投递一次的语义需要确保消息绝对不能丢失,被这类问题虐了千百遍后,我们终于整理出来了「消息未消费」问题的排查路径,如下图所示,数十个排查分支,可见排查这类问题的门槛有多高。
![]()
今天,我们将在云上运营 RocketMQ 丰富的问题诊断经验,都做成了 RocketMQ Copilot 专家诊断模板,帮助 RocketMQ 运维团队快速“自证清白”,同时给业务方最大程度的帮助,与业务双赢。
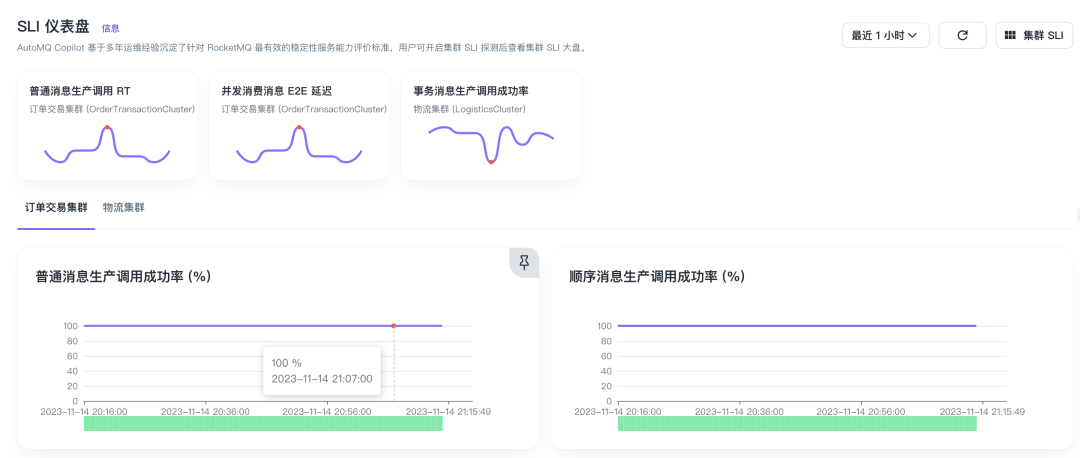
集群治理(SLI/SLO)
系统巡检和专家诊断两大利器主要手段是自检,也就是从内部看,从我们的经验来看往往是有漏网之鱼的。站在用户视角,以模拟真实用户的方式探测、度量、可视化整个集群的稳定性指标,是最后一道“先于用户发现问题”的防线。
通过 RocketMQ Copilot 内置的一系列端到端 SLI,结合自定义 SLO 的能力,我们可以快速以数字化的方式衡量集群的服务质量,同时能配置成精准的报警项,极大程度上消除无效报警和报警噪音。
![]()
04 结束语
感谢你阅读这篇文章,我们希望你能了解到 RocketMQ Copilot 的强大功能,它是我们团队倾注了心血和智慧的结晶,是我们对运维从业者感同身受的产物。RocketMQ Copilot 不仅能让你的 RocketMQ 集群更加稳定、高效和可靠,还能让你的运维工作更加轻松愉快。
RocketMQ Copilot 目前已经完成了第一个版本的开发,更多规划的能力即将发布。同时,该产品对于个人开发者是永久免费的,欢迎大家前往AutoMQ 官网(https://play.automq.com) 试用这款匠心之作,感受 RocketMQ Copilot 给你带来的不一样的运维体验。我们期待你的反馈和建议,让我们一起让 RocketMQ 更加美好!
END
关于我们
AutoMQ 是一家专业的消息队列和流存储软件服务供应商。AutoMQ 开源的 AutoMQ Kafka 和 AutoMQ RocketMQ 基于云对 Apache Kafka、Apache RocketMQ 消息引擎进行重新设计与实现,在充分利用云上的竞价实例、对象存储等服务的基础上,兑现了云设施的规模化红利,带来了下一代更稳定、高效的消息引擎。此外,AutoMQ 推出的 RocketMQ Copilot 专家系统也重新定义了 RocketMQ 消息运维的新范式,赋能消息运维人员更好的管理消息集群。
🌟 GitHub 地址:https://github.com/AutoMQ
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
👉 扫二维码加入我们的社区群
![]()
关注我们,一起学习更多云原生干货