![]()
线上沙龙 - 技术流第 35 期回放来啦
本期直播我们邀请到 KaiwuDB 高级研发工程师徐胜康,为大家分享 Hash Index 原理和应用。徐老师曾任职于 Sun Micro Systems, Lucent 等公司,具备多年 Linux/UNIX Operating System 内核、驱动、文件系统、数据库、研发工作与技术管理经验,对分布式系统、性能优化、数据加密等领域有着深入的研究。
索引数据结构是计算机科学里非常重要的,也是编程中最常使用、最有效的一种数据结构。索引结构有很多不同类型。本期直播详细对比了比较常见的多种索引结构,并着重深入讲解了哈希索引。欢迎点击链接观看本次直播回放↓↓↓
【Hash Index 原理和应用精讲-哔哩哔哩】 https://b23.tv/73yXO3b
直播重点回顾
01 背景介绍
1. 追加数据操作
存储设备有很多类型,例如,电脑文件系统、块设备、云存储、日志存储设备等,数据库和数据表也是一种存储方式。但不论何种存储形式,追加数据操作是最常用也是最有效的存储新数据的方式。
![]()
2. 追加操作的问题
尽管追加数据是插入新数据的有效方式,但会导致数据在存储设备中处于无序的状态,进而使得在无序存储中搜索某些特定数据浪费大量时间。
3. 索引资料结构是解决方案
使用索引数据结构能帮助解决如上问题,实现在无序的存储机制中快速查找数据记录。
02常用索引类型
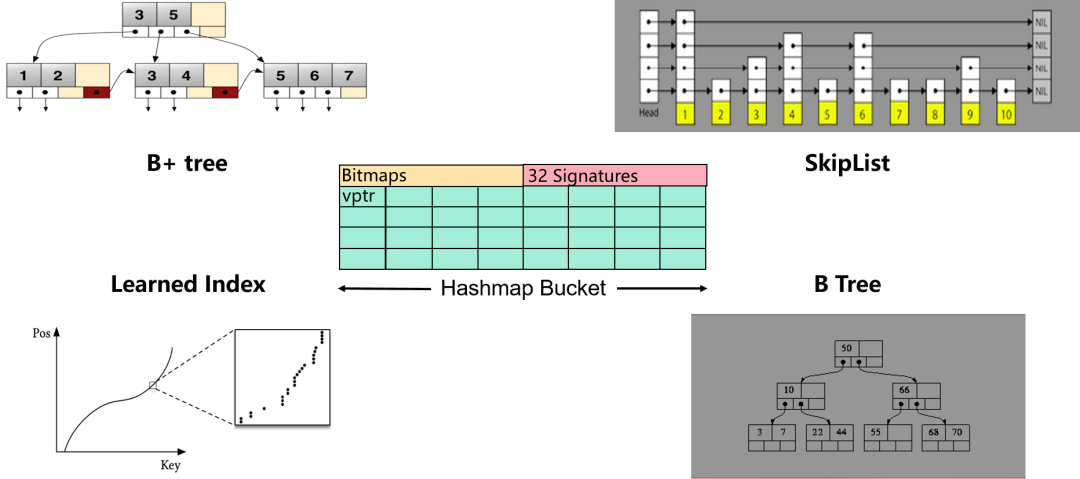
有多种常见的索引数据结构。不同类型的索引结构以不同的方式工作,具有不同的特性。
![]()
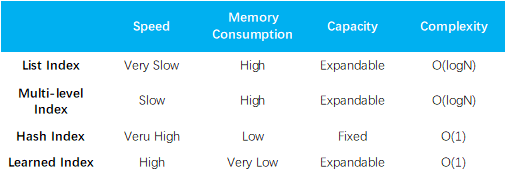
不同类型索引结构对比:
每个索引结构都有优点、缺点和适用情况,不存在全能的索引结构。
![]()
03哈希索引
1. 原始哈希索引
哈希索引最简单的形式是有序数组,它是按键排序的数组,这种方法并不实用,因为索引键可能不是整数;然而,如果可以把索引键转换为整数,它的范围可能会很大,有效条目可能不多,从而导致记忆体利用率变低。
![]()
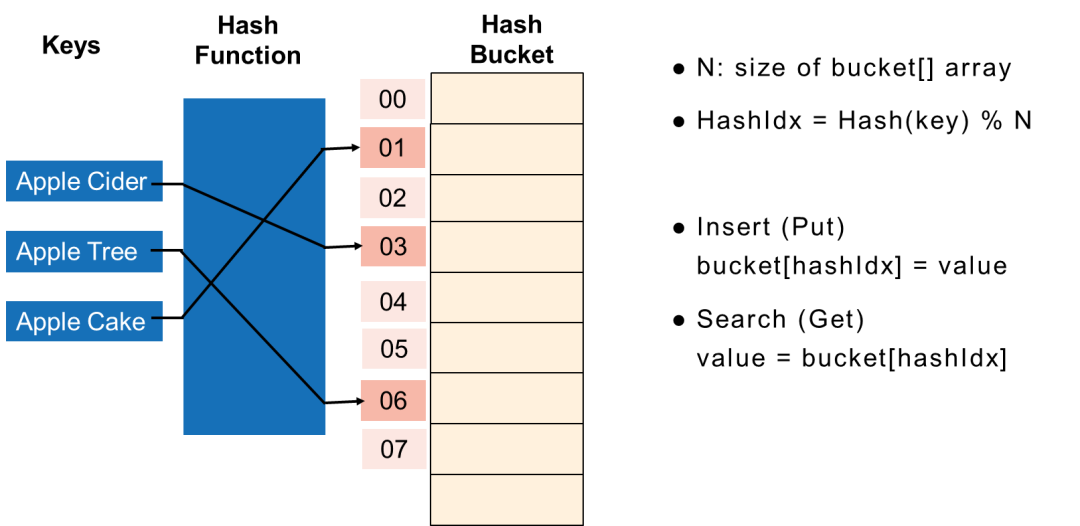
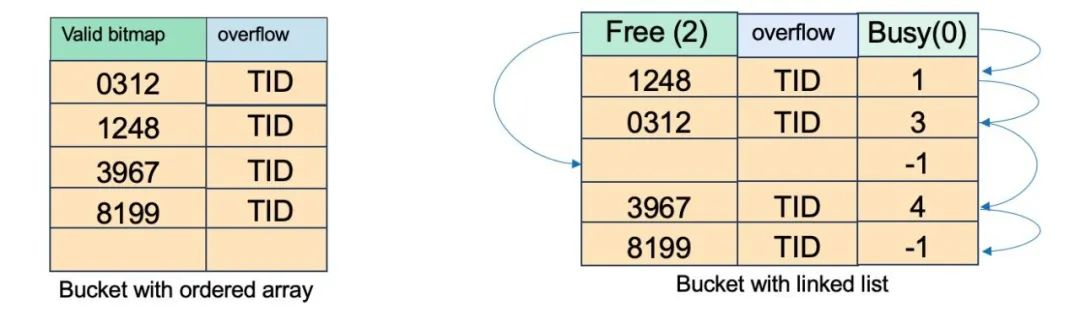
2. 基本哈希索引
基本哈希索引使用哈希函数将键转换为整数,哈希值用于索引桶数组,所有具有相同杂凑(键)值的资料记录将进入相同的杂凑桶。
![]()
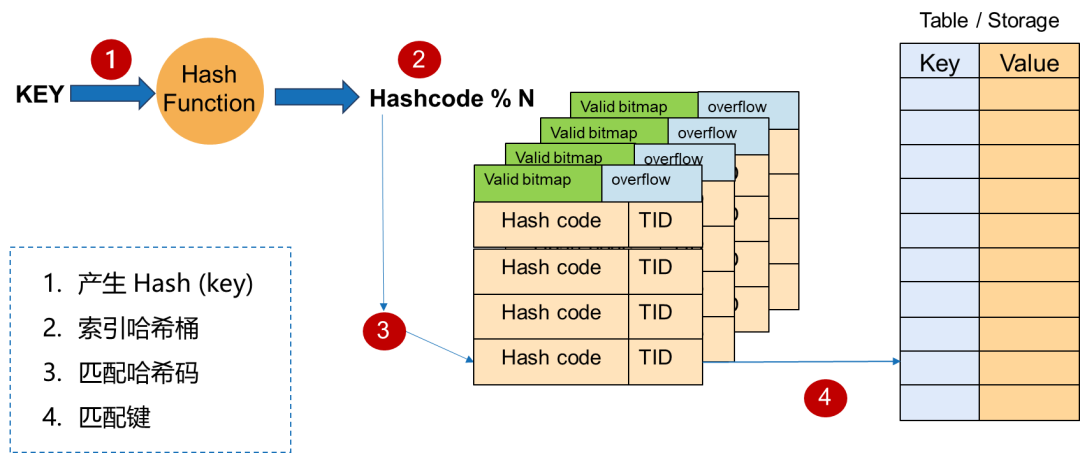
3. 哈希索引搜索步骤
![]()
4. 哈希桶内的记录搜索
哈希桶内的资料记录未排序或组织。因此,定位到哈希桶后,在桶内进行搜寻也面临同样的问题,但规模会相对较小。
![]()
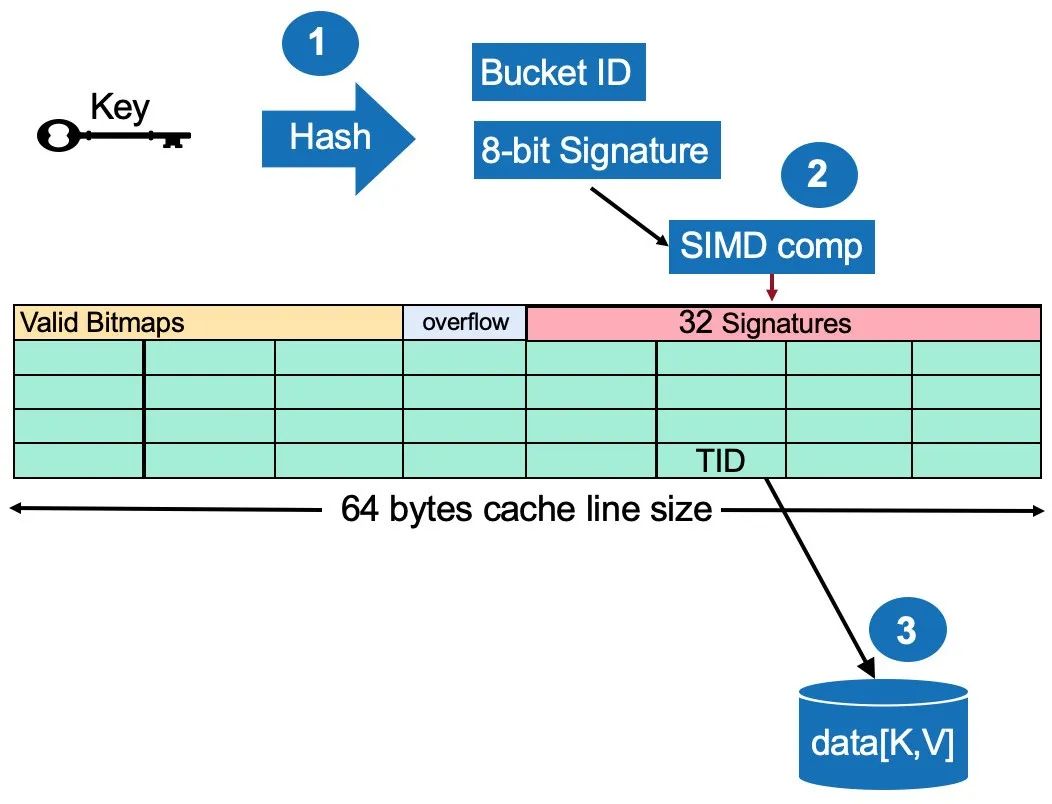
5. 改良的哈希桶设计
基于考虑 CPU 快取行和 SIMD(单指令多资料)而设计的桶格式有效地改善了桶内的搜寻。
-
一种新的利用 CPU 缓存行感知和 SIMD 指令的存储桶格式设计;
-
Bucket 结构必须与 CPU 缓存行对齐;
-
第一个缓存行包含:32-bit 有效位图、一个 8 字节溢出指针、32 字节签名;
-
随后的四个高速缓存行保存 32 个 TID。每个 TID 8 字节。
![]()
6. 改良型哈希桶搜索步骤
在大多数情况下,在桶中搜寻一条记录只需要三个步骤和三次 CPU 快取未命中。
-
哈希函数生成 BucketID 和 8-bit 签名码;
-
SIMD 比较 8-bit 签名与 32 个签,并输出 32-bit 匹配位图。32-bit 匹配位图 AND 32-bit 有效位图生成一个 32-bit 目标位图;
-
根据目标位图找到 TID。
![]()
04哈希索引在 KaiwuDB 中的运用
1. SQL 语法
KaiwuDB 支持多种索引类型,包括哈希索引。KaiwuDB 在哈希连接操作中也使用了哈希索引。
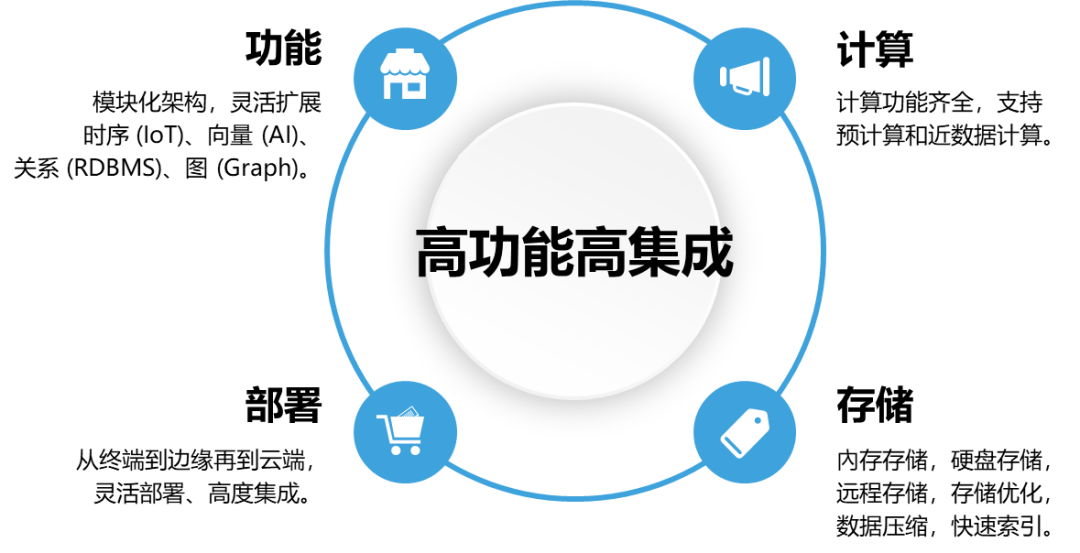
2. KaiwuDB 是一个高效能数据库
KaiwuDB 从一开始就内建了高性能,KaiwuDB 从架构到设计,再到编码实践都遵循最高标准和最佳实践。
-
KaiwuDB 是一个高性能、多功能、高集成的多模块数据库;
-
高性能哈希索引是 KaiwuDB 高性能产品的一部分,它主要用于表索引和散列连接;
-
KaiwuDB 还支持其他类型的索引,例如 B-tree。
![]()
3. KaiwuDB 是一个多功能数据库
KaiwuDB 的模块化架构和设计意味着它可以以灵活且可扩展的方式支持多种功能。
![]()