1、传统的迁移方案
目前,数据迁移主要分为逻辑迁移和物理迁移,逻辑迁移主要有 mysqldump、mydumper ,物理迁移主要有 XtraBackup。对于这类导入导出和拷贝文件的传统迁移方案,在迁移中会存在一些问题:
-
要求业务停机,在迁移过程中,通过需要停止服务,保持静态迁移数据,由于迁移数据量大,需要的迁移时间较长,这也意味着业务停机时间较长。
-
迁移时间久,对于 mysqldump 的逻辑迁移,单线程导出表,迁移时间长。
-
可靠性差,导出异常后,不支持断点能力,在迁移过程中,如果遇到数据库、软件或硬件任何问题导致的任务中断,都需要从头迁移,迁移难度高。
-
保障能力弱,迁移期间,不能提供完善的观测跟干预能力;同时,比较缺乏结构及数据对比能力,缺乏质量保障体系,可能影响迁移成功性。
2、高性能的迁移方案
NineData 提供的数据复制同时包含了数据迁移和数据同步的能力,在不影响业务的前提下,提供了高效、稳定、可运维的大数据量迁移能力。经实测,在源及目标实例同城情况下,500GB 的MySQL数据的迁移,只需 1 个小时,平均迁移速度 142MB/s。
![]()
通过对 MySQL 大数据量迁移的性能测试,和传统迁移比,NineData 数据迁移的优势有:
-
简单易用:一分钟即可完成任务配置,并全自动化完成任务迁移。
-
强劲性能:完善的智能分片、表级行级并发、动态攒批等核心技术,有效保证迁移性能。
-
高可靠:结合新型断点、异常诊断及丰富的修复手段,对于迁移过程中可能出现软硬件故障,提供完善的容灾能力,大大提高了大数据量迁移的成功率。
-
数据质量保障:NineData 还提供了对比功能,包含数据和结构的对比,以及全量、快速(抽样)和不一致复检的对比方式,并且也支持不同的对比频率。在迁移或复制结束后,通过数据和结构对比,能有效的保障数据的一致性。
NineData 在提供强大迁移能力的同时,也保证了使用的简单性,只需要 1 分钟就能完成迁移任务的配置,实现完全自动化的数据迁移过程。下面我们来看下整个任务的配置过程:
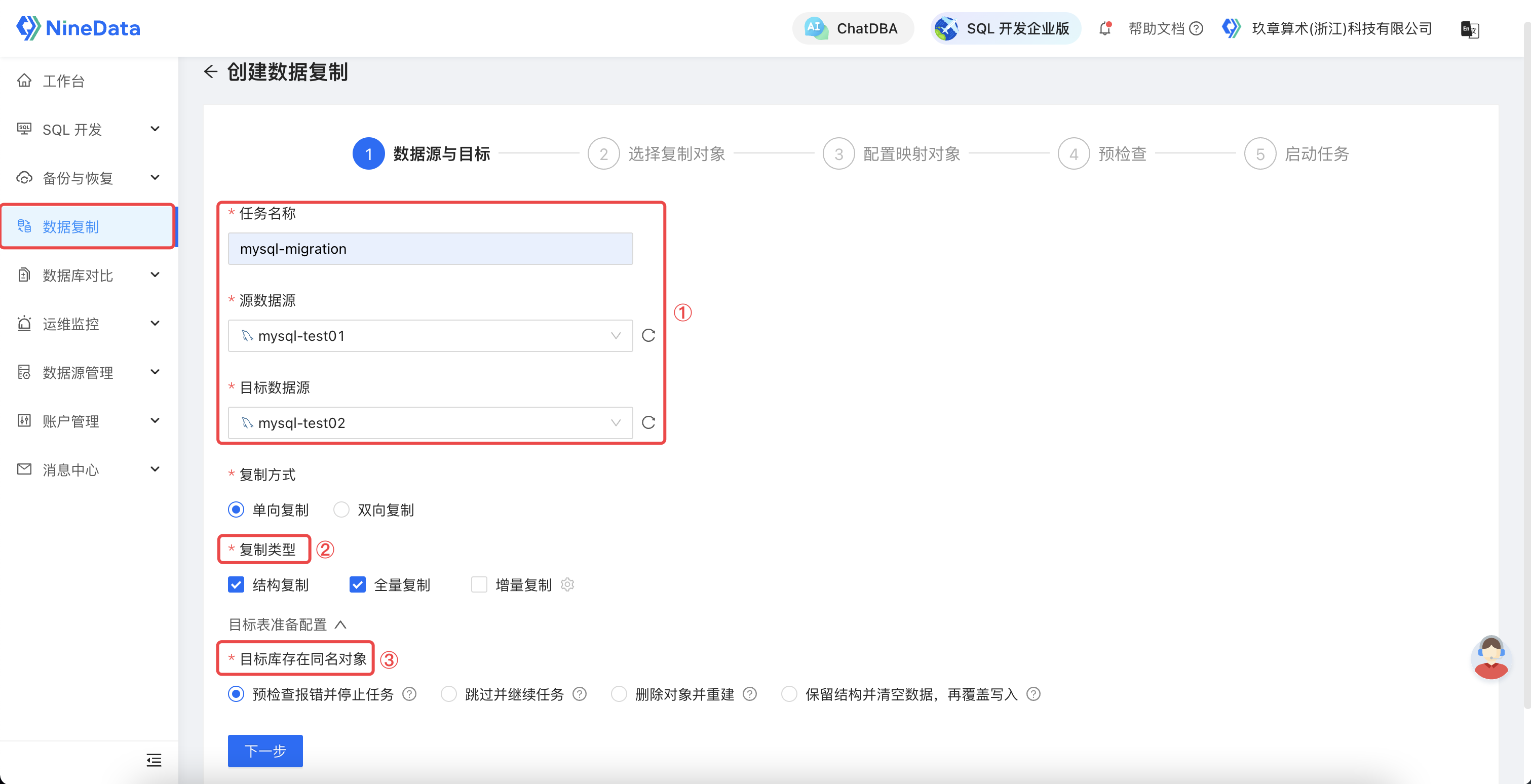
2.1 配置迁移链路
1. 配置任务名称,选择要迁移的源和目标实例。
2. 选择复制类型,数据迁移选择结构和全量复制(数据迁移)。
3. 根据需要,选择合适的冲突处理策略。
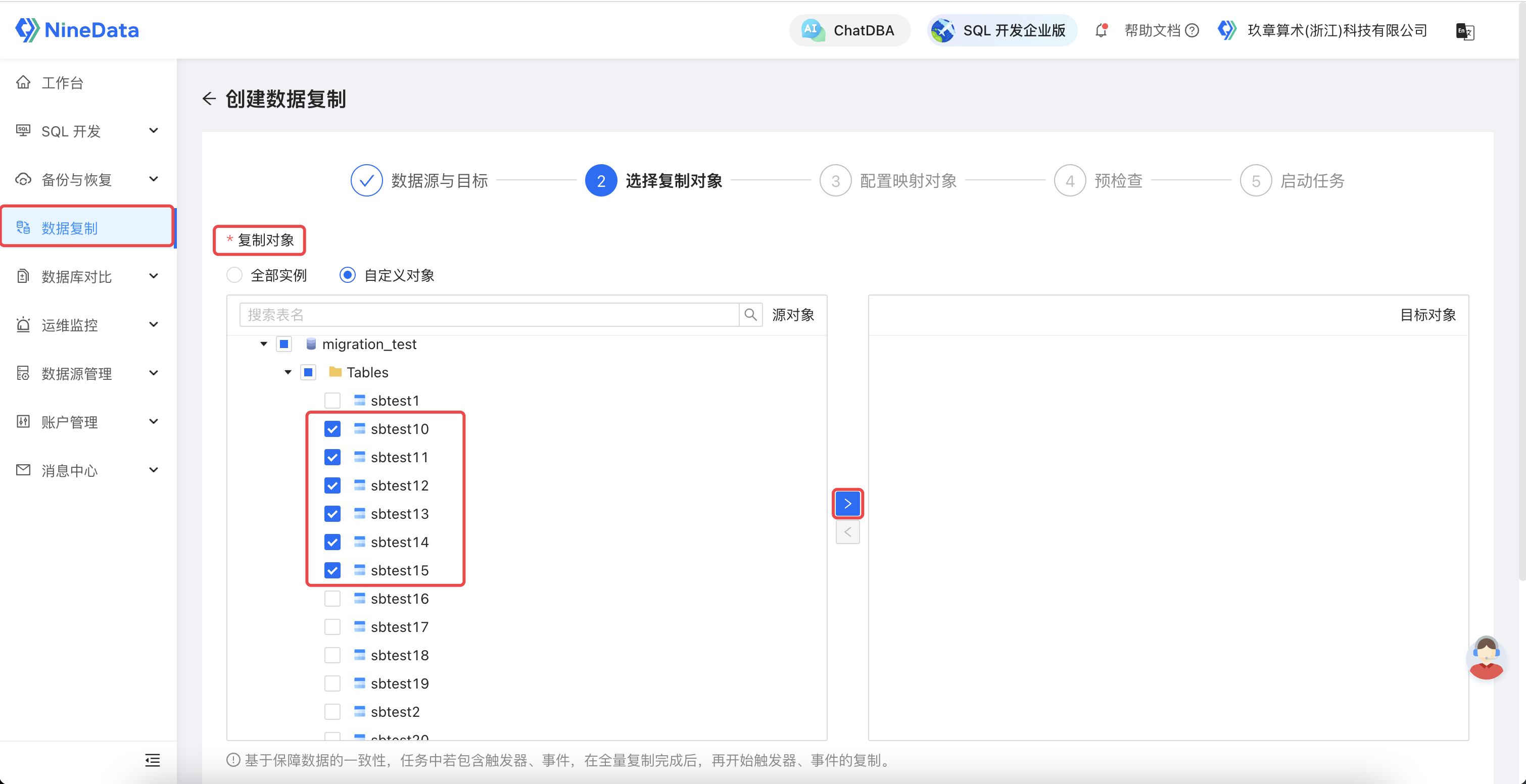
2.2 选择迁移对象
选择迁移对象:针对不同粒度选择迁移对象,也可以选择部分迁移对象。
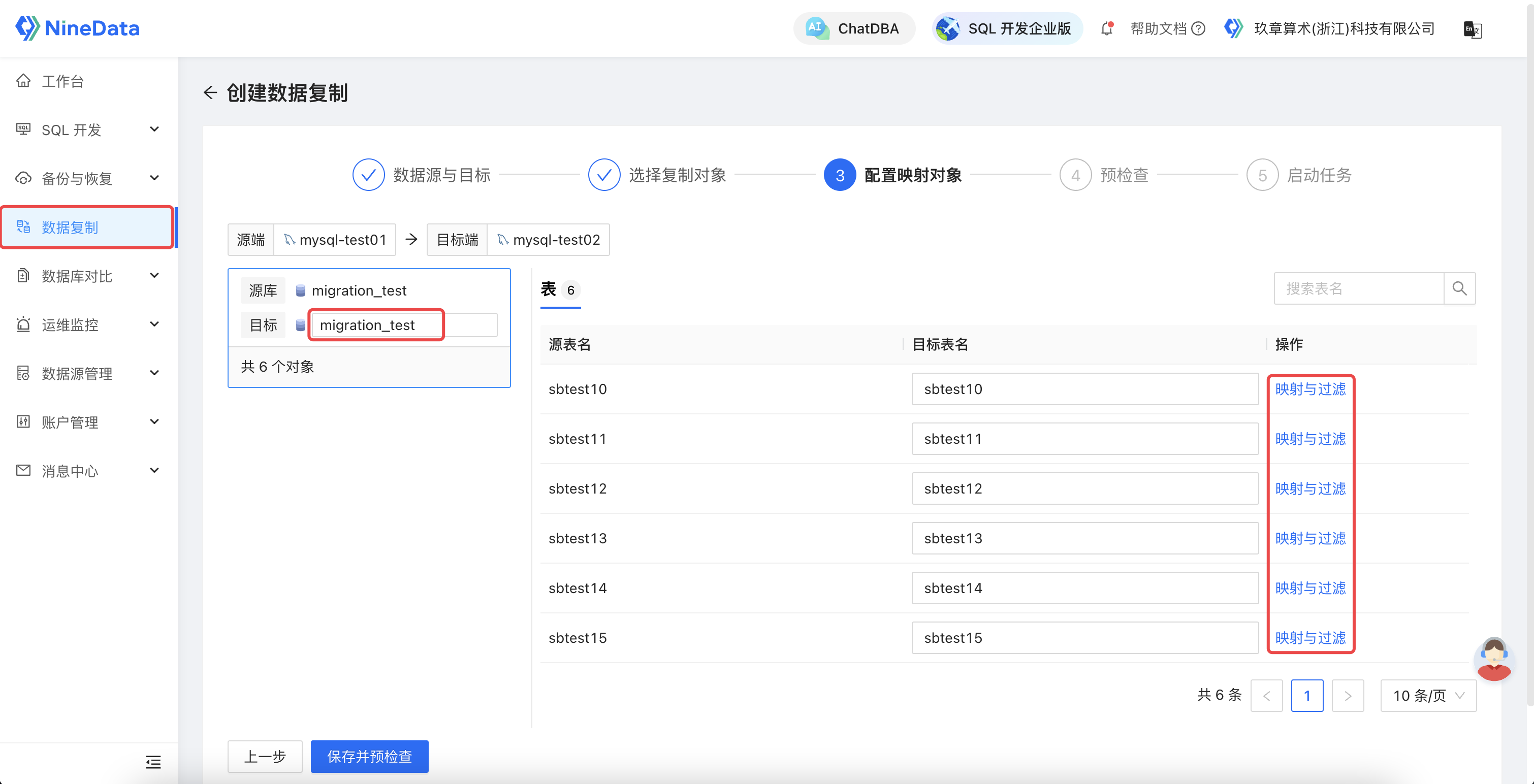
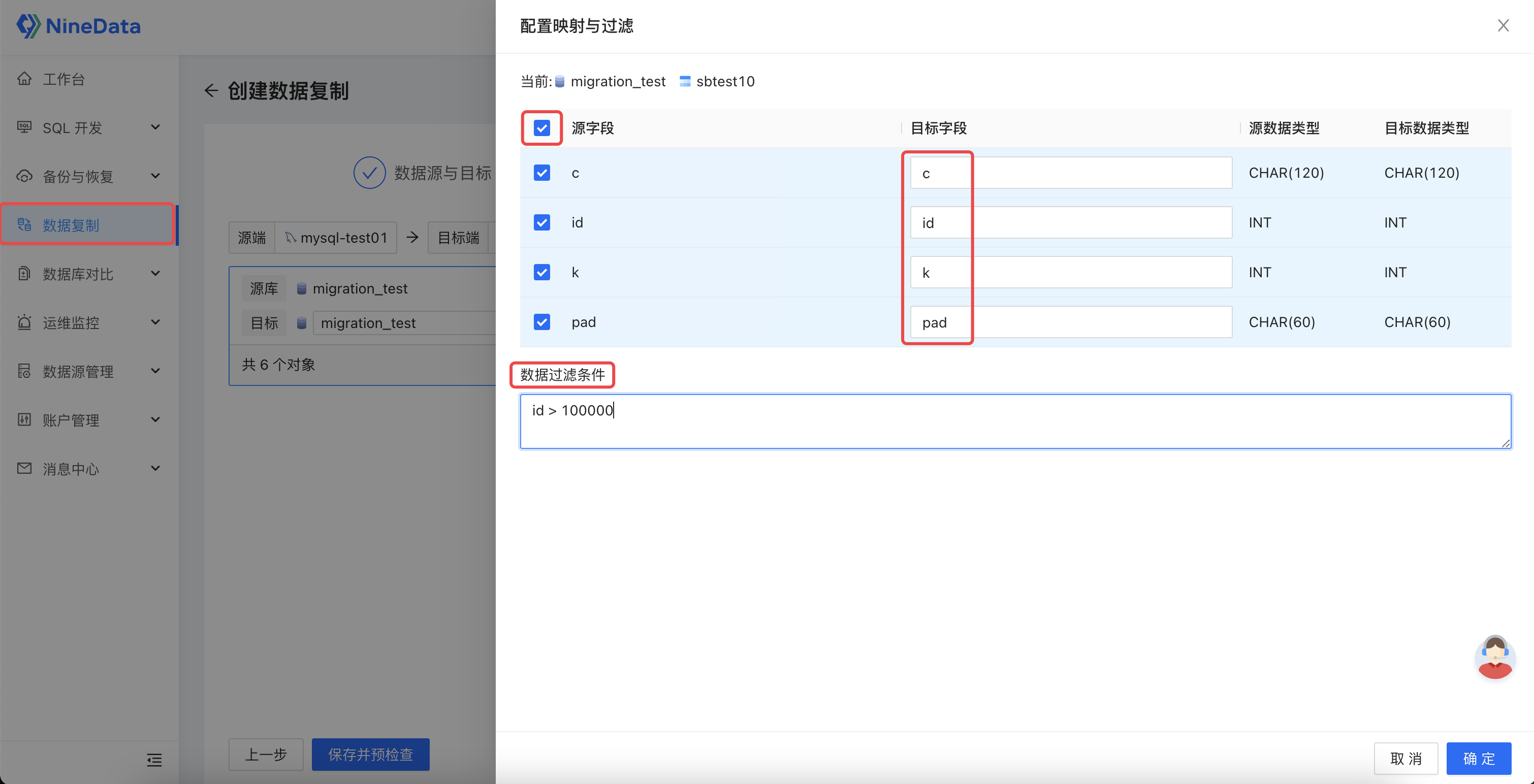
2.3 配置映射对象
配置映射和过滤规则:可自定义迁移的库名、表名和按照不同的过滤条件进行多表的部分数据迁移,也可以针对表的列名进行映射和部分列迁移。
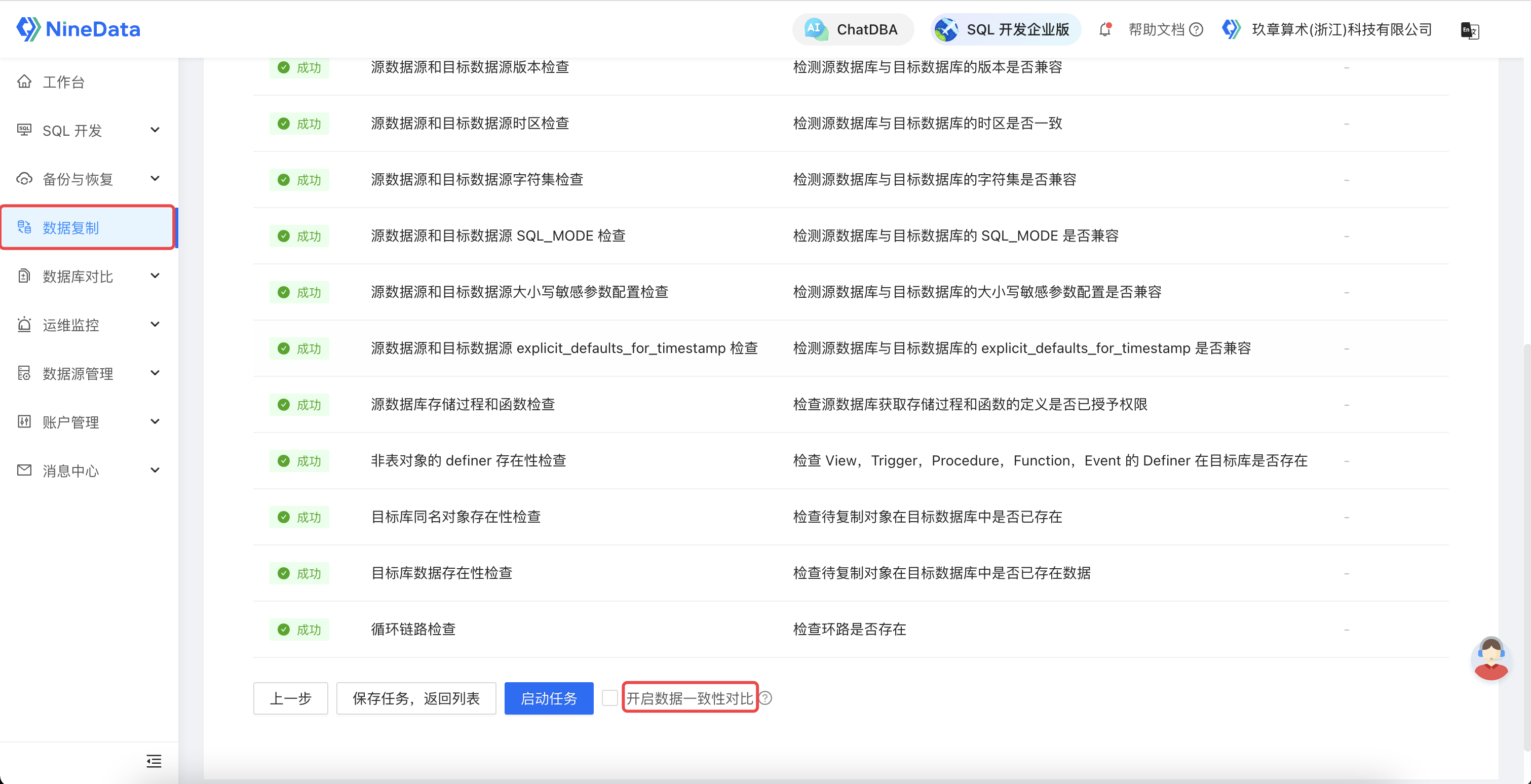
2.4 预检查 &启动
通过丰富的检查项,保证了迁移任务的稳定性;通过开启数据对比,保证了迁移后数据的一致性。到此,我们就完成了一个高性能迁移任务的配置。
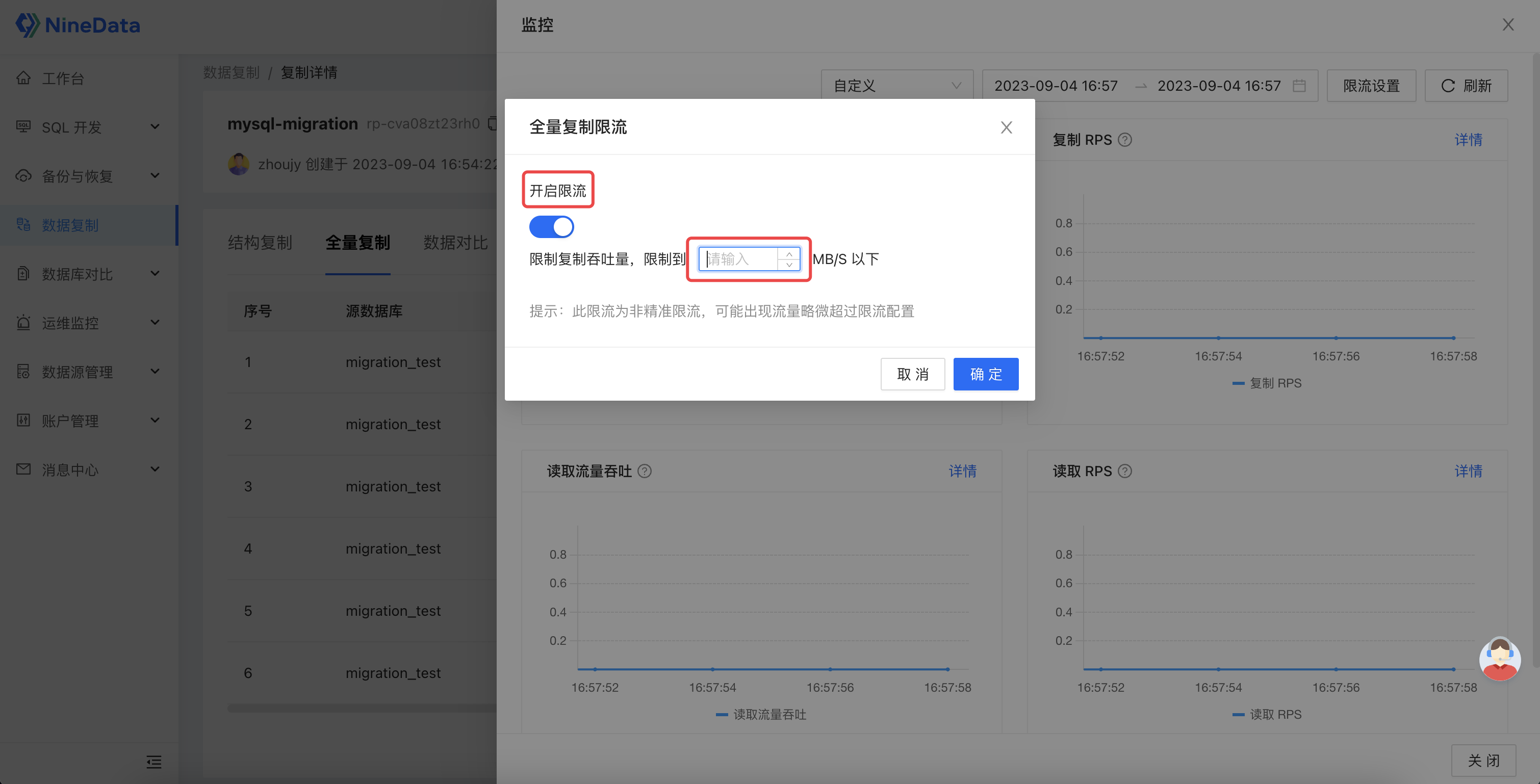
同时,为了提供更好的迁移体验,NineData 针对迁移过程提供了完善的观测、干预能力。其不但提供对象迁移的详细状态、进展、详情,还通过监控和日志透露后台线程的内部执行情况,帮助用户全方位追踪迁移进展。同时,还针对运行过程中可能出现的异常情况,提供基础诊断能力,及修复、跳过、移除等多种修复策略和迁移限流能力,让用户能够自主快速得诊断并修复链路,保障迁移稳定性。
3、总结
NineData 提供的高效、快速、稳定的 MySQL 大数据量迁移能力,很好的补充了传统迁移方案的不足。当前,NineData 已经支持数十种常见数据库的迁移复制,同时,除了 SAAS 模式外,还提供了企业专属集群模式,满足企业最高的数据安全合规要求。目前,NineData 已在运营商、金融、制造业、地产、电商等多个行业完成大规模应用实践。如果您感兴趣的话,可以登录官网:数据迁移-迁移工具-数据传输-NineData-玖章算术,立即开始使用。