编者按:随着大语言模型在自然语言处理中的广泛应用,如何提高其在实际部署中的推理速度成为一个非常关键的问题。
本文详细介绍了当前提高大语言模型推理速度的七大策略,包括使用低精度计算、模型量化、使用适配器微调、采用模型剪枝、批量推理、多 GPU 并行和采> 用其他推理优化工具等方法。这些方法各有利弊,作者通过具体的实例说明它们的使用效果,让读者比较清晰地了解当前这一领域的技术发展情况。
本文内容丰富全面,对那些想要将大语言模型应用到实际产品中的工程师有很强的参考价值。读者可以通过本文找出适合自己场景的推理优化策略,也可以进一步深入了解这一领域的最新进展。推荐对落地大语言模型应用感兴趣的读者阅读本文。
以下是译文,Enjoy!
作者 | Sergei Savvov 编译 | 岳扬
![]()
Image generated with Stable Diffusion
各类公司,不论是小型创业公司还是大型企业,都希望好好利用现代化的大语言模型,并将其融入到公司的产品和基础软件中。然而,这些公司一般都将遇到一个挑战:这些大模型在部署(推理)时需要消耗大量的算力资源。
加快模型推理速度已经成为开发者们所面临的一项重要挑战,这项挑战涉及到如何降低计算资源的费用以及如何提高应用的响应速度。
> “未来,大语言模型的推理速度每提高1%都将比拟谷歌搜索引擎推理速度提高1%的经济价值。” > > —— NVIDIA资深AI科学家Jim Fan
LLM(大语言模型)的开发和相关基础软件正在以惊人的速度[1]不断演进。每周都会出现模型压缩或加速的新方法。在如此迅猛的技术发展情况下,要跟上潮流并了解哪些技术是真正有效的,而不仅仅停留在理论的层面,确实是一项挑战。
我尝试去了解目前有哪些改进措施可以在具体项目中实施以及这些措施对LLM模型推理速度的加速效果。这样可以让我更好地把握当前的技术动态,并为具体项目选择最合适的优化方案。
01 “Short” Summary
![]()
![]()
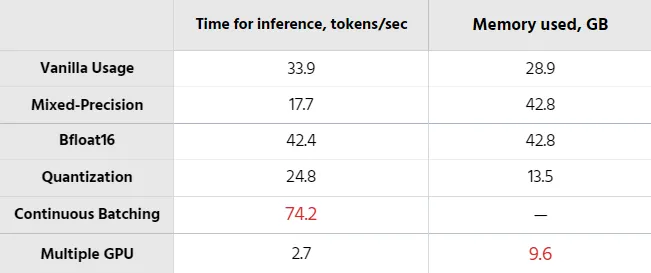
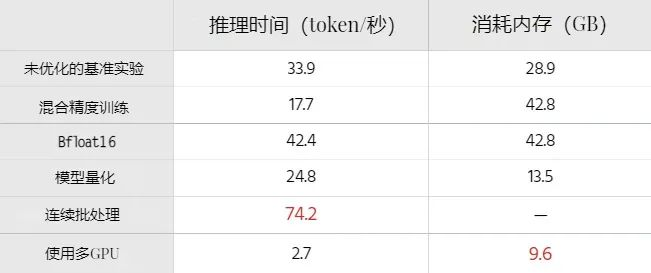
各种大模型的推理时间和内存消耗比较,A100 GPU 40GB
这篇文章有些长,以下是主要内容要点:
1.降低精度: 使用float16或bfloat16。这将使模型加速约20%,内存消耗减少2倍。
2.使用8位或4位量化: 使用8位或4位的模型量化方式可以将内存消耗减少2倍或3倍。这种方法对需要运行于内存受限的小型设备上的模型效果最好。需注意:量化会降低模型预测的质量。
3.使用adapters(LoRA [2] 、QLoRA [3] )进行微调, 能够提高模型在特定数据上的预测准确性和性能。与模型量化技术结合使用效果良好。
4.使用张量并行技术(tensor parallelism) 能够加速大模型在多GPU上的推理。
5.如果可能,尽可能使用LLM推理和服务库,如Text Generation Inference、DeepSpeed[4]或vLLM[5]。这些库已经包含了各种优化技术:张量并行(tensor parallelism)、模型量化(quantization)、对连续到达的请求进行批处理操作(continuous batching of incoming requests)、经过优化的CUDA核函数(optimized CUDA kernels)等等。
6.在将大模型投入生产环境之前进行一些初步测试。 我在使用某些库时花了很多时间去修复Bugs。此外,并非所有LLM都有可行的推理加速解决方案。
7.不要忘记评估最终的解决方案。 最好准备好数据集进行快速测试。
下面我们将开始详细讨论这些要点。
02 本文试验中的模型选择
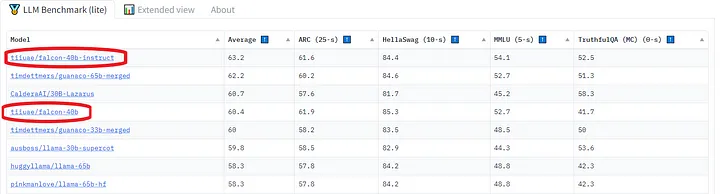
文本中提到的相关测试,我选择了Falcon[6],这是由Technology Innovation Institute[7]发布的一款最新的开源大语言模型。它是一个仅具备解码器功能的自回归模型,拥有两个版本:一个是70亿参数的模型,另一个是400亿参数的模型。400B模型变体经过了在AWS上使用384个GPU进行为期两个月的训练。
![]()
Open LLM Leaderboard.
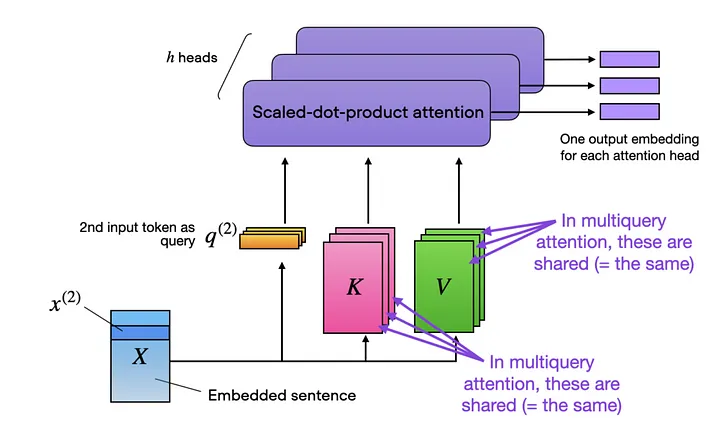
根据对该模型的了解[8],Falcon的架构与GPT-3和LLaMA非常相似,唯一的区别在于它使用了multiquery attention(Shazeer 2019[9])和选择了RefinedWeb[10]语料库作为训练数据集(这可能是该模型取得成功的关键所在[11])。
Multiquery attention通过在不同的注意力头(attention heads)之间共享相同的键张量和值张量(key and value tensors)来提高效率,下面是多头注意力模块(multihead attention block)的示意图:
![]()
Multiquery attention. https://lightning.ai/pages/community/finetuning-falcon-efficiently/
03 未优化的基准实验 Vanilla Usage
为了完成实验,我使用了 Lit-GPT 库[12]进行操作,其中包含了对最新开源 LLM 的可配置实现,并由 Lightning Fabric[13]提供支持。至于硬件配置,我使用了一块显存容量为40GB的A100 GPU。
下面开始实验,第一步是下载模型权重并将其转换为lit-gpt格式。直接执行以下脚本即可,这一步骤非常简单:
python scripts/download.py --repo_id tiiuae/falcon-7b
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/tiiuae/falcon-7b
要执行模型,只需运行以下程序即可:
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "32-true"
# Time for inference: 1.47 sec total, 33.92 tokens/sec
# Memory used: 28.95 GB
04 LLM 推理加速方法
3.1 使用 16 位精度
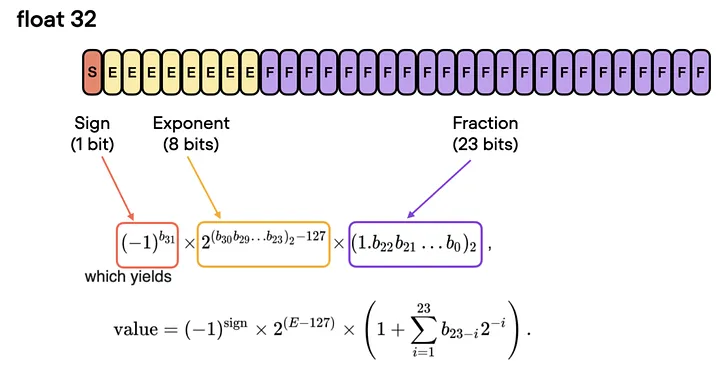
在使用GPU训练深度神经网络时,通常我们会使用低于最高精度的32位浮点运算(实际上,PyTorch就是默认使用32位浮点数)。在浮点表示法中,数值由三个组成部分构成:符号(the sign)、指数(the exponent)和有效数字(the significand)(或称为尾数 mantissa)。
![]()
单精度浮点运算格式[14]
一般来说,位数越多,精度越高,从而降低了计算过程中错误累积的几率。 然而,如果我们想要加快模型的训练速度,可以将精度降低到例如16位。这样做有以下几个好处:
1.减少显存占用:32 位精度所需的 GPU 显存是 16 位精度的两倍,而降低精度则能够更有效地利用GPU显存资源。
2.提高计算能力和计算速度:由于低精度张量(lower precision tensors)的操作所需的显存更少,因此GPU能够更快地进行计算处理,从而提高模型的训练速度。
Lit-GPT 使用 Fabric 库,只需几行代码就能改变精度。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-true"
# Time for inference: 1.19 sec total, 42.03 tokens/sec
# Memory used: 14.50 GB
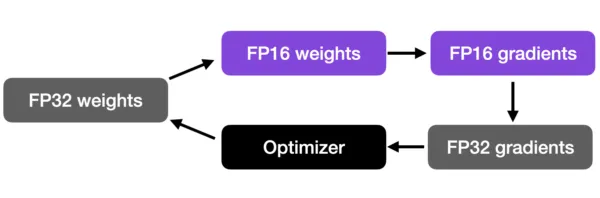
3.2 混合精度训练 Mixed-precision training
混合精度训练(Mixed-precision training)是一项比较重要的技术,可以较大地提高在GPU上的训练速度。这种方法并不会将所有参数和操作都转换为16位浮点数,而是在训练过程中在32位和16位之间切换操作,因此被称为“混合“精度。
![]()
混合精度方法[15]
这种方法可以在保持神经网络的准确性和稳定性的同时,进行高效训练。
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "16-mixed"
# Time for inference 1: 2.82 sec total, 17.70 tokens/sec
# Memory used: 42.84 GB
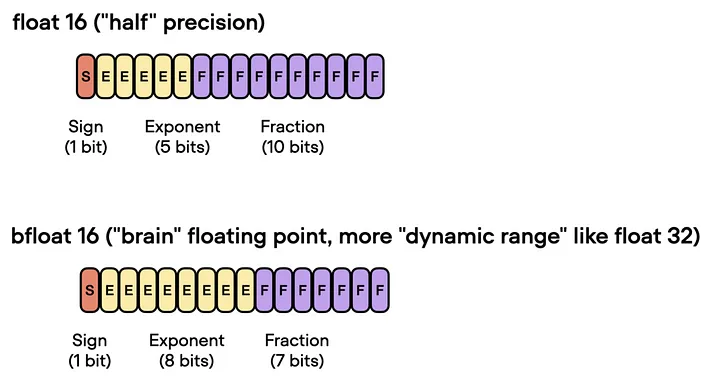
3.3 16位脑浮点(Brain Floating Point)
Bfloat16是由Google提出的一种浮点数格式,名称代表着“Brain Floating Point Format(脑浮点格式)”,其源自于Google旗下的Google Brain[16]人工智能研究小组。可以在此[17]了解更多关于Bfloat16的相关内容。
![]()
Bfloat16 Arithmetic.
Google为机器学习和深度学习应用,特别是在Tensor Processing Units(TPUs)中开发了这种格式。虽然 bfloat16 最初是为 TPU 开发的,但现在一些英伟达(NVIDIA)GPU 也支持这种浮点数格式。
python -c "import torch; print(torch.cuda.is_bf16_supported())"
如果您需要使用bfloat16,您可以运行以下命令:
python generate/base.py \
--prompt "I am so fast that I can" \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--max_new_tokens 50 \
--precision "bf16-true"
# Time for inference: 1.18 sec total, 42.47 tokens/sec
# Memory used: 14.50 GB
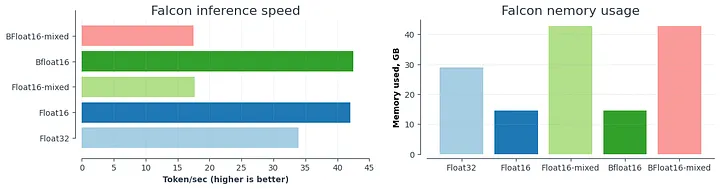
下图汇总了上述结果:
![]()
比较不同精度类型的推理速度和内存消耗
05 模型量化
如果我们想在推理时进一步提高模型性能,在使用较低的浮点精度之外,我们还可以使用量化技术。量化技术将模型权重从浮点数转换为低位整数表示,例如 8 位整数(甚至是 4 位整数)。 对深度神经网络应用量化技术通常有两种常见方法:
1. 训练后量化技术(PTQ) :首先对模型进行训练,使其收敛,然后在不继续进行训练的情况下将其权重转换为较低的精度。与模型训练相比,这一过程的实现成本通常很低。
2. 量化感知训练技术(QAT) :在预训练或进一步微调时应用量化。QAT的性能可能更好,但同时也需要更多的计算资源和具有代表性的训练数据。当我们想要加快现有模型的推理速度,我们应该使用训练后量化技术(Post-Training Quantization)。你可以在这里[18]阅读有关训练后量化(Post-Training Quantization)不同技术的更多信息。
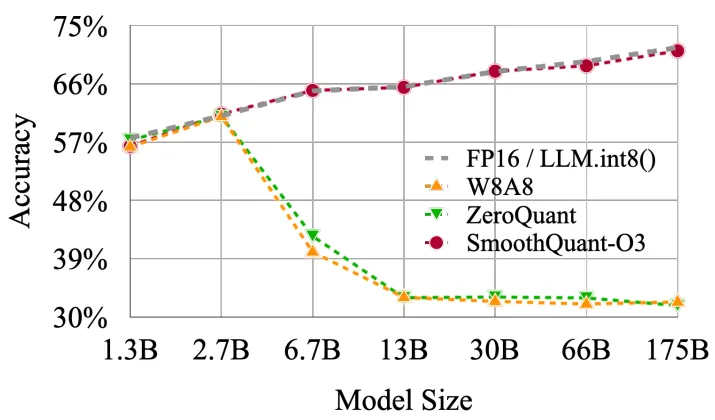
注:最近发表的一篇研究论文《SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models》[19]指出,并非所有的量化技术都适用于大语言模型(LLM)。 因此,在我们选择量化方法时需要谨慎考虑。我个人建议您阅读这篇文章《SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression》[20],该文章探讨了LLAMA和Falcon使用的量化技术。
![]()
使用不同量化技术的模型准确率下降程度与参数数量的关系。 Source: SmoothQuant: 《Accurate and Efficient Post-Training Quantization for Large Language Models》
鉴于目前Falcon模型尚未实现4位和8位的整数精度,所以接下来将使用Lit-LLaMA展示一个LLaMA 7B的案例。
python generate.py \
--prompt "I am so fast that I can" \
--quantize llm.int8
# Time for inference: 2.01 sec total, 24.83 tokens/sec
# Memory used: 13.54 GB
06 使用Adapters进行微调
虽然微调(fine-tuning)可能并非是一种加快最终模型推理过程的直接方法,但有几种技巧可以用来优化其性能:
1. 预训练和模型量化(Pre-training and Quantization) :首先在特定领域的问题上对模型进行预训练,然后进行模型量化。模型量化通常会导致模型质量略有下降,但最初的预训练可以稍微缓解这一问题。
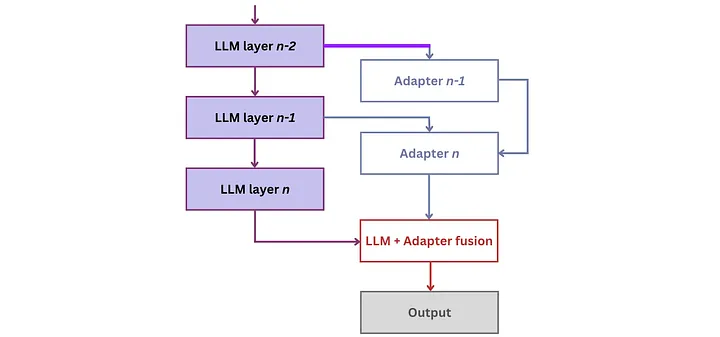
2. 小型适配器(Small Adapters) :另一种方法是为不同任务引入小型适配器。适配器的工作原理是在现有模型层中添加紧凑的额外层(compact additional layers),并仅针对它们进行训练。这些适配器层拥有轻量级参数(lightweight parameters),使得模型能够快速适应和学习。
通过结合使用这些方法,可以实现模型的效果增强。
![]()
基于适配器(adapter-based)的 LLM 知识注入架构[21]
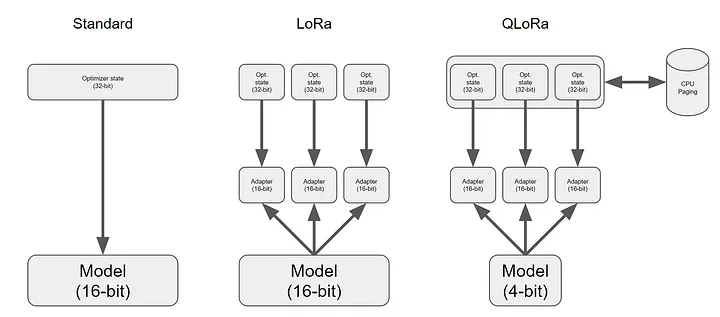
在适配器领域,出现了几种变体,包括LLaMA-Adapter(v1[22]、v2[23])、LoRa和QLoRa。其中,低秩自适应技术(Low-Rank Adaptation,LoRA) [24]表现最为突出。LoRA通过在LLM的每一层引入少量的可训练参数,即适配器,并同时冻结所有原始参数。这种方法简化了微调过程,只需更新适配器权重,大大降低了内存消耗。
QLoRA[25]方法是在LoRA的基础上增加了模型量化技术其他一些优化,彻底改变了我们在Google Colab实例上对模型进行微调的方式![26]
![]()
Adapter架构[27]
微调LLM可能需要耗费大量的资源,包括时间和算力。例如,如果使用8个A100 GPU对Falcon-7B进行微调,大约需要半小时左右,而如果只使用单个GPU,大约需要三个小时。 此外,为了获得最佳的微调结果,前期需要对数据集进行一些适当的准备工作。虽然我并没有亲自执行过模型的微调过程,但如果您想要自己动手,可以通过运行以下命令来启动微调过程(在这里[28]可以阅读更多相关信息):
python finetune/adapter_v2.py \
--data_dir data/alpaca \
--checkpoint_dir checkpoints/tiiuae/falcon-7b \
--out_dir out/adapter/alpaca
如需深入了解更多细节和详细信息,我推荐阅读以下内容:
- Understanding Parameter-Efficient Finetuning of Large Language Models: From Prefix Tuning to LLaMA-Adapters[29]
- Making LLMs even more accessible with bitsandbytes, 4-bit quantization, and QLoRA[30]
- Finetuning Falcon LLMs More Efficiently With LoRA and Adapters - Lightning AI[31]
- Colab notebook to fine-tune Falcon-7B on Guanaco dataset using 4bit and PEFT[32]
07 模型剪枝(Pruning)
网络剪枝(Network pruning)通过去除不重要的模型权重或连接来减小模型大小,且同时还保持着模型容量。
另一种新方法 LLM-Pruner[33] 能够根据梯度信息(gradient information)选择性地移除非关键的耦合结构(non-critical coupled structures),采用的是结构剪枝(structural pruning),最大程度地保留了大型语言模型的功能。作者展示压缩后的模型在零样本分类和生成(zero-shot classification and generation)方面表现良好。
(译者注:LLM-Pruner根据参数梯度判断重要性,通过移除不重要的模型结构部分来进行模型压缩。选择哪部分移除的依据是参数梯度的大小。)
![]()
Illustration of LLM-Pruner
LLM-Pruner这篇论文的作者公开了相关代码,但仅支持 LLaMA-7B[34] 和 Vicuna-7B[35] 这两个大语言模型。
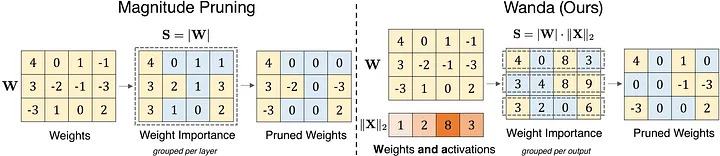
还有另一个有趣的剪枝器(pruner)——Wanda[36](根据权重值和激活值剪枝)。该方法会根据每个输出的基础,利用权重与对应输入激活值相乘的结果来剪枝权重。
![]()
与仅基于权重大小的幅值剪枝相比,Wanda的剪枝方式是基于每个输出的基础,通过权重大小与输入激活值范数的乘积来移除权重[36]
值得注意的是,Wanda不需要重新训练或更新权重,剪枝后的LLM可以直接使用。此外,它允许我们将LLM剪枝至原来大小的50%。
08 批量推理 Batch Inference
GPU以其大规模并行计算架构而闻名,在A100[37]上,模型的计算速率甚至以每秒万亿次浮点运算(teraflops)计量,而在像H100[38]这样的GPU上,模型甚至可达到每秒千万亿次浮点运算(petaflops)的水平。尽管有着巨大的计算能力,但由于GPU芯片的一大部分显存带宽被用于加载模型参数,LLM在如果想要充分发挥潜力经常面临困难。
其中一种有效的解决方法是使用批处理技术。与为每个输入序列加载新的模型参数不同,批处理只需要加载一次模型参数,并利用它们处理多个输入序列。这种优化策略高效利用了芯片的显存带宽,从而提高了算力利用率,改善了吞吐量,并使LLM推理更加经济高效。 通过采用批处理技术,可以显著提升LLM的整体性能。
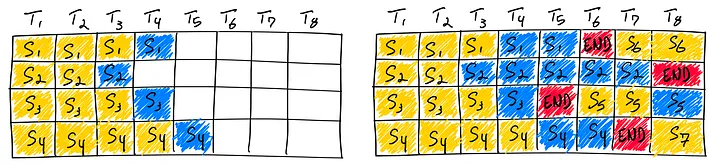
还有一种最近提出的优化方法——连续批处理(continuous batching) 。Orca实施了iteration-level scheduling,而不再需要等待批处理(batch)中的每个序列都完成生成,而是根据每次迭代来确定批大小(batch size)。这样做的结果是,一旦批中的一个序列完成生成,就可以插入一个新的序列,从而实现比静态批处理更高的GPU利用率。
![]()
使用连续批处理完成7个序列。左边显示通过一次迭代后的批处理结果,右边显示经过多次迭代后的批处理结果。
你可以在以下几个框架中使用这种算法:
-
Text Generation Inference[39]— 用于文本生成推理的服务端;
-
vLLM[40] — LLM的推理和服务引擎。
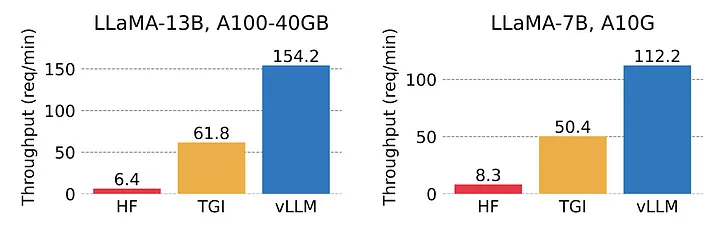
经过仔细评估,我选择了vLLM作为首选。vLLM采用了PagedAttention,这是一种新的注意力算法,可以有效地管理注意力键(keys)和值(values):在无需进行任何模型架构更改的情况下,它的吞吐量比HuggingFace Transformers高出多达24倍。
![]()
vLLM 的吞吐量比 HuggingFace Transformers (HF) 高 14 - 24 倍,比 HuggingFace Text Generation Inference (TGI) 高 2.2 - 2.5 倍。来源:https://vllm.ai/
考虑到 vLLM 无法支持 Falcon[41],我决定改用 LLaMA-7B。
from vllm import LLM, SamplingParams
prompts = [
"I am so fast that I can",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="huggyllama/llama-7b")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
# I am so fast that I can travel around the world in two hours. My first stop: the Southeast
# The capital of France is one of the most beautiful cities in the world. And it is no secret that
# The future of AI is in a future\nThis might sound like a depressing conclusion, but it
它出色的运行速度给我留下了深刻的印象。此外,该框架可以无缝地设置API服务器,实现快速部署。要启动该服务,请执行以下命令:
python -m vllm.entrypoints.api_server --model huggyllama/llama-7b
然后,您就可以使用下面这段代码来检查其功能了:
time curl http://localhost:8000/generate \
-d '{
"prompt": "I am so fast that I can",
"temperature": 0,
"use_beam_search": true,
"n": 4,
}'
# 🚀 real 0m0.277s
# I am so fast that I can take through a story three get back before I started.
# I am so fast that I can turn around a Earth in come back for lunch.
# I am so fast that I can finish on the earth, still be for lunch.\nI am so fast
# I am so fast that I can run around the world and grab my own feet start.
您可以在这里[42]找到关于批量推理更详细的评测和基准测试。
09 使用多GPU
还可以使用全分片数据并行(Fully-Sharded Data Parallel,FSDP)分布式策略来利用多个GPU设备执行推理。重要的是要明白,使用多个GPU设备并不会加速推理过程,但可以通过将模型分片到多个设备上运行,使得那些无法在单张显卡上运行的模型变得能够运行。
例如,falcon-40b模型在单个设备上运行需要约80GB的GPU显存。如果我们在2张A6000(48GB)上运行它,仍然使用Lit-GPT,并只需对参数进行一些小幅调整:
python generate/base.py \
--checkpoint_dir checkpoints/tiiuae/falcon-40b \
--strategy fsdp \
--devices 2 \
--prompt "I am so fast that I can"
# Time for inference: 83.40 sec total, 0.60 tokens/sec
# Memory used: 46.10 GB
这将占用46GB的内存并以0.60个token/秒的速度运行。
![]()
使用全分片数据并行技术前后的性能比较
或者,我们可以使用 vLLM,仅通过将 tensor_parallel_size 设置为 2,就可以以更快的速度生成文本。
prompts = [
"I am so fast that I can",
"The capital of France is",
"The future of AI is",
]
llm = LLM(model="huggyllama/llama-30b", tensor_parallel_size=2)
output = llm.generate(prompts, sampling_params)
# 🚀 It takes only 0.140 seconds!
# I am so fast that I can travel back in time and eat my breakfast before I eat my breakfast!
# The future of AI is up to you.
10 附加部分:部署LLM模型服务
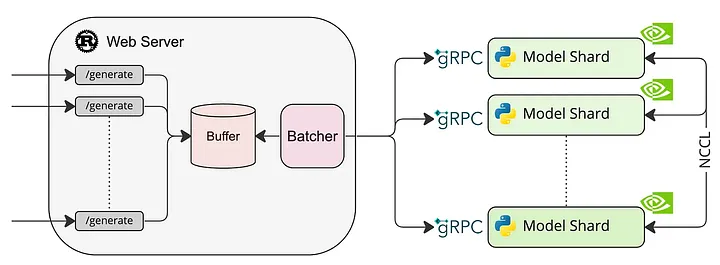
由于 vLLM 不支持 Falcon,我决定展示如何使用Text Generation Inference[39]来轻松部署模型。
![]()
Text Generation Inference架构
为了遵循框架作者推荐的最佳框架使用方法,建议执行提供的命令,在 Docker 容器内运行应用程序。运行 docker 容器命令如下:
docker run --gpus all --shm-size 1g -p 8080:80 \
-v $PWD/data:/data ghcr.io/huggingface/text-generation-inference:0.8 \
--model-id tiiuae/falcon-40b --num-shard 1 --quantize bitsandbytes
请注意,Falcon-7B 不支持张量并行[43]。因此,必须将参数 num_shard 设置为 1,以确保功能正常。
根据我的经验,在这个过程中,大约需要花费两分钟来下载Docker镜像、需要耗费30秒来下载scales。随后,将scales从.bin格式转换为.safetensors格式大约需要20秒。最后,下载最终的模型需要大约一分钟的时间。
您可以使用以下命令来检查API的运行情况:
time curl http://localhost:8080/generate \
-X POST \
-d '{"inputs":"I am so fast that I can","parameters":{"max_new_tokens":50}}' \
-H 'Content-Type: application/json'
# real 0m3.148s
# I am so fast that I can do two things at the same time.
LLM推理的其他备选库:
1.Accelerate[44]:该库允许将模型的部分工作负载转移到CPU上。即使整个模型都适合在GPU上运行,仍然可以通过将部分计算任务转移,优化推理服务的吞吐量。
2.DeepSpeed Inference[45]:这个库能够在以下情况下更高效地为基于Transformer的模型提供服务:(a) 模型适合在GPU上运行,以及 (b) DeepSpeed库支持模型内核。如果需要重点关注延迟问题,这个解决方案您可以选择。
3.DeepSpeed MII[46]:这是一个可以快速设置GRPC终端节点用于模型推理的库,可以选用ZeRO-Inference或DeepSpeed Inference技术。
4.OpenLLM[47]:这是一个用于在生产环境中运行大语言模型(LLMs)的开放平台。可以轻松地微调、部署、服务和监控任何LLMs。
5.Aviary[48]:这是一个新的开源项目,可以有效地简化和启用多个LLM模型的自托管服务。
欲了解更多信息,请在这里[49]阅读更多资料。
11 总结
LLM推理加速领域情况比较复杂,目前仍处于初级阶段。在准备本文时,我发现了许多最近被开发的方法,其中一些看起来十分有潜力(这些方法都出现在最近1-2个月内)。
然而,需要注意的是,并非所有的推理加速方法都能稳妥地发挥作用。有些方法甚至可能会降低模型的质量。 因此,盲目接受和应用所有的推理加速建议是不明智的,必须经过慎重考虑。 您必须保持谨慎,控制加速模型(the accelerated model)的质量。
理想情况下,在软件优化(software optimization)和模型架构(model architecture)之间取得平衡是实现LLM推理高效加速的关键。
END
参考资料
1.https://twitter.com/Yampeleg/status/1671890153412116485?s=20
2.https://arxiv.org/abs/2106.09685
3.https://arxiv.org/abs/2305.14314
4.https://github.com/microsoft/DeepSpeed
5.https://github.com/vllm-project/vllm
6.https://falconllm.tii.ae/
7.https://tii.ae/
8.https://huggingface.co/tiiuae/falcon-40b
9.https://arxiv.org/abs/1911.02150
10.https://huggingface.co/datasets/tiiuae/falcon-refinedweb
11.https://arxiv.org/abs/2306.01116
12.https://github.com/Lightning-AI/lit-gpt
13.https://lightning.ai/docs/fabric/stable/
14.https://en.wikipedia.org/wiki/Single-precision_floating-point_format
15.https://lightning.ai/pages/community/tutorial/accelerating-large-language-models-with-mixed-precision-techniques/
16.https://www.wikiwand.com/en/Google_Brain
17.https://nhigham.com/2020/06/02/what-is-bfloat16-arithmetic/
18.https://lilianweng.github.io/posts/2023-01-10-inference-optimization/#quantization
19.https://arxiv.org/abs/2211.10438
20.https://arxiv.org/abs/2306.03078
21.https://arxiv.org/abs/2212.08120
22.https://arxiv.org/abs/2303.16199
23.https://arxiv.org/abs/2304.15010
24.https://arxiv.org/abs/2106.09685
25.https://arxiv.org/abs/2305.14314
26.https://huggingface.co/blog/4bit-transformers-bitsandbytes
27.https://towardsdatascience.com/qlora-fine-tune-a-large-language-model-on-your-gpu-27bed5a03e2b
28.https://lightning.ai/pages/blog/falcon-a-guide-to-finetune-and-inference/
29.https://lightning.ai/pages/community/article/understanding-llama-adapters/
30.https://huggingface.co/blog/4bit-transformers-bitsandbytes
31.https://lightning.ai/pages/community/finetuning-falcon-efficiently/
32.https://colab.research.google.com/drive/1BiQiw31DT7-cDp1-0ySXvvhzqomTdI-o?usp=sharing
33.https://arxiv.org/abs/2305.11627
34.https://huggingface.co/docs/transformers/main/model_doc/llama
35.https://arxiv.org/abs/2306.11695
36.https://github.com/locuslab/wanda
37.https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf
38.https://resources.nvidia.com/en-us-tensor-core/nvidia-tensor-core-gpu-datasheet
39.https://github.com/huggingface/text-generation-inference
40.https://github.com/vllm-project/vllm
41.https://github.com/vllm-project/vllm/discussions/197#discussioncomment-6253548
42.https://www.anyscale.com/blog/continuous-batching-llm-inference
43.https://github.com/huggingface/text-generation-inference/issues/418#issuecomment-1579186709
44.https://github.com/huggingface/accelerate
45.https://github.com/microsoft/DeepSpeed
46.https://github.com/microsoft/DeepSpeed-MII
47.https://github.com/bentoml/OpenLLM
48.https://www.anyscale.com/blog/announcing-aviary-open-source-multi-llm-serving-solution
49.https://preemo.medium.com/squeeze-more-out-of-your-gpu-for-llm-inference-a-tutorial-on-accelerate-deepspeed-610fce3025fd
原文链接:
https://betterprogramming.pub/speed-up-llm-inference-83653aa24c47