以 ChatGPT 为代表的 AIGC 技术为企业生产带来了巨大的变化,并在企业应用开发领域占据一席之地。AI 大模型凭借其强大的学习能力,可以帮助人们完成各种复杂的任务,例如帮助开发人员编写与调试代码、研究人员快速了解科研领域、营销人员撰写产品描述、设计人员设计新作品等等。许多企业探索如何降低 AI 大模型的使用成本,通过网关进行 AI 大模型的 API 管理成为了很常规的需求。
Higress 如何降低 AI 大模型使用成本?
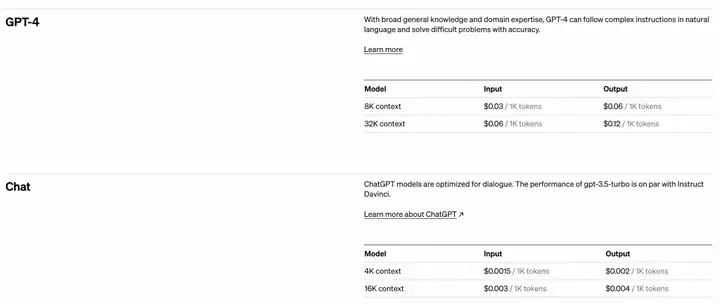
以 OpenAI 为例,OpenAI 的 API 调用并不是基于请求量或者订阅时间来计费,而是基于每个请求的使用量来计费。对于 AI 大模型来说,模型输入与输出的 token 数可以比较好的衡量当前模型进行推理任务的复杂度。因此基于 token 作为请求使用量进行计费是 OpenAPI 的标准计费策略。对于不同的模型 token 的计费标准也不同,越复杂的模型会生成越好的结果,但也会带来更高的计费。OpenAI 通过为用户分发 API 密钥来完成用户的鉴权与收费等功能。
![]()
对于组织来说,为每位成员申请 AI 大模型的访问权限(API Key)显然是不现实的。分散的 API 密钥将不利于组织进行 API 的用量计算、管理与付费,从而增加 AI 大模型的使用成本。其次,对于组织来说,AI 模型的选型、使用频率和成员使用权限、以及向 AI 大模型暴露哪些数据都是在管理中需要着重关注的功能。
Higress 基于丰富的插件能力,提供认证鉴权、请求过滤、流量控制、用量监测和安全防护等功能,帮助组织与 AI 大模型的 API 交互变得更加安全、可靠和可观察:基于 Higress 提供的认证鉴权能力,组织可以实现通过统一的 API 密钥进行 AI 模型的调用量管理和付费等,并为团队成员授予不同的AI模型访问权限;基于 Higress 提供的流量控制能力,组织能为不同的模型与用户设置差异化的访问速率限制,有效降低 AI 模型的使用成本;基于 Higress 提供的请求拦截能力,组织能够有效过滤含敏感信息的访问请求,防护部分内部站点资源不对外暴露,从而有效保障内部数据安全;基于商业版 Higress[1]提供的开箱即用的指标查询和日志记录的能力,组织能够完成对不同用户的 AI 模型调用的用量观测与分析,从而制定更加合理的AI模型使用策略。
Higress 对接 OpenAI 大语言模型实战
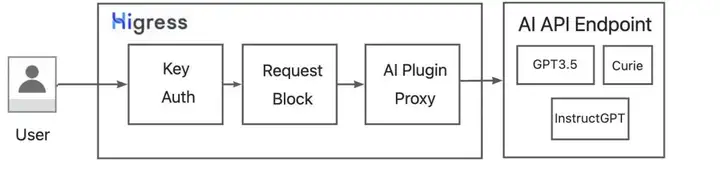
下面我们将以 Higress 对接 OpenAI 大语言模型为例,介绍 Higress 如何无缝对接 AI 大模型。整体方案如图所示,我们基于 WASM 拓展了 Higress 插件,实现了对 OpenAI 语言模型的请求代理转发。基于 Higress 提供的 Key Auth 认证插件的能力,我们实现统一 API-Key 下的多租户认证。基于 Higress 提供的 Request Block 请求过滤的能力,我们将实现含敏感信息的请求拦截,保障用户数据安全。
![]()
前提条件
- 安装 Higress,参考 Higress 安装部署文档[2]
- 准备 Go 语言开发 WASM 插件的开发环境,参考使用 GO 语言开发 WASH 插件[3]
基于 WASM 的 AI Proxy Plugin
下文将给出基于 Higress 与 WASM 实现的 AI 大模型 API 代理插件方案。Higress 支持基于 WASM 实现对外扩展的能力。WASM 插件提供的多语言生态和热插拔机制为插件的实现和部署提供了便利。Higress 同时支持在插件中请求外部服务,为 AI 代理插件的实现提供了高效的解决路径。
实现示例
我们给出 OpenAI-API 的代理插件的实现示例,详情请参考 AI proxy plugin[4]。下列代码实现了插件相关配置完成之后,基于 HTTP 自动将请求代理转发到 OPENAI-API,并接收来自 OPENAI-API 的响应,从而完成 AI 模型的调用。具体实现步骤如下:
1. 通过 RouteCluster 方法指定具体的 OPENAI-API 的 host,确认用户请求转发的具体路径,并新建用于请求代理转发的 HTTP Client。
func parseConfig(json gjson.Result, config *MyConfig, log wrapper.Log) error {
chatgptUri := json.Get("chatgptUri").String()
var chatgptHost string
if chatgptUri == "" {
config.ChatgptPath = "/v1/completions"
chatgptHost = "api.openai.com"
} //请求默认转发到OPEN AI API
...
config.client = wrapper.NewClusterClient(wrapper.RouteCluster{
Host: chatgptHost,
}) //通过RouteCluster方法确认请求转发的具体host
...
}
2. 对用户请求进行 OPENAI-API 的格式封装,通过 HTTP Client 进行请求转发与响应接受,并将响应转发给用户。
//OPENAI API接收的请求体模版,详见:https://platform.openai.com/docs/api-reference/chat
const bodyTemplate string = `
{
"model":"%s",
"prompt":"%s",
"temperature":0.9,
"max_tokens": 150,
"top_p": 1,
"frequency_penalty": 0.0,
"presence_penalty": 0.6,
"stop": ["%s", "%s"]
}
`
func onHttpRequestHeaders(ctx wrapper.HttpContext, config MyConfig, log wrapper.Log) types.Action {
...
//根据用户的请求内容进行OPENAI API请求体封装
body := fmt.Sprintf(bodyTemplate, config.Model, prompt[0], config.HumainId, config.AIId)
//通过HTTP Client进行转发
err = config.client.Post(config.ChatgptPath, [][2]string{
{"Content-Type", "application/json"},
{"Authorization", "Bearer " + config.ApiKey},
}, []byte(body),
func(statusCode int, responseHeaders http.Header, responseBody []byte) {
var headers [][2]string
for key, value := range responseHeaders {
headers = append(headers, [2]string{key, value[0]})
}
//接收来自于OPENAI API的响应并转发给用户
proxywasm.SendHttpResponse(uint32(statusCode), headers, responseBody, -1)
}, 10000)
...
}
在 Higress 中启用自定义的 AI-Proxy-Wasm 插件流程如下:
![]()
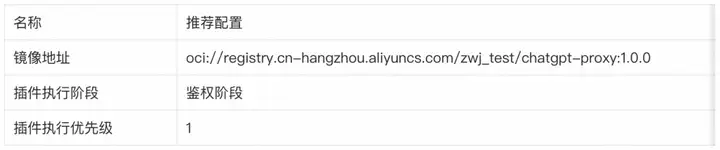
本示例提供已经编译好的 AI-proxy-plugin-wasm 文件并完成对应 docker 镜像的构建和推送,推荐配置如下所示:
![]()
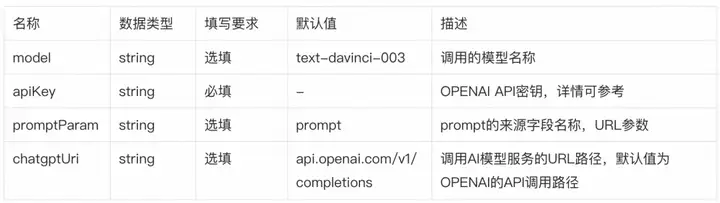
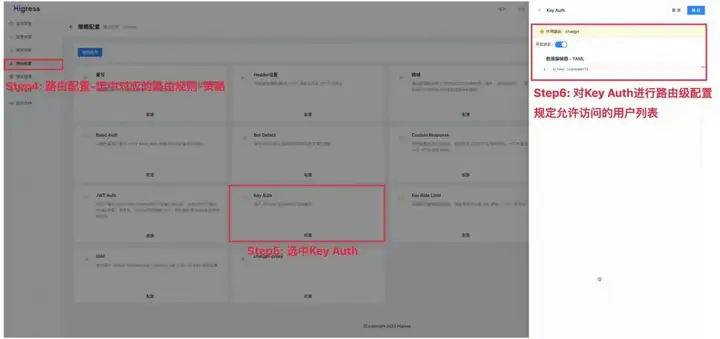
插件配置说明
插件配置简单,支持全局/域名级/路由级的代理转发。推荐进行路由级配置:选中对应的路由配置-选中对应路由-策略-启用插件。配置字段包括:
![]()
示例配置如下:
AI-Proxy-Plugin-Config
apiKey: "xxxxxxxxxxxxxxxxxx"
model: "curie"
promptParam: "text"
根据该配置,网关代理到 OpenAI API 下的 curie 模型,用户通过 text 关键字在 url 中输入文本。
curl "http://{GatewayIP}/?text=Say,hello"
得到 OpenAI API 的响应:
![]()
基于 Key Auth 的多租户认证
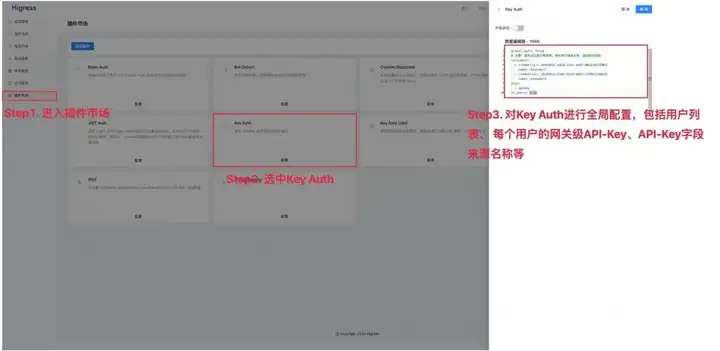
不同于为每位成员颁发 AI-API 密钥的形式,企业可以基于 Higress 网关提供的认证鉴权能力,依靠内部授权(如 Key Auth 等)来管理成员对 AI 模型对访问权限,从而限制成员可以使用的服务和模型,并依靠统一的 AI-API 密钥进行请求代理转发实现对 API 用量的统一管理。接下来以 Key Auth 为例介绍基于 Higress 的多租户认证能力。
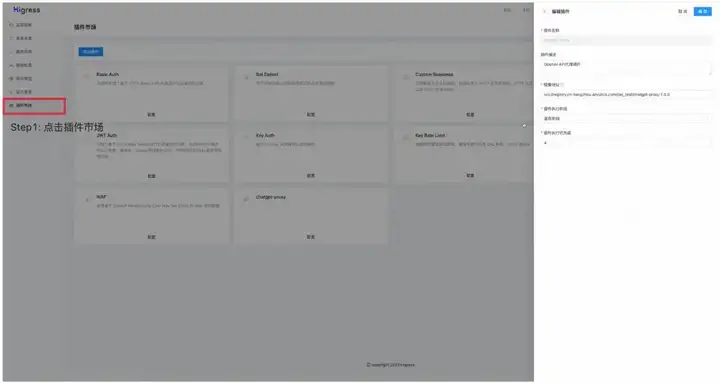
Key Auth 插件实现了基于网关内 API Key 进行认证和鉴权的功能,支持从 HTTP 请求的 URL 参数或者请求头解析 API Key,同时验证该 API 是否有权限访问。通过在 Higress 控制台-插件市场-Key Auth 进行全局配置和路由级配置,即可实现 Higress 网关的多租户认证。
![]()
Key-Auth 全局配置样例
#以下配置
consumers:
- credential: "xxxxxx"
name: "consumer1"
- credential: "yyyyyy"
name: "consumer2"
global_auth: false
in_header: true
keys:
- "apikey"
![]()
Key-Auth 的路由级配置样例
allow: [consumer1]
以上配置定义了指向 AI 模型服务的消费者组 consumers,并且只有 consumer1 具备访问当前路由下 AI 模型服务的权限。
curl "http://{GatewayIP}/?text=Say,hello"
#请求未提供 API Key,返回401
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:zzzzzz"
#请求提供的 API Key 未在消费者组内,无权访问,返回401
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:yyyyyy"
#根据请求提供的 API Key匹配到的调用者无AI模型服务的访问权限,返回403
curl "http://{GatewayIP}/?text=Say,hello" -H "apikey:xxxxxx"
#请求合法且有AI模型服务访问权限,请求将被代理到AI模型,正常得到OpenAI API的响应
Higress 除了提供网关级多租户认证外,提供限流等能力。Key Rate Limit 插件可以根据用户在消费组中的成员资格对用户应用速率进行限制,从而限制关键应用程序对高成本 AI 大模型服务的消耗。基于多租户认证插件与限流等功能插件能力,Higress 可以完全控制 AI 大模型 API 的访问权限、访问数量与调用成本。
基于 Request Block 保障数据安全
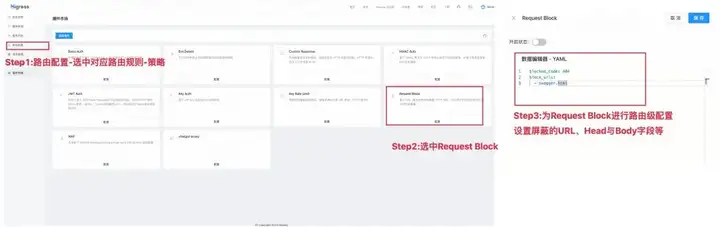
对于 AI 大模型尤其是语言模型来说,要得到良好的返回往往需要用户提供足够的提示(prompt)作为模型输入。这也意味着组织和个人可能会在提供提示的过程中面临数据泄漏的风险。因此如何在使用 AI 模型的过程中保障数据安全也是 API 调用方面临重要问题。保护数据安全涉及到对 AI 模型的 API 调用渠道进行严格的控制。一种方式是使用特定的经批准的模型与其发布的 API。另一种方式是对含敏感信息的用户请求进行拦截。这可以通过在网关级别设置特定的请求拦截来实现。Higress 基于 Request Block 插件提供请求拦截能力,既能防止未经授权的模型访问用户信息,同时防止含敏感信息的用户请求暴露到外网。
Request Block 插件实现了基于 URL、请求头等特征屏蔽 HTTP 请求,可以用于防护部分站点资源不对外部暴露。通过在 Higress 控制台-插件市场-Request Block 进行屏蔽字段配置,即可防止含敏感字段的请求对外发送。
![]()
Request Block 路由级配置样例
blocked_code: 404
block_urls:
- password
- pw
case_sensitive: false
以上配置定义了当前路由下基于 URL 的屏蔽字段,其中含敏感信息(如 password、pw)的请求将被屏蔽。
curl "http://{GatewayIP}/?text=Mypassword=xxxxxx" -H "apikey:xxxxxx"
curl "http://{GatewayIP}/?text=pw=xxxxxx" -H "apikey:xxxxxx"
#上述请求将被禁止访问,返回404
基于商业版 Higress 的用量观测与分析
对于组织来说,进行对各用户进行 AI 模型调用的用量观测和分析有助于了解其使用情况与产生的成本。对于个人用户了解自己的调用量和开销也是必要的。因此,在网关层进行调用的观测和分析对于 AI 大模型的 API 管理是必要的能力。商业版 Higress 与各种指标与日志系统进行了深度集成,提供了开箱即用的用量观测分析报告构建机制,可以实时查看各种 API 的使用情况,并根据各类参数进行过滤,从而更好的了解 API 使用情况。
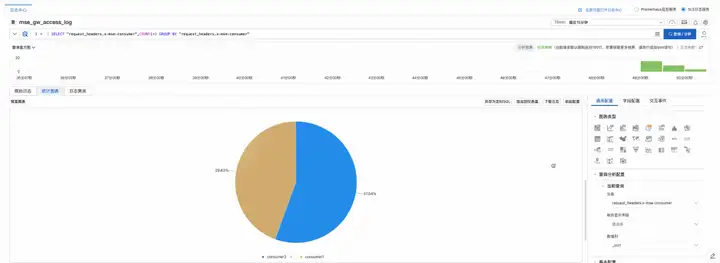
以观察各用户对 OPENAI-Curie 模型的调用量为例,用户可通过 MSE 管理控制台-云原生网关-网关实例-参数配置-日志格式调整中设置区分用户的可观测性参数请求头:x-mse-consumer,将其列入观测列表。之后进入观测分析-日志中心中设置使用统计图表功能即可完成对 API 的用量观测和分析。如下图所示,用户 comsumer1 与用户 consumer2 的对 OPENAI-Curie 模型的调用量以饼状图形式呈现。
![]()
作者:赵伟基(兆维)
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。