![]()
自然场景的文本检测是当前深度学习的重要应用,在之前的文章中已经介绍了基于深度学习的文本检测模型CTPN、SegLink(见文章:大话文本检测经典模型CTPN、大话文本检测经典模型SegLink)。典型的文本检测模型一般是会分多个阶段(multi-stage)进行,在训练时需要把文本检测切割成多个阶段(stage)来进行学习,这种把完整文本行先分割检测再合并的方式,既影响了文本检测的精度又非常耗时,对于文本检测任务上中间过程处理得越多可能效果会越差。那么有没有又快、又准的检测模型呢?
一、EAST模型简介
本文介绍的文本检测模型EAST,便简化了中间的过程步骤,直接实现端到端文本检测,优雅简洁,检测的准确性和速度都有了进一步的提升。如下图:
![]()
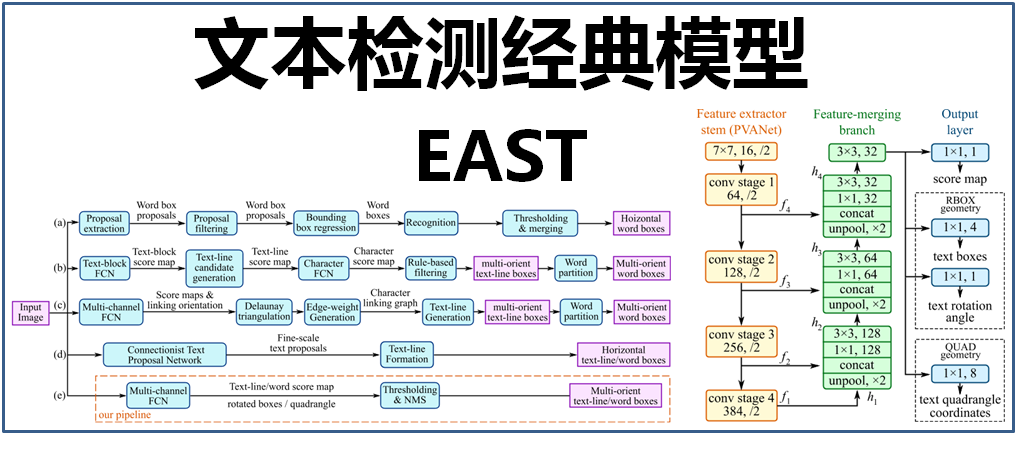
其中,(a)、(b)、(c)、(d)是几种常见的文本检测过程,典型的检测过程包括候选框提取、候选框过滤、bouding box回归、候选框合并等阶段,中间过程比较冗长。而(e)即是本文介绍的EAST模型检测过程,从上图可看出,其过程简化为只有FCN阶段(全卷积网络)、NMS阶段(非极大抑制),中间过程大大缩减,而且输出结果支持文本行、单词的多个角度检测,既高效准确,又能适应多种自然应用场景。(d)为CTPN模型,虽然检测过程与(e)的EAST模型相似,但只支持水平方向的文本检测,可应用的场景不如EAST模型。如下图:
![]()
二、EAST模型网络结构
EAST模型的网络结构,如下图:
![]()
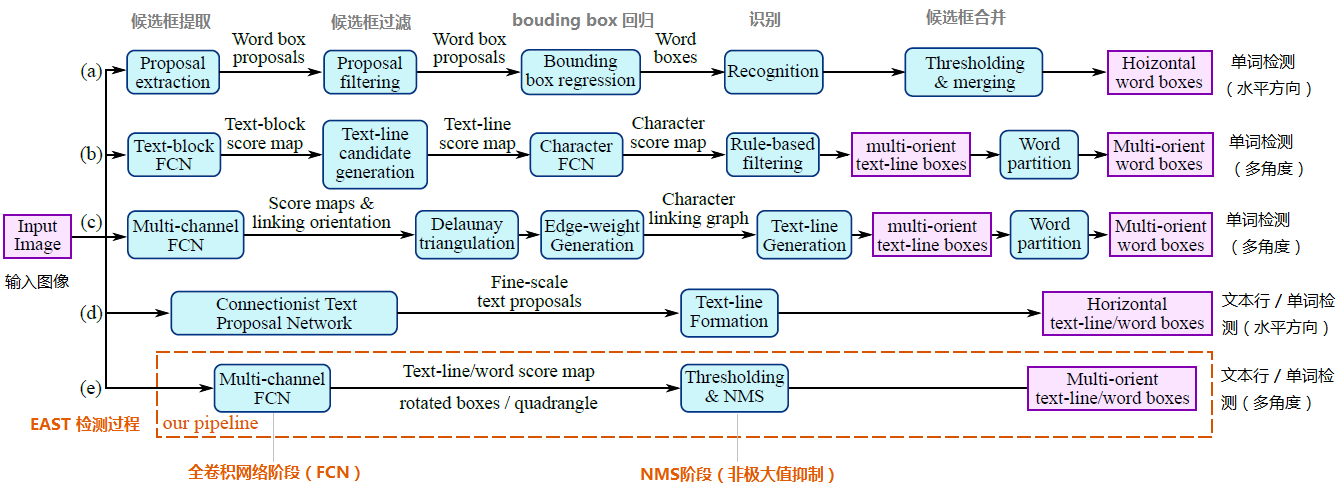
EAST模型的网络结构分为特征提取层、特征融合层、输出层三大部分。
下面展开进行介绍:
1、特征提取层
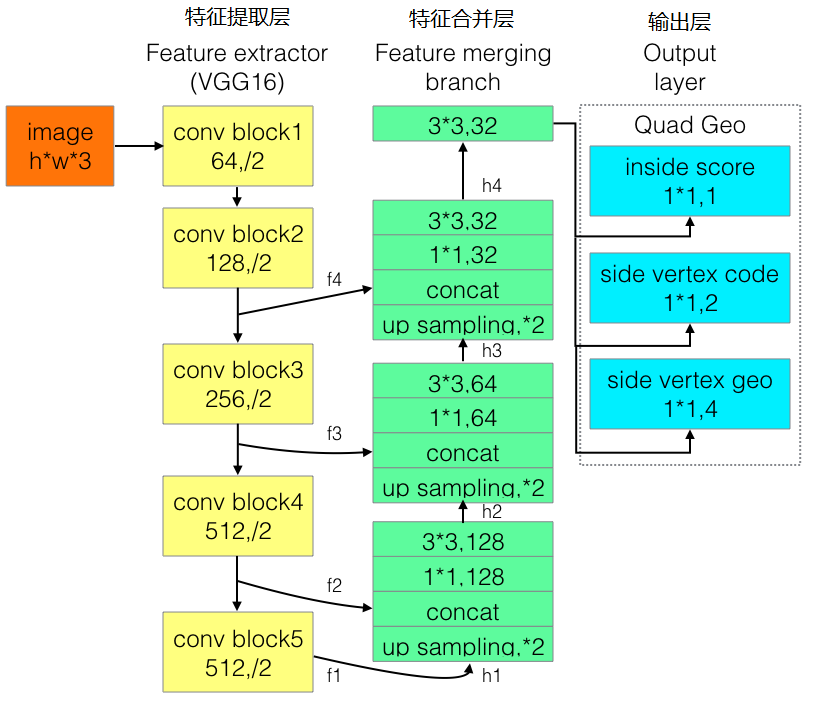
基于PVANet(一种目标检测的模型)作为网络结构的骨干,分别从stage1,stage2,stage3,stage4的卷积层抽取出特征图,卷积层的尺寸依次减半,但卷积核的数量依次增倍,这是一种“金字塔特征网络”(FPN,feature pyramid network)的思想。通过这种方式,可抽取出不同尺度的特征图,以实现对不同尺度文本行的检测(大的feature map擅长检测小物体,小的feature map擅长检测大物体)。这个思想与前面文章介绍的SegLink模型很像;
2、特征融合层
将前面抽取的特征图按一定的规则进行合并,这里的合并规则采用了U-net方法,规则如下:
- 特征提取层中抽取的最后一层的特征图(f1)被最先送入unpooling层,将图像放大1倍
- 接着与前一层的特征图(f2)串起来(concatenate)
- 然后依次作卷积核大小为1x1,3x3的卷积
- 对f3,f4重复以上过程,而卷积核的个数逐层递减,依次为128,64,32
- 最后经过32核,3x3卷积后将结果输出到“输出层”
3、输出层
最终输出以下5部分的信息,分别是:
- score map:检测框的置信度,1个参数;
- text boxes:检测框的位置(x, y, w, h),4个参数;
- text rotation angle:检测框的旋转角度,1个参数;
- text quadrangle coordinates:任意四边形检测框的位置坐标,(x1, y1), (x2, y2), (x3, y3), (x4, y4),8个参数。
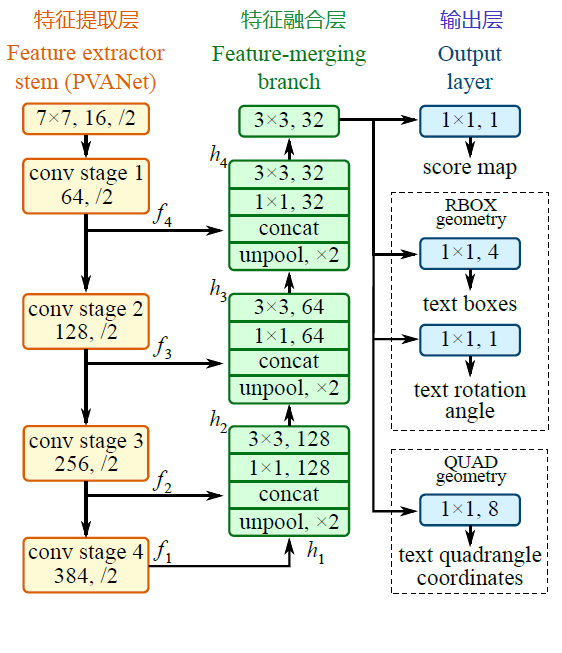
其中,text boxes的位置坐标与text quadrangle coordinates的位置坐标看起来似乎有点重复,其实不然,这是为了解决一些扭曲变形文本行,如下图:
![]()
如果只输出text boxes的位置坐标和旋转角度(x, y, w, h,θ),那么预测出来的检测框就是上图的粉色框,与真实文本的位置存在误差。而输出层的最后再输出任意四边形的位置坐标,那么就可以更加准确地预测出检测框的位置(黄色框)。
三、EAST模型效果
EAST文本检测的效果如下图,其中,部分有仿射变换的文本行的检测效果(如广告牌)
![]()
EAST模型的优势在于简洁的检测过程,高效、准确,并能实现多角度的文本行检测。但也存在着不足之处,例如(1)在检测长文本时的效果比较差,这主要是由于网络的感受野不够大;(2)在检测曲线文本时,效果不是很理想
四、Advanced EAST
为改进EAST的长文本检测效果不佳的缺陷,有人提出了Advanced EAST,以VGG16作为网络结构的骨干,同样由特征提取层、特征合并层、输出层三部分构成。经实验,Advanced EAST比EAST的检测准确性更好,特别是在长文本上的检测。
网络结构如下:
![]()
墙裂建议
2017年,Xinyu Zhou 等人发表了关于EAST的经典论文《 EAST: An Efficient and Accurate Scene Text Detector 》,在论文中详细介绍了EAST的技术原理,建议阅读该论文以进一步了解该模型。
关注本人公众号“大数据与人工智能Lab”(BigdataAILab),然后回复“论文”关键字可在线阅读经典论文的内容。
![]()
推荐相关阅读