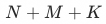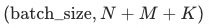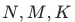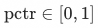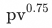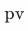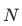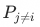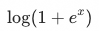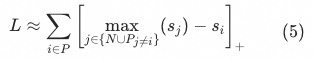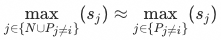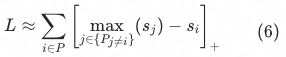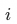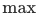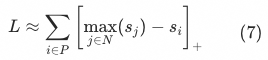![]()
两阶段排序(粗排-精排)一开始是因系统性能问题提出的排序框架,长期以来粗排的定位一直是精排的退化版本,但我们发现通过一些技术手段,粗排可以在较大的集合上超越精排。通过重新审视粗排和精排的关系和提出全域hitrate这一新的评价体系,再结合采样优化、蒸馏等手段,我们提升了搜索大盘约1.0%的成交金额
▐ 概述
淘宝主搜索是一个典型的多阶段检索系统,主要分为召回、粗排、精排等阶段。召回阶段,由文本召回、个性化等多路召回构成,输出商品量级约10^5;粗排阶段,需要从三路召回集合中分别进行筛选,筛选出10^3量级提供给精排;后续经过精排等阶段再进行筛选输出约top10曝光给用户。(注:下文中10、10^3、10^5等均代表数量级,数值只作为示意,只有其相对大小具备参照意义)
![]()
其中,粗排(主搜有时也称之为做海选)本质是从海量候选集中输出一个最佳集合,虽然都是排序但和精排的目标存在很大差异,从目标上来看其实和召回更加相似。同时,我们需要使用排序这个手段来完成,所以常见的论文和方法更倾向于不断的模仿和逼近精排。经过近两年主搜下的探索和实践,从目标上可以总结出的精排与粗排最大的差异是:精排注重头部商品的排序,粗排注重腰部商品的排序。业内很多各种提高精排与粗排一致性的手段通常在主搜都不会有实质性的效果,主要有两个原因:一是精排只用曝光集合作为训练样本,我们离线验证即使把精排直接丢到粗排阶段进行打分,那结果也是惨不忍睹,大量未见过的样本分数趋向于随机;二是粗排最要解决的是如何在召回集合中选出优质的子集,如果这部分子集足够优质,那后续的问题不一定是粗排和精排保持一致,可能是需要精排和粗排保持一致。
去年我们团队采用多目标优化+负样本扩充+listwise蒸馏这“三板斧”成功在主搜粗排阶段取得了显著的成效,也是首次将粗排的训练样本和目标做出了和精排明显的差异,并在每路内召回集合hitrate验证下表明粗排显著超过了精排模型,但是由于时间原因只进行了比较片面的尝试,今年我们继续针对这些问题进行深入的探索和剖析,今年继续新的评价指标和评价体系,我们对所有改进功能都进行了回测,同时进行了进一步改进和提升。
具体到评价指标方面,由于去年我们只有一个片面的衡量与精排一致性的指标(NDCG),无法衡量召回-粗排的损失,进而无法衡量粗排负采样的好坏进行衡量,且本身这个目标就和粗排实际的优化方向存在很大偏差,实验过程也容易发现盲目提高NDCG且不增加负采样只会让粗排效果更差。因此,今年引入了全新的评测指标“全域成交hitrate”作为粗排最重要的评价标准,并且历经一个月时间对从召回->粗排->精排的全域成交漏斗损失结合不同优化对应的线上GMV的影响进行了系统的分析,不仅对此评价指标的有效性进行了检验,还对各个阶段的优化空间、优化目标进行了一定程度的规范与统一。与此同时,具体到对粗排阶段离线优化目标,全域hitrate需要进一步进行拆分,其中粗排前与粗排后、场景内和场景外本身具有天然的不同,且最终我们通过分析和验证提出了两类评价指标分别描述“粗排->精排损失”和“召回->粗排损失”经过分析和细化后的这些粗排评测指标终于能和线上指标具有很强的正相关性。
在“粗排->精排损失”和“召回->粗排损失”的指标都建立完成后,我们会发现用技术手段去缓解最开始提到的两个问题“与精排目标不一致”和“粗排练样本空间与线上打分空间不一致”就可以在这两种指标上分别得到体现,其中长尾商品问题我们去年的做法只是解决了其“打分过高”的问题,但是实际上加重了其“打分过低”的问题,我们今年也进行了一定的尝试,具体的方法将在第4节阐述。
▐ 模型基础结构
为了方便读者理解,在本节中,我们将去年对粗排模型的优化结果做简要的介绍。这是今年粗排模型优化的基础。
训练样本的选择是粗排模型区别于精排模型的一个重要差异之一。为了拟合在粗排阶段的打分空间,粗排模型的训练样本由三部分构成:曝光样本、未曝光样本和随机负样本。其中曝光样本指经过精排模型排序后曝光的样本;未曝光样本指经过粗排模型排序后,送入精排,但未得到精排阶段曝光的样本;随机负样本指在query相关类目下随机采样的样本。样本采用listwise的组织形式,将一个请求下的三种样本拼接成一个长度为 ![]() 的列表,即样本维度为
的列表,即样本维度为 ![]() ,其中
,其中 ![]() 分别表示曝光样本、未曝光样本和随机负样本对应的长度。去年只是通过推测和分析进行的这部分样本构造工作,在今年提出和发现全域成交指标后,对此部分工作进行了回测,发现未曝光样本和随机负样本这两部分负样本的扩充共带来约5.5 pt的场景外的hitrate的提升。
在损失函数方面,我们引入包括曝光、点击、成交在内的三个优化目标,使得user-query向量和item向量能够在多个目标的共同作用下同时优化从而达到最优。对于每个样本的logit,首先经过softmax,使用NLL loss来计算每个任务的损失函数,最后将每个任务的损失函数加和得到最终的损失函数。基于listwise的样本组织形式,我们希望达到对不同样本logit排序的目标,通过多个逐步递进的任务,建立曝光PV -> 点击Click -> 成交Pay的对应关系,三者正例数以此为前者的子集。我们希望多目标粗排模型能够学习到粗排打分商品之间的顺序,优先将用户最可能成交的商品召回并排在最前,其次是用户可能点击的商品和精排模型可能曝光的商品,最后是那些仅相关的商品。此外,为了进一步提高模型与精排模型的一致性,我们还添加了对精排分数学习的蒸馏任务,在曝光样本上让粗排模型学习精排模型的打分分数。
模型结构方面,我们遵循了业界广泛采用的基于内积模型结构,在分别计算user-query向量和item向量后,计算两个向量的内积作为其相似度(logit),整体模型输入输出如下图所示(注:虽然图中item向量涉及到很多种,但是他们共享一套网络结构和对应的trainable parameters)
分别表示曝光样本、未曝光样本和随机负样本对应的长度。去年只是通过推测和分析进行的这部分样本构造工作,在今年提出和发现全域成交指标后,对此部分工作进行了回测,发现未曝光样本和随机负样本这两部分负样本的扩充共带来约5.5 pt的场景外的hitrate的提升。
在损失函数方面,我们引入包括曝光、点击、成交在内的三个优化目标,使得user-query向量和item向量能够在多个目标的共同作用下同时优化从而达到最优。对于每个样本的logit,首先经过softmax,使用NLL loss来计算每个任务的损失函数,最后将每个任务的损失函数加和得到最终的损失函数。基于listwise的样本组织形式,我们希望达到对不同样本logit排序的目标,通过多个逐步递进的任务,建立曝光PV -> 点击Click -> 成交Pay的对应关系,三者正例数以此为前者的子集。我们希望多目标粗排模型能够学习到粗排打分商品之间的顺序,优先将用户最可能成交的商品召回并排在最前,其次是用户可能点击的商品和精排模型可能曝光的商品,最后是那些仅相关的商品。此外,为了进一步提高模型与精排模型的一致性,我们还添加了对精排分数学习的蒸馏任务,在曝光样本上让粗排模型学习精排模型的打分分数。
模型结构方面,我们遵循了业界广泛采用的基于内积模型结构,在分别计算user-query向量和item向量后,计算两个向量的内积作为其相似度(logit),整体模型输入输出如下图所示(注:虽然图中item向量涉及到很多种,但是他们共享一套网络结构和对应的trainable parameters)
在本节中,我们利用新提出的全域成交hitrate指标,对搜索全链路漏斗进行了分析。全域成交可以划分为两类成交样本:场景内成交和场景外成交。场景内成交即用户在搜索场景内产生的所有成交,场景外成交即同一个用户关联到的非搜索场景产生的成交。由于非搜索场景不存在query,我们通过相关性作为关联条件,将用户在场景外的成交item,关联到用户在场景内的query上,且要求场景内query和场景外成交item组成的query-item对满足一定的相关性条件。
我们通过埋点的方式对粗排阶段打分集合归因到对应的场景内和场景外成交。具体的,将多路召回结果统一使用粗排模型打分进行排序,并截断Top K计算搜索引导成交和符合相关性要求的非搜索关联成交对应的hitrate@K,具体见下图:
其中由于搜索本身具有相关性的限制,不能直接使用user-item pair进行归因,所以多余场景外成交要按照搜索意图的相关性进行过滤,可以看到:当K从召回缩减到10^3的情况下场景内/外成交的hitrate衰减非常缓慢;当小于10^3后,指标衰减逐渐加快,因此从场景外hitrate角度分析,对于从召回集合中输出10^3量级的优质商品这个任务,粗排可以提升的空间天花板较低。
除了图中所示,我们还进行了其他相关分析,一个有趣的结论是:粗排在10^3~10^4上可能比精排打分hitrate更高。这个结论将在后面4.3.2中进一步讨论。
![]()
粗排离线衡量指标分析与修正
▐ 启下:衡量粗排->精排损失
-
精排优化目标本身就是从精排打分集合中选出最优质且符合搜索场景bias(能在搜索场景成交)的 Top 10,乃至 Top 1,所以如果粗排预测的hitrate@10 能提高并接近场景内成交,自然一定程度和精排更加一致
-
这个是我们最近几年一致在用的指标,更看重和精排的一致性,主要是从模型/特征/目标等方面和精排深度模型对比。
-
因为部分情况下上面两个指标计算过困难,或有时为了和精排AUC指标之间能进行对比,我们会计算每次请求粒度下的AUC,因为粗排模型的损失函数是基于listwise的排序损失函数,最终输出的分数绝对值没有实际的物理含义,不同请求下的打分无法直接对比,因此没办法计算Total AUC。
▐ 承上:衡量召回->粗排损失
场景内 hitrate@10^3
场景内粗排输出集合的hitrate评测起来肯定是100%,只能通过比粗排打分小不到一个量级的集合近似表征,具体可根据不同场景的打分情况进行具体定义
场景外 hitrate@10^3
由于场景外成交基本不存在bias,需要以场景外指标为基准,判断粗排模型的能力。
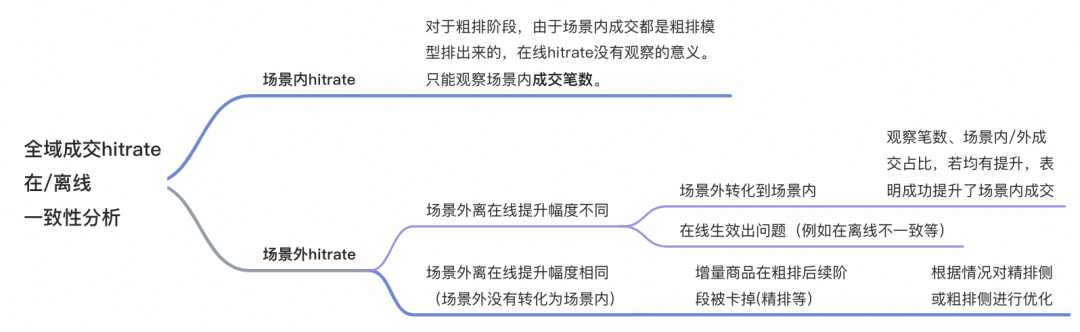
▐ 离线hitrate提升幅度与线上A/B test中hitrate提升幅度的一致性分析
-
因为粗排模型上线后,精排的候选集发生明显的
distribution shift
,进而最终指标绝对值必然不同,因此对于场景内分析几乎只能看场景内最终的成交笔数,至于粗排hitrate@ 10^3在上线之后再观察的意义本身也不大,因为这部分结果本身线上也是由精排决定。
-
场景外转化到场景内:如果离线场景外成交的提升转化为了场景内成交,那场景内的成交笔数、场景内与场景内成交的比值都会有明显提升。因为场景外转化为场景内后,剩下的场景外成交对于当前模型变得更
“难”
了,所以本身就符合预期。所以这种情况下其实已经是达到了我们的最终目的——提高了场景内成交。
在线生效出问题:如果场景内笔数没涨,并且场景外提升还变少了,大概率是出现在线生效问题,需要针对具体问题来排查。常见的问题是在离线特征、模型不一致等。
-
场景外
提升幅度
相同(
即场景外没有转化到场景内):
粗排后续阶段(精排等)场景外hitrate是否提升:如果后续阶段本身没有hitrate提升,则说明在粗排后续阶段对于粗排新召回的商品不认可,这种可能需要从特征/样本/loss等指标角度去找差异,
需要根据具体情况决定是对粗排进行调整还是对精排等阶段进行调整。
![]()
优化方法
我们在“ 模型基础结构”章节所介绍模型的基础上开展优化的工作。遵循第三节的分析结果,模型的优化也主要包含两部分:第一是减少粗排阶段输出的商品在精排阶段的损失,这部分工作主要关注于提高粗排模型的能力,包括模型蒸馏、特征的引入、模型结构的加强等;第二是减少召回的高质量商品在粗排阶段的损失,这部分工作主要集中于样本分布的优化。
▐ 减少粗排-精排损失
在去年工作中,我们提到使用精排模型曝光样本的打分来指导粗排模型的训练。简单来说,我们在曝光样本上,将精排模型的打分作为softmax,引入蒸馏的损失函数。引入蒸馏任务有几个好处,一方面可以提高精排模型和粗排模型的一致性,使粗排模型排出来的商品更容易被精排模型接受;另一方面,由于精排模型输入特征比粗排模型多,模型结构也比粗排模型复杂,因此可以认为精排模型的模型能力明显优于粗排模型,因此加入蒸馏任务也可以加速收敛,提高粗排模型的能力。
在去年引入曝光样本蒸馏的基础上,我们希望通过引入更多的未曝光样本进行蒸馏,进一步学习精排的能力。在实验过程中我们主要尝试了三种蒸馏方式:(a)单独添加引入M个未曝光样本样本的蒸馏,便于分别控制(b)去掉base中的pv distill loss 增加一个N+M+K的蒸馏 (c)保留base的蒸馏loss,添加一个N+M+K的蒸馏,如上图所示。
但是此时可能面临两个潜在问题:(i)随机负样本中的M个未曝光样本的精排分数可能会高于曝光样本,导致和pv loss含义冲突(ii)本身曝光任务上进行蒸馏拟合是在后验P(海选->曝光)=1 的情况下进行的,即在这种情况下,以精排点击任务模型输出 ![]() 蒸馏作为例子,pctr = pctr * 1 =P(海选->点击) 即可以表征其从海选到点击的概率,但是对于未曝光商品其后验P(海选->曝光)=0,从数学角度来说 pctr 没办法乘0或者直接表征海选到点击的概率。对于以上两个问题,我们发现由于曝光集合是在top10,未曝光采样集合在10-5000随机,通常显著小于曝光商品打分,(i)中存在的问题可以忽略。对于问题(ii)其中一种解决方式是使用label smoothing方法使用 pctr * scale代替 pctr *0的表征使其保留梯度,其中scale << 1。
最终我们发现实验(c)中方案效果最好,粗排模型和精排模型的一致性有了显著提高,NDCG +0.65pt ;此外,场景外hitrate也有 +0.3pt 的提升,表明引入更多的精排分数后,模型能力也能够得到提升。
粗排模型特征主要包含两方面:User/Query侧特征和Item侧特征,分别对应两个Tower的输入。我们尝试基于精排模型的特征,向粗排模型引入更多的特征,希望进一步加强粗排模型的表达能力,同时也能和提高与精排模型的一致性。
经过实验,我们挑选了对粗排模型效果最显著的特征,主要包括用户画像特征和用户的长期成交序列,帮助粗排模型更准确地建模用户侧信息。新加入特征的收益是明显的,在离线评测中,hitrate有+0.4 pt的涨幅。我们同时也考虑了长期点击序列,但在离线实验中没有提升。需要注意的是,受到双塔内积结构的限制,粗排模型无法直接使用在精排模型中增益明显的交叉特征。有关这方面的探索,请参考交叉特征的引入。
蒸馏作为例子,pctr = pctr * 1 =P(海选->点击) 即可以表征其从海选到点击的概率,但是对于未曝光商品其后验P(海选->曝光)=0,从数学角度来说 pctr 没办法乘0或者直接表征海选到点击的概率。对于以上两个问题,我们发现由于曝光集合是在top10,未曝光采样集合在10-5000随机,通常显著小于曝光商品打分,(i)中存在的问题可以忽略。对于问题(ii)其中一种解决方式是使用label smoothing方法使用 pctr * scale代替 pctr *0的表征使其保留梯度,其中scale << 1。
最终我们发现实验(c)中方案效果最好,粗排模型和精排模型的一致性有了显著提高,NDCG +0.65pt ;此外,场景外hitrate也有 +0.3pt 的提升,表明引入更多的精排分数后,模型能力也能够得到提升。
粗排模型特征主要包含两方面:User/Query侧特征和Item侧特征,分别对应两个Tower的输入。我们尝试基于精排模型的特征,向粗排模型引入更多的特征,希望进一步加强粗排模型的表达能力,同时也能和提高与精排模型的一致性。
经过实验,我们挑选了对粗排模型效果最显著的特征,主要包括用户画像特征和用户的长期成交序列,帮助粗排模型更准确地建模用户侧信息。新加入特征的收益是明显的,在离线评测中,hitrate有+0.4 pt的涨幅。我们同时也考虑了长期点击序列,但在离线实验中没有提升。需要注意的是,受到双塔内积结构的限制,粗排模型无法直接使用在精排模型中增益明显的交叉特征。有关这方面的探索,请参考交叉特征的引入。
在主搜场景下,粗排阶段的打分量高达上万个商品。在线上资源受限的背景下,为了在性能和效率之间达到平衡,粗排模型选择了内积的形式来计算User和Item之间的相似度。相较于精排模型的多层全联接结构,向量内积的运算速度快,大大节省了在线的计算开销。然而,内积操作的缺陷也是显而易见的。由于User侧的信息和Item侧的信息只能在User内积阶段进行交互,因此无法引入User x Item的交叉特征。在精排阶段的经验表明,User x Item的交叉特征(例如item在当前query下历史的点击次数)对于模型效果有明显的增益。因此,我们考虑如何在尽量保持内积结构不变的基础上,将交叉特征引入粗排模型。
为了向粗排模型中引入交叉特征,在原有的Item Tower和User Tower的基础上,我们引入了Cross Tower,如上图所示。在线Servering阶段,Cross Tower和User Tower一同在线计算。与Item Tower类似,Cross Tower的输出向量也同样与User侧向量计算内积,最后两次内积加和后得到最终的计算结果。离线实验中,加入了交叉特征的粗排模型hitrate +0.2pt,但在线测试中,我们没有观察到明显的效果提升。考虑到引入Cross Tower对于在线机器的计算量仍然较大,我们暂停了该方向的探索。
MLP/多层FC直觉上可以拟合更复杂的关系,理论上应该表达能力明显强于内积分,但是在主搜场景下并没有得到实际直觉上的效果。大体尝试了两种方式:1是在原本内积后额外增加2层MLP,便于上线;2是和精排一样在attention后全部使用MLP。以上两种离线测试hitrate、NDCG、AUC均无明显变化,后续为了便于测试还在精排样本上进行了更多特征上的测试,发现只有当输入特征显著增多后(包括交叉特征),MLP才能相对于内积的AUC有明显的提升,但是对于粗排太多特征可能得不偿失。
后续我们简单尝试了上线了2层MLP的实验,线上rt增加30ms,线上效果没有提升,其余指标和离线测试效果一致,与离线的实验预期一致。
▐ 减少召回-粗排损失
在第三节中,我们提到了粗排今年引入的新衡量指标:全域成交hitrate。全域成交hitrate能够降低评价指标中的偏置,更客观地评价模型的能力。为了直接优化这个指标,我们从样本角度出发,将场景外(即除搜索场景以外的淘宝成交)样本引入训练样本中,借此提高模型在hitrate上的表现。
我们通过修正正样本来引入场景外样本。在原始的样本中,场景外的样本有两种可能:一是被作为成交任务的负样本;二是不存在样本集合中(因为场景外样本可能没有被曝光,甚至有可能没有被召回)。为了不破坏训练样本的原始分布,我们首先尝试不引入新样本的方式。在这种方法下,若某个样本存在于原始样本中,则将其成交标签设为1。实验表明,这样的样本修正方式对粗排阶段的hitrate几乎没有任何影响。通过进一步分析,我们发现,若场景外成交样本出现在原始样本中,则几乎只有可能出现在曝光样本中,而极少出现在未曝光样本或随机负样本中。这样一来,这样的样本修正方式实际上是对曝光样本的修正,即将已曝光但在场景外成交的样本,从负样本修正为正样本。需要指出的是,曝光样本实际上是通过粗排模型排出来的样本,即这部分样本即便是成交负样本,对于粗排模型来说打分已经相对较高(因为是曝光任务的正样本),对这部分样本在曝光阶段的成交/点击label修正并不能在粗排阶段带来收益。因此若希望提高粗排阶段的场景外成交hitrate,则必须引入更多粗排阶段没有排出来的场景外样本。
基于上述分析,我们进一步引入场景外成交样本。在对原始样本进行修正的基础上,对于不存在于原始样本中的场景外成交样本,我们将其添加进曝光样本中,将其同时设为曝光、点击和成交任务的正例。通过这种方式,我们将成交样本的样本量扩大了约80%。在对样本做扩增后,粗排模型的场景外hitrate提升了0.6pt。
长尾问题在统计学习方法中几乎无处不在,粗排模型也不例外。本节介绍了在粗排模型上针对长尾商品优化的一些探索。本节分为三个部分,首先介绍了我们对长尾商品的划分标准;接下来,我们对目前模型中长尾商品的表现进行了评估,证实了模型在长尾商品集合中确实存在打分不准的问题;最后介绍了我们在样本方面的一些探索,并总结了目前仍然存在的问题。
我们以商品的历史日均曝光次数作为长尾划分的阈值,来划定长尾商品集合。在搜索场景中,以曝光次数为标准来划定长尾商品是自然的。高曝光的商品能够获得更多的用户反馈,更频繁地出现在训练样本中,从而得到充分的训练;反之,少曝光甚至无曝光的商品很难出现在训练样本中,以至于模型在训练过程中很少见到这部分商品,导致打分的误差偏大。
基于上述长尾商品划分标准,我们计算了不同曝光次数的商品粗排阶段的hitrate:
上述分析表明,相较于头部高曝光商品,模型对低曝光的长尾商品的打分的准确度都明显较差,这提示我们在这部分商品上,模型还有很大的优化空间,同时我们还统计了此部分商品在总体成交中占比也很高,因优化低曝光商品也能对整体成交进行提升。
上文提到,模型在长尾商品上表现较差的原因是在曝光样本集合中出现较少,使得模型不能充分地训练这部分商品。而特别地,在粗排模型的训练中,我们发现,由于随机负采样样本的存在,会进一步打压长尾商品的打分,使长尾商品的打分偏低。随机负样本是从全库满足query类目预测的商品中均匀采样的,由于马太效应的存在,头部商品只占了一小部分,绝大部分商品都属于长尾商品。这就导致随机负样本中,绝大多数商品都是长尾商品,从而导致在模型的训练过程中,长尾商品作为负样本的概率被随机负样本进一步放大了。这样一来,模型就更有可能学到“长尾商品通常是负样本”这一错误的偏置,导致长尾商品的打分偏低。为了检验上述猜想,我们统计了长尾商品在随机负样本中的占比:
从上表可见在随机负样本中,绝大多数样本曝光次数都较低,这也验证了我们上文的猜想。
为了解决这个问题,我们调整了随机负样本的采样方式,目的是在随机负样本中增加高曝光商品的分布。我们借鉴了Word2Vec中的采样方式,将随机负采样的采样概率调整为 ![]() ,其中
,其中 ![]() 表示对应商品历史的曝光次数。调整采样方式后,长尾商品的占比有了明显变化:
修改负样本分布后,在不同样本下的hitrate变化如上表所示。符合预期地,在新的采样分布上,模型在低曝光商品的场景外hitrate提高了1.04pt。然而,我们发现,调整后的采样分布中,由于中高曝光商品在负采样样本中的增多,反而导致其曝光商品的hitrate下降,此方案对于整体hitrate提升幅度不高,后续可能还有更多的改进空间。
表示对应商品历史的曝光次数。调整采样方式后,长尾商品的占比有了明显变化:
修改负样本分布后,在不同样本下的hitrate变化如上表所示。符合预期地,在新的采样分布上,模型在低曝光商品的场景外hitrate提高了1.04pt。然而,我们发现,调整后的采样分布中,由于中高曝光商品在负采样样本中的增多,反而导致其曝光商品的hitrate下降,此方案对于整体hitrate提升幅度不高,后续可能还有更多的改进空间。
▐ 其他优化工作
在模型基础结构章节中,我们介绍了粗排模型使用的listwise多目标损失函数,包含多目标任务(曝光、点击、成交)和蒸馏任务。简单来说,在多目标优化的任务中,对于每一个目标,我们把正样本和负样本组成一个list,希望正样本排在负样本的前面。对于一个listwise任务,一个自然的选择是Negative Log-Likelihood损失函数:
![]()
其中 ![]() 表示item侧和user侧向量的内积,即similarity;
表示item侧和user侧向量的内积,即similarity; ![]() 表示list的长度。不同于其他场景下的任务,粗排模型的三个任务,尤其是曝光任务,在每个list中, 正样 本的数量都可能不为1(尤其是曝光任务,正样本的数量通常为10)。我们发现,在粗排的场景下,直接套用softmax在多正样本的情况下的优化目标具有不合理之处,并据此对该损失函数进行了改进,使之更加适合粗排模型的优化目标。
通过上述转换,我们将负样本的部分转化为LogSumExp函数的形式:
其中
表示list的长度。不同于其他场景下的任务,粗排模型的三个任务,尤其是曝光任务,在每个list中, 正样 本的数量都可能不为1(尤其是曝光任务,正样本的数量通常为10)。我们发现,在粗排的场景下,直接套用softmax在多正样本的情况下的优化目标具有不合理之处,并据此对该损失函数进行了改进,使之更加适合粗排模型的优化目标。
通过上述转换,我们将负样本的部分转化为LogSumExp函数的形式:
其中 ![]() 表示负样本集合,
表示负样本集合, ![]() 表示除第
表示除第 ![]() 个样本以外的正样本集合
现在我们对上述损失函数作一些近似,这样可以帮助我们更清晰地理解损失函数的优化目标。首先,我们将LSE近似为最大值函数:
其次将
个样本以外的正样本集合
现在我们对上述损失函数作一些近似,这样可以帮助我们更清晰地理解损失函数的优化目标。首先,我们将LSE近似为最大值函数:
其次将 ![]() (也称为SmoothReLU函数)近似为ReLU:
从上述形式不难看出,对于每一个正样本
(也称为SmoothReLU函数)近似为ReLU:
从上述形式不难看出,对于每一个正样本 ![]() ,上述损失函数都在试图拉大正样本
,上述损失函数都在试图拉大正样本 ![]() 与当前list中所有其他样本上界之间的距离,这里的“其他样本”既包括全部的负样本, 也包括除样本
与当前list中所有其他样本上界之间的距离,这里的“其他样本”既包括全部的负样本, 也包括除样本 ![]() 以外的其他正样本 。在绝大多数情况下,正样本的内积相似度大于负样本内积相似度,即
以外的其他正样本 。在绝大多数情况下,正样本的内积相似度大于负样本内积相似度,即 ![]() ,因此式(5)可以进一步写成:
容易发现,在上述形式下,该损失函数多数情况下优化的是当前样本
,因此式(5)可以进一步写成:
容易发现,在上述形式下,该损失函数多数情况下优化的是当前样本 ![]() 与除
与除 ![]() 以外的全部正样本的上界 之间的距离,最终达到的效果是拉大正样本之间的距离,而忽视了真正重要的正样本和负样本之间的差异。
以外的全部正样本的上界 之间的距离,最终达到的效果是拉大正样本之间的距离,而忽视了真正重要的正样本和负样本之间的差异。
一旦理解了目前softmax函数的问题所在,只要将上述公式稍加改动,就可以避免上文中发现的问题。具体地,在公式(5)中,我们只需要将除![]() 以外的正样本从
以外的正样本从![]() 项中删除,即计算当前样本
项中删除,即计算当前样本![]() 与除
与除![]() 以外的全部负样本的上界:
以外的全部负样本的上界:
![]()
将式(7)平滑展开回softmax。对应地,只需要在softmax计算过程中,将分母中的当前样本![]() 以外的其他所有正样本剔除即可:
以外的其他所有正样本剔除即可:
这样在公式中的微小改动,在模型训练中产生了明显的效果,印证了理论分析的正确性。实验表明,上述损失函数的改动明显提高了粗排模型与精排模型的一致性(NDCG +0.63pt),场景外hitrate也提升约0.2%。
根据我们全域漏斗分析发现,精排和粗排在打分量边界处不一定谁的打分能力更强,我们也通过实验发现,在相关性等其他必要指标一致的情况下,精排分量增多未必能带来线上效果的提升,甚至打分过多会导致曝光阶段全域hitrate下跌从而导致线上成交数目下跌。
从这个角度进一步说明了粗排不一定要和精排保持一致,二者本身在打分能力上,一个更注重头部,一个更注重腰部,而在打分边界部分需要根据二者实际能力而定。
相对于以前只用精排样本的业内常见的粗排版本,主搜从去年到现在提出的针对业务场景的采样方式、多目标loss融合、蒸馏方式等优化,共带来了搜索大盘约1.0%的成交金额提升。需要指出的是,我们对粗排->精排的损失和召回->粗排的损失是同等看待的。但从近期的离线实验可以看出,绝大多数实验都会出现两种情况:一是离线hitrate提升不明显,即优化点无效果;二是召回->粗排的损失缩小,粗排->精排损失增大,即粗排输出集合确实变得更加优质,但是增量部分不能被精排认可(或者只认可一少部分)。这一点其实也一定程度符合认知,比如粗排的很多改动,如正样本中引入关联到的未进精排的全域样本,负样本的随机采样样本分布改动,目前精排目前的实验都没有加入类似的正负样本,很难能对粗排增量的优质集合进行正确打分。因此后续粗排的优化不仅仅要遵循承上+启下两部分损失的优化,对于经过分析验证中发现的精排未通过的优质商品,针对具体问题将粗排和精排的样本进行一定程度的对齐,协同粗排的腰部排序能力和精排的头部排序能力的同时一定程度增加一致性,最终实现双赢。