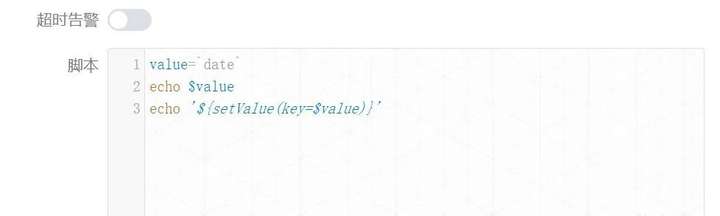![]()
作者简介
![]()
淡丹
数仓开发工程师
5年数仓开发经验,目前主要负责百得利MOBY新车业务
二手车业务及售后服务业务系统数仓建设
业务需求
在ETL任务之间调度时,我们有的时候会需要将上游的计算结果作为参数传入到下游,针对这种业务需求,海豚调度器为我们提供了一些功能。
具体如下:
DolphinScheduler允许在任务间进行参数传递,目前传递方向仅支持上游单向传递给下游。
支持这个特性的任务类型有:
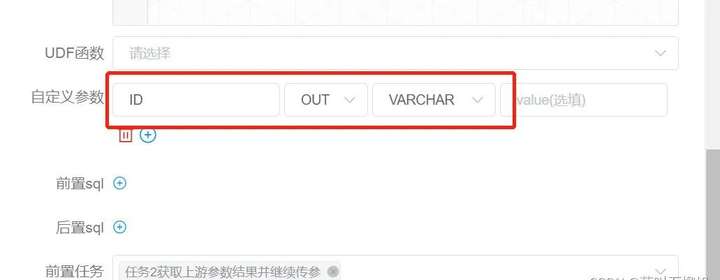
当定义上游节点时,如果有需要将该节点的结果传递给有依赖关系的下游节点,需要在【当前节点设置】的【自定义参数】设置一个方向是 OUT 的变量。
目前我们主要针对 SQL 和 SHELL 节点做了可以向下传递参数的功能。
SQL任务
步骤1:SQL任务构建
测试SQL如下
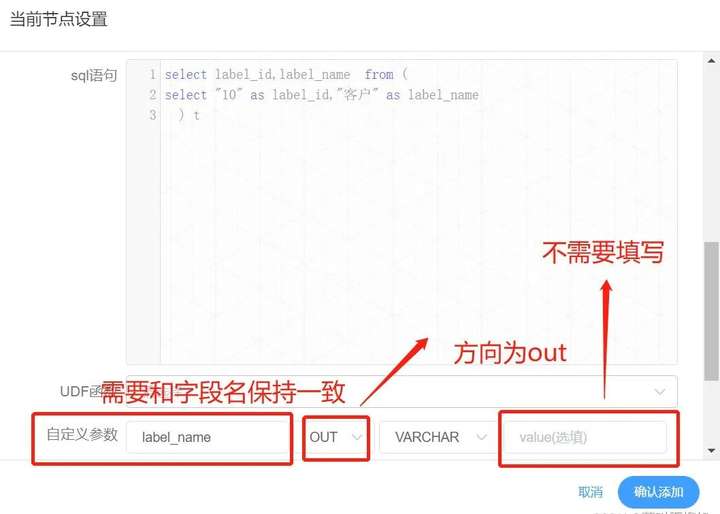
select label_id,label_name from (
具体如下图
![]()
注意点
方向选择为 OUT,只有当方向为 OUT 时才会被定义为变量输出
数据类型可以根据需要选择不同数据结构
Value 部分不需要填写
参数名字一定要和字段名字对应,否则不会识别
如果 SQL 节点的结果为多行,一个或多个字段,参数的名字需要和字段名称一致。
数据类型选择为LIST。获取到 SQL 查询结果后会将对应列转化为 LIST,并将该结果转化为 JSON 后作为对应变量的值。(注意新版本才会有,低版本没有LIST结构)
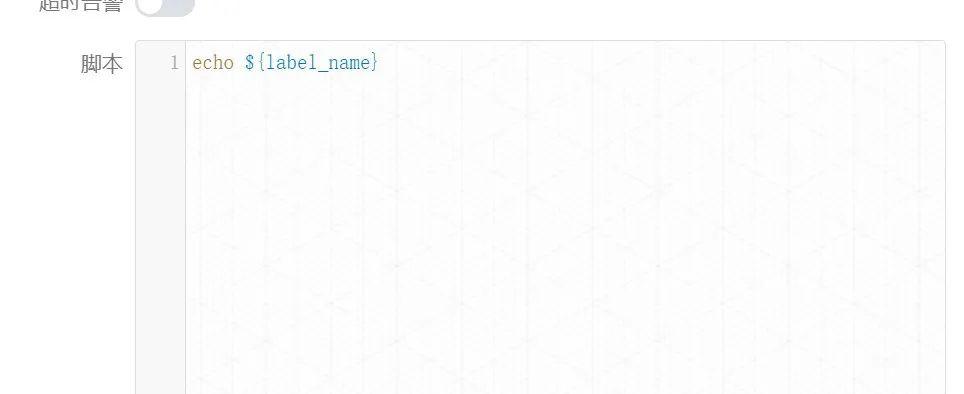
步骤2:SHELL脚本测试
![]()
注意此处,输入参数不需要填写,下游直接引用上游的变量即可
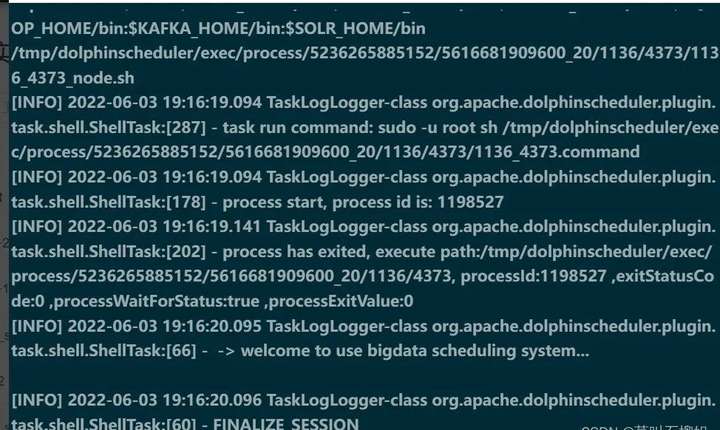
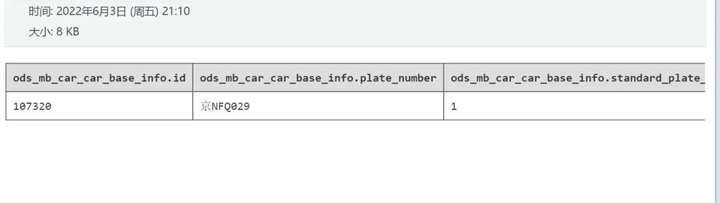
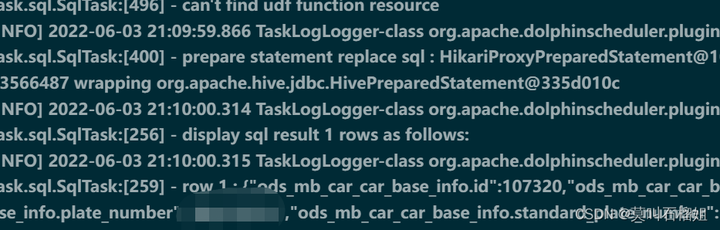
步骤3:上线验证结果
查看结果日志,可以看到下游节点已经接收到参数
![]()
SHELL任务
先看官网说明(链接):
https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/parameter/context.html
prop 为用户指定;
方向选择为 **OUT,**只有当方向为 OUT 时才会被定义为变量输出;
数据类型可以根据需要选择不同数据结构;
value 部分不需要填写;
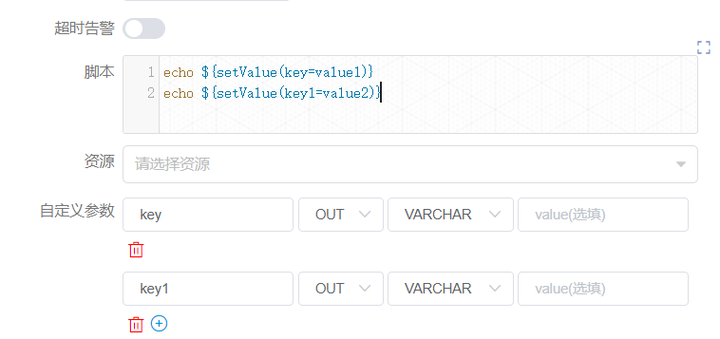
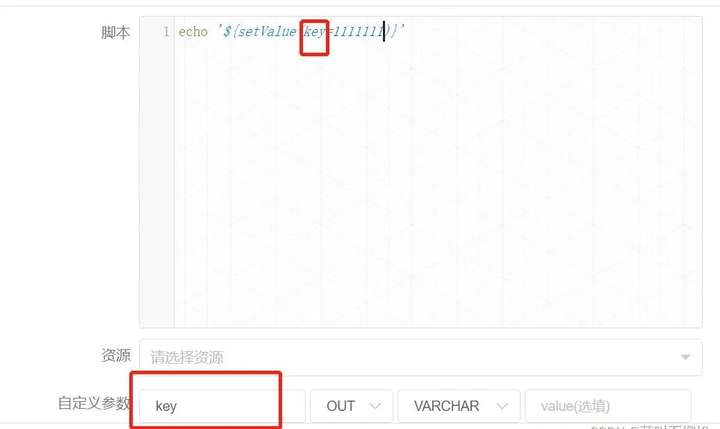
用户需要传递参数,在定义 shell 脚本时,需要输出格式为 ${setValue(key=value)} 的语句,key 为对应参数的 prop,value 为该参数的值。
例如下图
![]()
SHELL 节点定义的时候
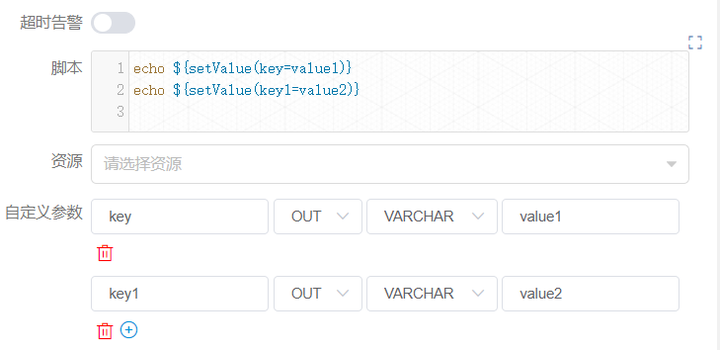
日志检测到 ${setValue(key=value1)} 的格式时,会将 value1 赋值给 key,下游节点便可以直接使用变量 key 的值。
同样,您可以在**【工作流实例】**页面,找到对应的节点实例,便可以查看该变量的值。
![]()
但在实际使用中官网的例子是跑不通的,这里面有小坑,上述在使用 ${setValue(key=value)} 这种形式传参的时候必须用引号引起来。
如下才能成功
echo '${setValue(key=value)}'
案例所示
![]()
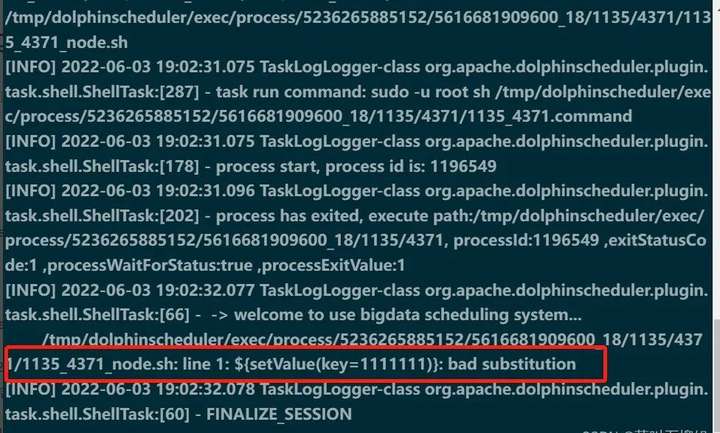
上线执行后查看日志如下:
![]()
可以看到结果已经打印出来。
如果取掉单引号会报如下错误:语法上就无法通过。
![]()
所以在SHELL中传参的时候,根据给的固定语法前,必须得加上单引号,否则语法无法通过。
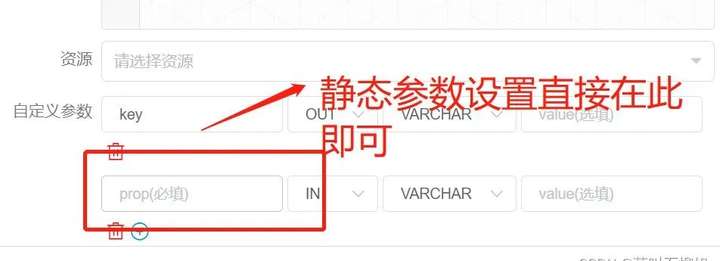
上述的例子也仅仅是 Key 后面跟的常量参数,事实上我们往往都是需要动态传参数的,所以 SHELL 的这种静态传递参数给下游其实是没有意义的,因为如果是静态的,我们为什么不选择in中输入参数呢?
如下图所示
![]()
我们在不同任务之间上下游之间的参数传递,往往是需要动态的/上游某个代码执行后的结果传递给下游。
**我们不妨来试试这种方式是否可以?**根据猜想我们编写如下案例:
任务1:
![]()
任务2:
![]()
![]()
查看test2的日志并未有任何执行结果打印出
![]()
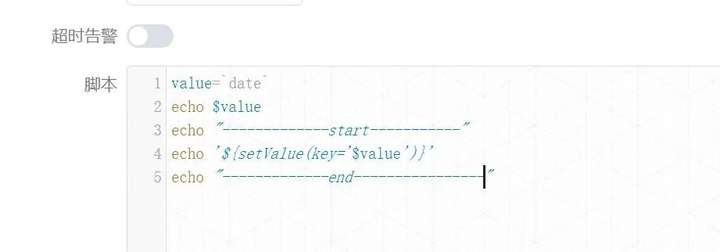
根据上面的猜测,由于在使用的时候我们整体上加了单引号,又根据shell语法的经验,**所以笔者决定在引用变量的时候再加单引号试试,**也就是如下形式:
echo '${setValue(key='$value')}'
我们来继续实验:
value=`date`
![]()
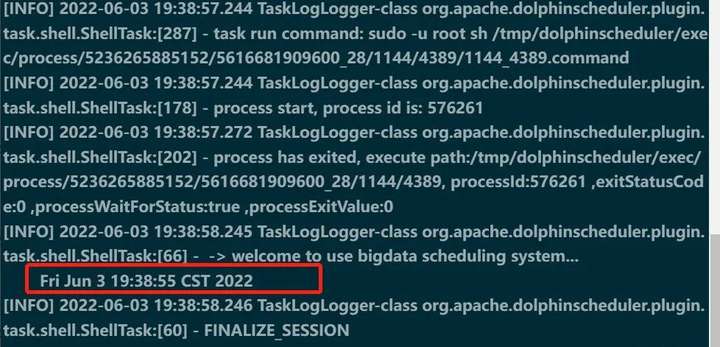
查看任务2的执行结果日志:
![]()
我们看到出现了最终想要的执行结果日志,也就是说想要动态传参必须采用如下模式才能成功~
echo '${setValue(key='$value')}'
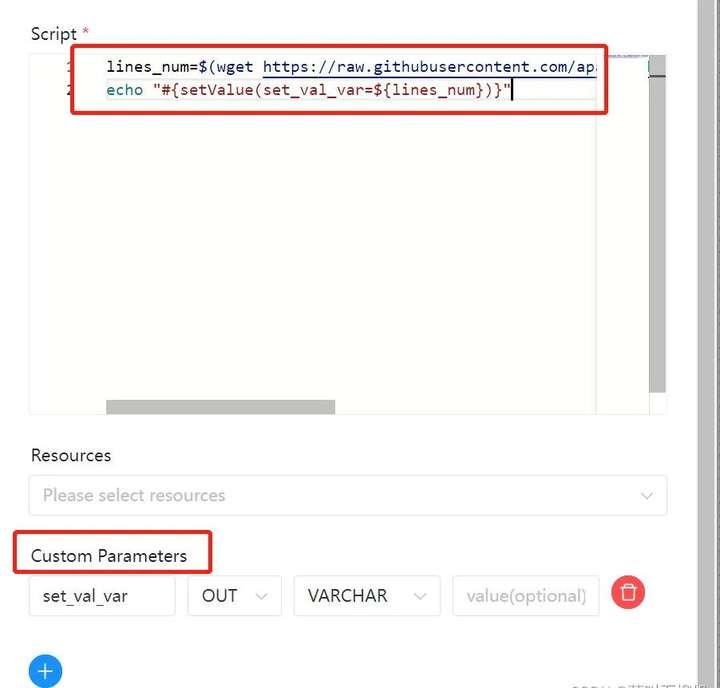
注意:在海豚调度器在 3.0.0-beta-1 版本后修复了这一问题,可以更好的支持动态传参问题,比如动态地获取现有的本地或 HTTP 资源并获取设定变量。
具体使用方法如下:
lines_num=$(wget https://raw.githubusercontent.com/apache/dolphinscheduler/dev/README.md -q -O - | wc -l | xargs)
![]()
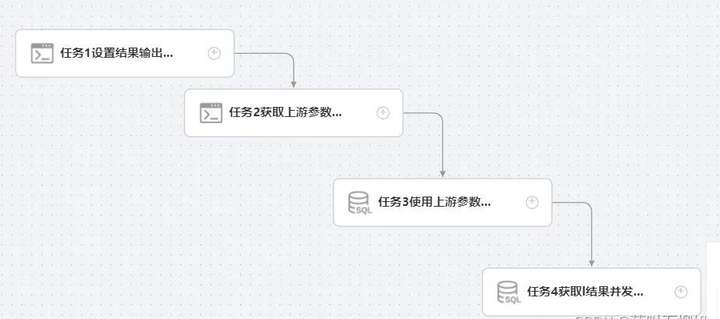
总体传参串联任务案例
**第一步:**设置任务输出参数
![]()
第二步:获取第一步参数并打印输出,且继续传参
![]()
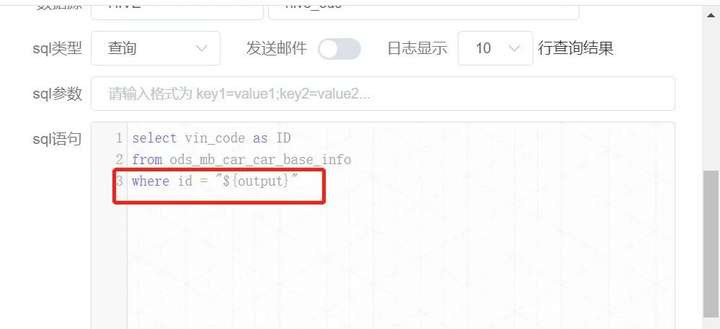
**第三步:**使用SQL语句获取第一步传递的参数 ,并把结果传递给下游。
![]()
引用参数时候,直接引用自定义输出参数的 Key 就可以了,比如本案例的 **output ,一般采用${output}**的形式,具体如下图所示:
![]()
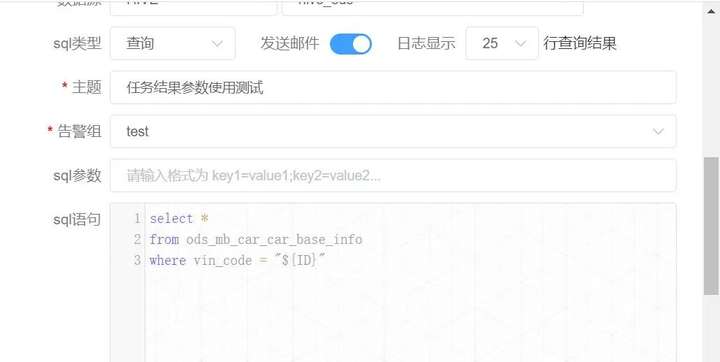
**第四步:**获取第三步的执行结果参数,并将结果输出~
![]()
【注意点】如果是sql任务:sql结尾不要有分号(;)否则会报错。
整体流程如下图所示
![]()
查看最终(邮件结果)如下:
![]()
任务4日志信息:可以看到已生成结果信息
![]()
小结
本文总结了DophineSheduler上下游任务之间参数传递的方法,并对其中的易错点进行了梳理,同时给出了具体参数传递的案例,读者可自行进行摸索。
其中易错点归纳如下:
(1)参数输出时方向选择为 out
(2)sql任务时参数的 key 值一定和 sql 语句中的字段名保持一致,否则不识别
(3)输出的value值不需要填写
(4)shell任务时,具体参考如下模板,模板中注意引号的使用
echo '${setValue(key='$value')}'
注意此处等号左边的 key 需要和自定义输出的参数key 名字一致
(5)sql任务中结尾不要有分号
(6)引用参数时只需要采用**${key}**即可
最后,如果对这个话题感兴趣的话,可以进群一起交流沟通,谢谢大家~
最后非常欢迎大家加入 DolphinScheduler 大家庭,融入开源世界!
我们鼓励任何形式的参与社区,最终成为 Committer 或 PPMC,如:
将遇到的问题通过 GitHub 上 issue 的形式反馈出来。
回答别人遇到的 issue 问题。
帮助完善文档。
帮助项目增加测试用例。
为代码添加注释。
提交修复 Bug 或者 Feature 的 PR。
发表应用案例实践、调度流程分析或者与调度相关的技术文章。
帮助推广 DolphinScheduler,参与技术大会或者 meetup 的分享等。
欢迎加入贡献的队伍,加入开源从提交第一个 PR 开始。
- 比如添加代码注释或找到带有 ”easy to fix” 标记或一些非常简单的 issue(拼写错误等) 等等,先通过第一个简单的 PR 熟悉提交流程。
注:贡献不仅仅限于 PR 哈,对促进项目发展的都是贡献。
相信参与 DolphinScheduler,一定会让您从开源中受益!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
来吧,开源社区非常期待您的参与。