【节点属性产生的背景】
在2.X版本中,已经支持节点设置标签,并且允许容量调度中的队列,设置可访问的节点标签以及默认标签值,并按照节点标签进行调度。
但一个节点只能有1个标签,这样在yarn集群中,通过标签将NM节点划分为不同的节点池(1个NM节点只能属于某个固定的节点池)。
实际上,光有节点标签还不能满足一些复杂的场景,比如同一个类型标签中的不同NM节点,可能有不同环境信息,例如不同的jdk版本、python版本、cpu型号等等。
实际任务调度时,需要在正确的节点上运行,因此引入了节点属性,节点属性按K=V的形式设置,并且允许设置多个。【节点属性的配置与设置】
1. yarn配置
和节点标签一样,节点属性并不是默认开启的,需要在rm(yarn-site.xml)中进行如下配置:
<property>
<name>yarn.node-attribute.fs-store.root-dir</name>
<value>hdfs://hdfsHACluster/root/node-attributes/</value>
</property>
<property>
<name>yarn.node-attirbute.fs-store.impl.class</name>
<value>FileSystemNodeAttributeStore</value>
</property>
其中"yarn.node-attribute.fs-store.root-dir"表示节点属性在RM中的存储位置,可以选择存储本地(对应配置为file:///xxx/xxx),也可以是选择存储在hdfs上。
"yarn.node-attirbute.fs-store.impl.class"表示节点属性存储的实现类,默认为`FileSystemNodeAttributeStore`。
2. 节点属性的设置
完成配置后,接下来自然就是对节点设置属性。设置属性的方式也和节点标签类似,分为中心集中式和分布式,简单来说中心集中式就是通过(管理员用户)执行命令对各节点进行属性设置;分布式则是由各节点通过自身配置的方式向RM上报所拥有的属性。
对于中心集中式,主要使用添加、删除命令,例如:
# 为指定节点添加属性
yarn nodeattributes -add "172.168.3.51:python2=true"
# 删除指定节点的属性
yarn nodeattributes -remove "172.168.3.51:python2=true"
添加或删除命令,通过指定节点的IP或域名,然后以":"分隔指定一个或多个属性,属性之间以","分隔;如果需要同时为多个节点设置属性,以空格为分隔符,分别指定为不同节点指定属性。
对于分布式,则需要在NM中进行对应的配置,例如:
<!-- 配置为config时通过 yarn.nodemanager.node-attributes.provider.configured-node-attributes来指定节点属性 -->
<property>
<name>yarn.nodemanager.node-attributes.provider</name>
<value>config</value>
</property>
<property>
<name>yarn.nodemanager.node-attributes.provider.configured-node-attributes</name>
<!-- 多个属性以 ":" 进行分隔 -->
<!-- 每个属性必须包含3个字段, 属性名,类型,属性值, 字段之间以","作为分隔 -->
<!-- 类型只能为大写STRIGN -->
<!-- 属性名只能为{0-9, a-z, A-Z, -, _} 且不能超过255个字符 -->
<value>jdk8,STRING,true:python3,STRING,true</value>
</property>
"yarn.nodemanager.node-attributes.provider"除了配置为config外,还可以配置为script,即通过定期执行指定的脚本来设置节点的属性,例如:
<property>
<name>yarn.nodemanager.node-attributes.provider</name>
<value>script</value>
</property>
<!--脚本的路径-->
<!--脚本的输出必须为一行或多行这样的信息 NODE_ATTRIBUTE:属性名,类型,属性值" -->
<property>
<name>yarn.nodemanager.node-attributes.provider.script.path</name>
<value>/opt/xxx.sh</value>
</property>
<!--脚本附带的参数-->
<property>
<name>yarn.nodemanager.node-attributes.provider.script.opts</name>
<value></value>
</property>
<!--脚本执行的间隔-->
<property>
<name>yarn.nodemanager.node-attributes.provider.fetch-interval-ms</name>
<value>600000</value>
</property>
<!--脚本执行的超时时间-->
<property>
<name>yarn.nodemanager.node-attributes.provider.fetch-timeout-ms</name>
<value>1200000</value>
</property>
除此之外,还可以配置自定义开发的实现类,该实现类一定要继承自"org.apache.hadoop.yarn.server.nodemanager.nodelabels.NodeAttributesProvider"。
完成节点的属性设置后,可以通过下面的命令来查看已经设置的节点属性:
[root@rm-0 /]# yarn nodeattributes -attributestonodes
Hostname Attribute-value
nm.yarn.io/python3 :
172.168.3.51 true
rm.yarn.io/python2 :
172.168.3.51 true
nm.yarn.io/jdk8 :
172.168.3.51 true
对于节点属性的设置,有如下需要注意的地方:
同一个key不能赋多个值,也就是说,对同一个Key多次设置属性值,后面设置的值覆盖前面设置的值。
当前value的类型仅支持string
节点标签还需要在队列中设置可以访问的标签,而节点属性则完全与队列没有关系。
对于节点标签而言,只能采用集中式或者分布式的方式,而节点属性则可以同时使用集中式和分布式的方式对接点进行设置。对于集中式设置的属性,会添加"rm.yarn.io"前缀,而对于分布式方式设置的属性,会添加"nm.yarn.io"前缀。这就意味着属性是通过前缀加名称来唯一标识的。
【按节点属性进行任务调度】
1. Placement Constraints简介
任务的container能根据节点属性来进行调度,本质上是用到了Placement Constraints,这里先来简单介绍下Placement Constraints。
很多时候,为了提升性能,需要让同一个application中的多个任务container运行在指定节点上,比如为了避免网络带宽带来的损耗,让container之间具备亲和性(运行在同一节点上)。
或者考虑到hdfs读写的性能,将应用的所有任务container调度到指定的节点上等等。
Hadoop引入了placement constraint,即AM向RM注册时,可以设置不同的表达式,后续申请资源时,让yarn根据此表达式来进行精准调度。
这个表达式就包含了NM节点属性,因此就可以按照NM节点属性来正确调度,当然,不仅限于按节点属性来调度。
2. 按节点属性匹配调度
要开启placement的匹配调度,首先需要在RM中进行如下配置:
<property>
<name>yarn.resourcemanager.placement-constraints.handler</name>
<value>placement-processor</value>
</property>
然后,可以通过自带的命令可以进行测试验证:
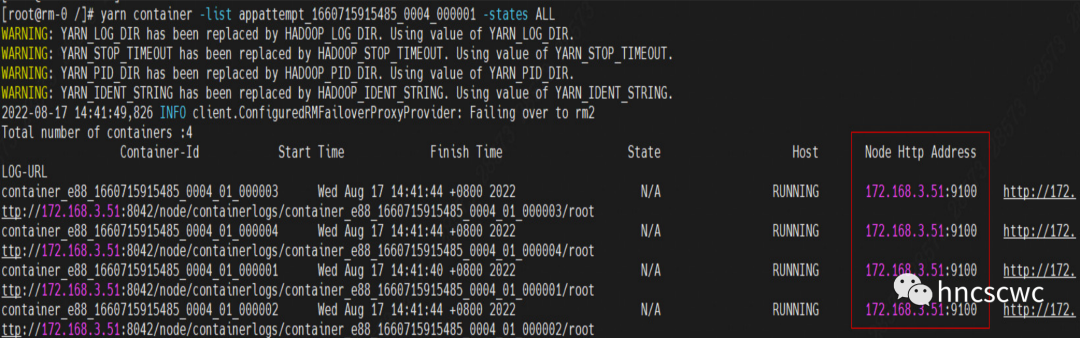
yarn org.apache.hadoop.yarn.applications.distributedshell.Client -jar share/hadoop/yarn/hadoop-yarn-applications-distributedshell-3.3.3.jar -shell_command sleep -shell_args 10 -num_containers 3 -placement_spec python2=true
任务的执行情况:
![]()
对比下同样的任务,未指定任何节点属性的情况:
![]()
同样,在使用中有如下需要注意的地方:
对于通过集中式方式指定的属性,可以不用加前缀,直接使用其属性名即可,而对于分布式(NM自行上报)的属性,使用时需要增加前缀才能正确进行匹配上。因此使用上建议统一方式。
节点属性约束是硬限制的, 即只有当节点的属性与任务指定的属性匹配时才能进行分配,否则任务container会一直处于pending状态,直到找到可以满足条件的有效节点。
从上面的使用方式可以看到,placement constraint是在AM中进行设置的,因此也就只对任务container生效,而AM本身还是由RM按原有的方式进行调度。
当前最新版本的flink与spark都还未支持设置该参数,如需要使用,需要自行修改代码支持。
为任务contaienr申请资源时,placement表达式不是必须的,客户端接口中有两个接口分别对应携带和不带该参数的情况。
【总结】
本文简单介绍了节点属性的背景,如何进行配置,以及如何按照节点属性进行任务的调度。当然,涉及的placement constraint是一个比较庞大的内容,包括详细的表达式设置、AM的代码中应当如何编写对应的代码、RM中的调度逻辑等等,这里没有展开讲解,后面单独来进行整理说明。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请多多转发,也欢迎加我微信交流~