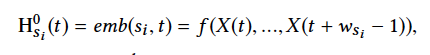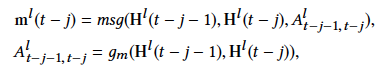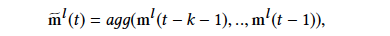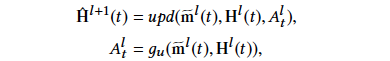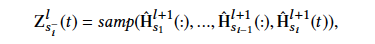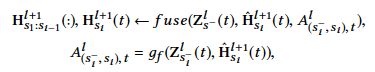摘要:本文提出了一个端到端的MTS预测框架METRO。METRO的核心思想是利用多尺度动态图建模变量之间的依赖关系,考虑单尺度内信息传递和尺度间信息融合。
本文分享自华为云社区《VLDB'22 METRO论文解读》,作者:云数据库创新Lab 。
0 导读
本文(METRO: A Generic Graph Neural Network Framework for Multivariate Time Series Forecasting)是由华为云数据库创新Lab联合电子科技大学数据与智能实验室发表在顶会VLDB‘22的文章,该文章提出了一种的多元时序预测算法METRO。VLDB是CCF推荐的A类国际学术会议,是数据库领域顶级学术会议之一。该论文是云数据库创新LAB在时序分析层面取得的关键技术成果之一。
METRO是基于自注意力机制(self-attention)的深度学习算法。该算法能有效学习历史数据的多种周期性以及提取不同时间线的相关性,为时序预测任务提供更准确的结果,使时序数据库具有强大的分析能力。目前METRO已经作为GaussDB for Influx的时序预测算子在华为云上线,应用场景包括对服务器容量指标进行预测,指导服务器扩容操作;以及对交通路段拥堵程度预测,动态指导地图路径规划等。结合METRO提供的强大分析能力以及GaussDB for Influx已有的超大规模时间线快速读写能力,GaussDB for Influx已具备从大规模时序数据中持续挖掘数据潜在价值的能力。
1 背景
多元时间序列(Mltivariate Time Series, MTS)预测因具有广泛的应用场景而受到越来越多的关注。目前的多元时间序列模型普遍具有以下不足:
- 忽视了变量间依赖关系的动态特性。
- 没有充分考虑一个时间序列内不同尺度的时序模式
因此,本文提出了一个端到端的MTS预测框架METRO。METRO的核心思想是利用多尺度动态图(Multi- scale temperal graph)建模变量之间的依赖关系,考虑单尺度内信息传递和尺度间信息融合。同时,METRO也是一个通用的框架,现有的基于图神经网络的MTS预测模型可以被描述成METRO的特例。我们在公开的真实数据集和华为云的在线生产环境上进行了大量实验,结果表明,METRO在预测准确性,运行时间,模型大小上都优于SOTA。同时,我们也通过例化多个基于METRO的预测模型,展示了他们在性能和时间空间开销之间的的trade-off。
2 METRO
2.1 定义
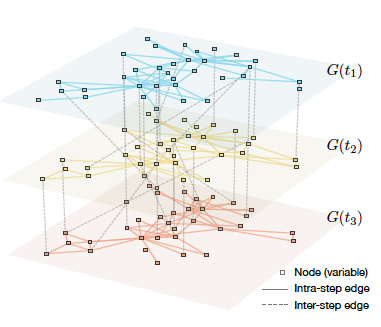
定义1 动态图(Temporal graph): 我们将多元时间序列的变量描述成节点,变量之间的依赖关系描述成边,则动态图G(t)=(V(t),E(t))G(t)=(V(t),E(t))可被用来建模变量之间的动态相关性。动态图可以看作一系列静态图组成的时间序列。如下图所示。
![]()
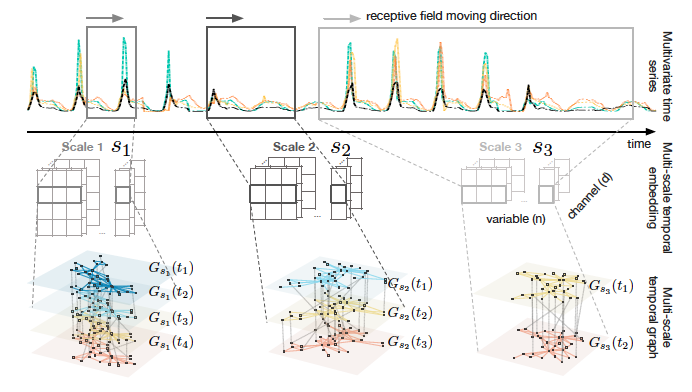
定义2 多尺度动态图(Multi-scale Temporal graph): 若动态图中的每个时间步都是在时间尺度ss下观察/归纳得到的,我们称该动态图是关于尺度ss的,记为G_s(t)=(V_s(t),E_s(t))Gs(t)=(Vs(t),Es(t))。利用多个时间尺度观察原始MTS,则可得到多尺度动态图。如下图所示。
![]()
2.2 模型框架
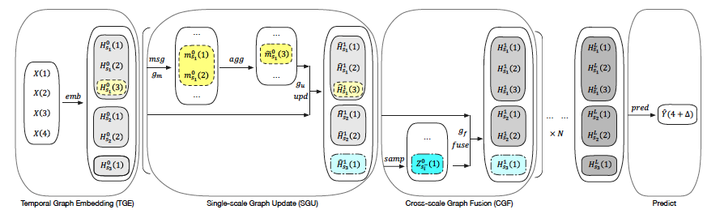
METRO包含四个部分,temporal graph embedding (TGE) 模块,singe-scale graph update (SGU) 模块, cross-scale graph fusion (CGF) 模块 和 predict 模块。
![]()
2.3 TGE
TGE类似编码器,利用函数emb()emb()得到原始MTS中变量对于不同时间尺度s_isi的表示,也即获得动态图中节点的嵌入向量\mathbf{H}^{l}({t})Hl(t)。emb()emb()可被实现成拼接,求和,卷积,LSTM,GRU等等。
![]()
2.4 SGU
对于TGE的到的多尺度动态图,SGU按照尺度分别处理,完成在单一尺度下动态图内的信息传递。
首先,由于变量之间的依赖关系未知且动态变化,我们使用图学习函数g_m()gm()自动学习变量在相邻时间步之间的联系,即邻接矩阵AA, 再通过msg()msg()函数建模相邻时间步之间的信息,记为mm。
![]()
![]()
接下来,agg()agg()函数被用来聚合所有mm,得到\widetilde{m}m,\widetilde{m}m可被看作是一张包含了整体序列信息的新图。对于时间步tt,我们利用所有tt时刻之前的信息聚合得到的\widetilde{m}m来对其进行更新,得到\hat{\mathbf{H}}^{l+1}({t})H^l+1(t)。
![]()
其中,msg(),upd()msg(),upd() 可被实现成GCN,Transformer。agg()agg()可被实现成多数时序模型,例如Transformer,LSTM,GRU等。 g_m(),g_u()gm(),gu()在目前的工作中曾被实现成 transfer entropy,线性层等,也可以利用attention模型。
当对于tt的部分未来信息也可获得时,也可将其加入用于更新,这在本文中被称作SUG-C (SUG-Contextual)。
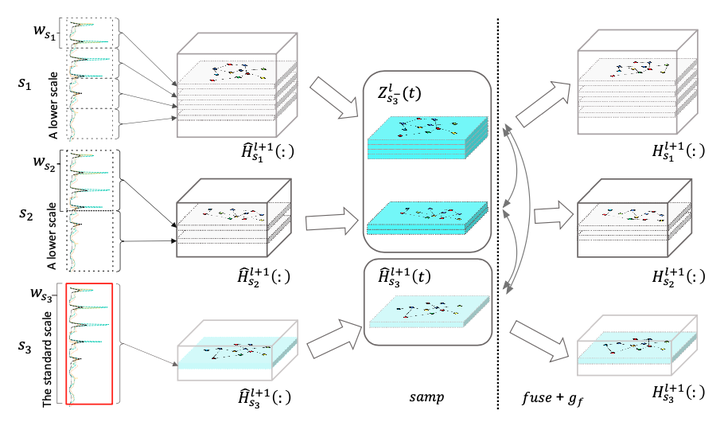
2.5 CGF
![]()
多尺度融合可使模型自动地选择有效的时间尺度组合,以适应当前预测的horizon。在CGF模块,我们首先通过samp()samp()函数找到可融合的时间步,其需满足对应的原始时间片段可对齐。再通过g_f(),fuse()gf(),fuse() 函数进行图结构的学习和信息传播,此步可用的实现与SUG类似。
![]()
![]()
SGU与CGF可堆叠多层,以通过增加深度增加模型expressiveness。
2.6 Predict
最终的预测结果取CGF最后一层,输入pred()pred()函数获得。pred()pred()可被实现为常见的输出层,例如线性层等。
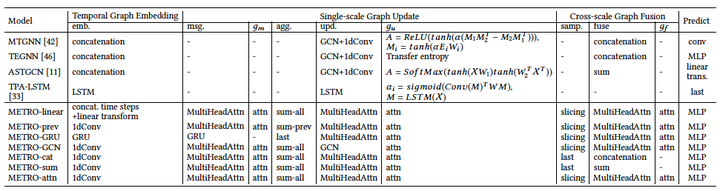
2.7 实例化METRO
我们对METRO进行了如下实例化。
![]()
3 实验
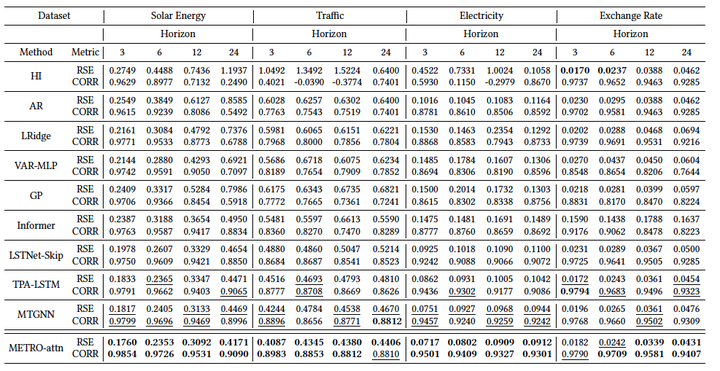
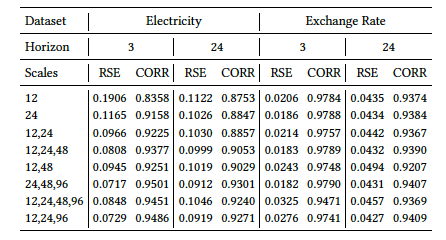
3.1 在公开数据集上与baseline比较
![]()
在四个公开数据集,4个预测horizon上,METRO-attn相对于SOTA模型获得了更好的RSE和CORR。
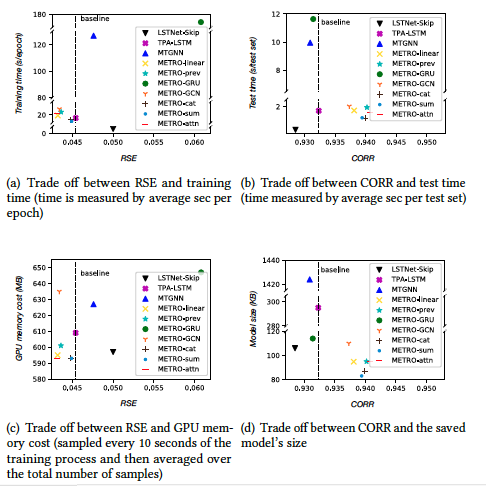
3.2 开销和准确率的权衡
![]()
我们总结了METRO的各个实例化模型对应准确率与训练时间/测试时间/GPU memory/model size的关系,因引入了SOTA模型做比较,发现METRO模型总体开销显著低于SOTA,且由于模块的实现方式不同,METRO模型内部也存在着不同的准确率-开销trade off,其中,METRO-attn是一个有效且相对简单的实现。
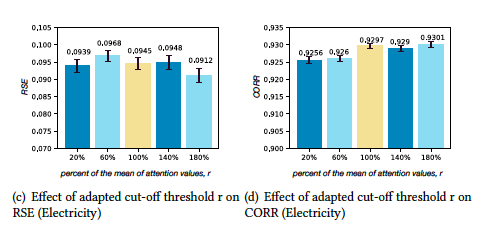
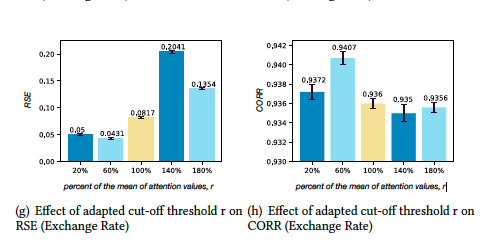
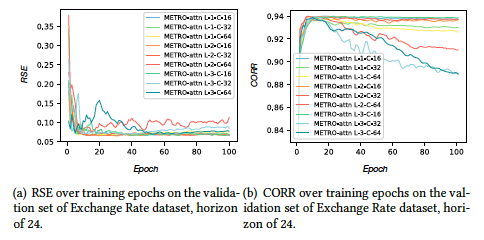
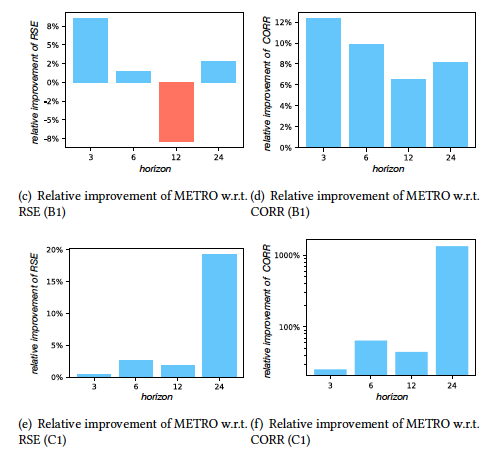
3.3 模型参数分析
![]()
![]()
![]()
![]()
我们在METRO-attn上进行了参数分析,得到了使用较多时间尺度有利,大时间尺度对于长horizon预测有利等结论。
4. 应用
![]()
我们将METRO应用于华为云真实生产环境,于其产生的私人数据集上进一步测试了模型效果,实验表明,METRO显著优于SOTA模型。
5. 总结
本文提出了一个端到端的MTS预测框架METRO。METRO的核心思想是利用多尺度动态图(Multi- scale temperal graph)建模变量之间的依赖关系,考虑单尺度内信息传递和尺度间信息融合。我们在公开的真实数据集和华为云的在线生产环境上进行了大量实验,结果表明,METRO在预测准确性,运行时间,模型大小上都优于SOTA。
目前METRO已经作为GaussDB for Influx的时序预测算子应用在了生产环境中,应用场景包括对服务器容量指标进行预测,指导服务器扩容操作;交通路段拥堵程度预测,动态指导地图路径规划等。结合METRO提供的强大分析能力以及GaussDB for Influx已有的超大规模时间线快速读写能力,GaussDB for Influx已具备从大规模时序数据中持续挖掘数据潜在价值的能力。
华为云数据库创新lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
点击关注,第一时间了解华为云新鲜技术~