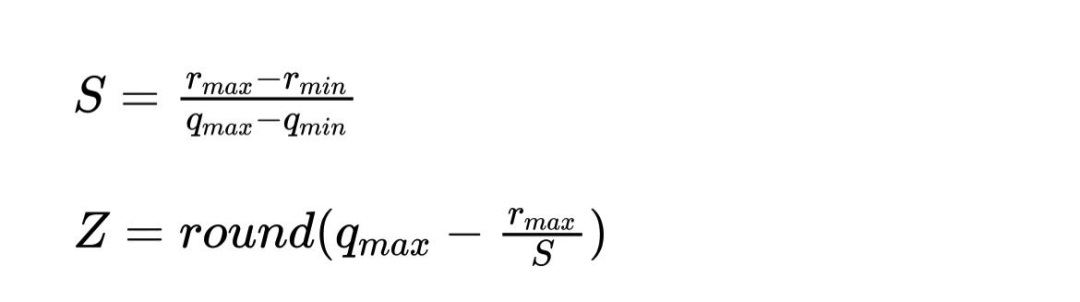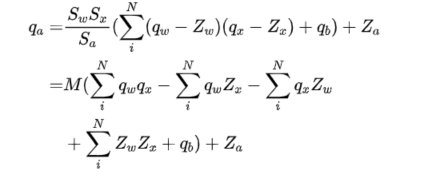这里说的量化一般都是指的Google TFLite的量化方案,对应的是Google 的论文 Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference。虽然TfLite这套量化方案并不是很难,但在实际处理的时候细节还是比较多,一时是很难说清楚的。
// TFLite量化方案,对称量化 template<typename T> voidFakeQuantizationPerLayerSymmetric(const T* in_ptr, const T scale, constint32_t quantization_bit, constint64_t num_elements, T* out_ptr){ T upper_bound = static_cast<T>(pow(2.0, quantization_bit - 1)) - 1; T lower_bound = -upper_bound - 1; FOR_RANGE(int64_t, i, 0, num_elements) { T out = std::nearbyint(in_ptr[i] / scale); out = out > upper_bound ? upper_bound : out; out = out < lower_bound ? lower_bound : out; out_ptr[i] = out * scale; } }
// TFLite量化方案,非对称量化 template<typename T> voidFakeQuantizationPerLayerAffine(const T* in_ptr, const T scale, const T zero_point, constint32_t quantization_bit, constint64_t num_elements, T* out_ptr){ T upper_bound = static_cast<T>(pow(2.0, quantization_bit)) - 1; T lower_bound = 0; uint8_t zero_point_uint8 = static_cast<uint8_t>(std::round(zero_point)); FOR_RANGE(int64_t, i, 0, num_elements) { T out = std::nearbyint(in_ptr[i] / scale + zero_point_uint8); out = out > upper_bound ? upper_bound : out; out = out < lower_bound ? lower_bound : out; out_ptr[i] = (out - zero_point_uint8) * scale; } } // 寒武纪量化方案 template<typename T> voidFakeQuantizationPerLayerCambricon(const T* in_ptr, const T shift, constint32_t quantization_bit, constint64_t num_elements, T* out_ptr){ T upper_bound = static_cast<T>(pow(2.0, quantization_bit - 1)) - 1; T lower_bound = -upper_bound - 1; T scale = static_cast<T>(pow(2.0, static_cast<int32_t>(shift))); FOR_RANGE(int64_t, i, 0, num_elements) { T out = std::nearbyint(in_ptr[i] / scale); out = out > upper_bound ? upper_bound : out; out = out < lower_bound ? lower_bound : out; out_ptr[i] = out * scale; } }
需要注意的一点是由于FakeQuantization要参与训练,所以我们要考虑梯度怎么计算?从上面的三个核心函数实现中我们可以发现里面都用了std::nearbyint函数,这个函数其实就对应numpy的round操作。而我们知道round函数中几乎每一处梯度都是0,所以如果网络中存在这个函数,反向传播的梯度也会变成0。因此为了解决这个问题,引入了Straight Through Estimator。即直接把卷积层(这里以卷积层为例子,还包含全连接层等需要量化训练的层)的梯度回传到伪量化之前的weight上。这样一来,由于卷积中用的weight是经过伪量化操作的,因此可以模拟量化误差,把这些误差的梯度回传到原来的 weight,又可以更新权重,使其适应量化产生的误差,量化训练也可以正常运行。具体的实现就非常简单了,直接将dy赋值给dx,在OneFlow中通过identity这个Op即可:给FakeQuantization注册梯度,直通估计器
defforward(self, x): if hasattr(self, 'qi'): self.qi.update(x) x = self.qi.fake_quantize_tensor(x)
self.qw.update(self.conv_module.weight)
x = flow.F.conv2d(x, self.qw.fake_quantize_tensor(self.conv_module.weight), self.conv_module.bias, stride=self.conv_module.stride, padding=self.conv_module.padding, dilation=self.conv_module.dilation, groups=self.conv_module.groups)
if hasattr(self, 'qo'): self.qo.update(x) x = self.qo.fake_quantize_tensor(x)
return x
deffreeze(self, qi=None, qo=None):
if hasattr(self, 'qi') and qi isnotNone: raise ValueError('qi has been provided in init function.') ifnot hasattr(self, 'qi') and qi isNone: raise ValueError('qi is not existed, should be provided.')
if hasattr(self, 'qo') and qo isnotNone: raise ValueError('qo has been provided in init function.') ifnot hasattr(self, 'qo') and qo isNone: raise ValueError('qo is not existed, should be provided.')
if qi isnotNone: self.qi = qi if qo isnotNone: self.qo = qo self.M = self.qw.scale.numpy() * self.qi.scale.numpy() / self.qo.scale.numpy()
defforward(self, x): x = F.relu(self.conv1(x)) x = F.max_pool2d(x, 2, 2) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, 2, 2) x = x.reshape(-1, 5*5*40) x = self.fc(x) return x
defforward(self, x): x = self.quant(x) x = self.relu1(self.conv1(x)) x = self.pool1(x) x = self.relu2(self.conv2(x)) x = self.pool2(x) x = x.reshape(-1, 5*5*40) x = self.fc(x) x = self.dequant(x) return x
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。