宏观了解 Kettle
上一篇中对 Kettle 进行了简单的介绍,并快速体验了一把 Kettle,完成了「把数据从 CSV 文件复制到 Excel 文件」 HelloWrold 级别的功能。
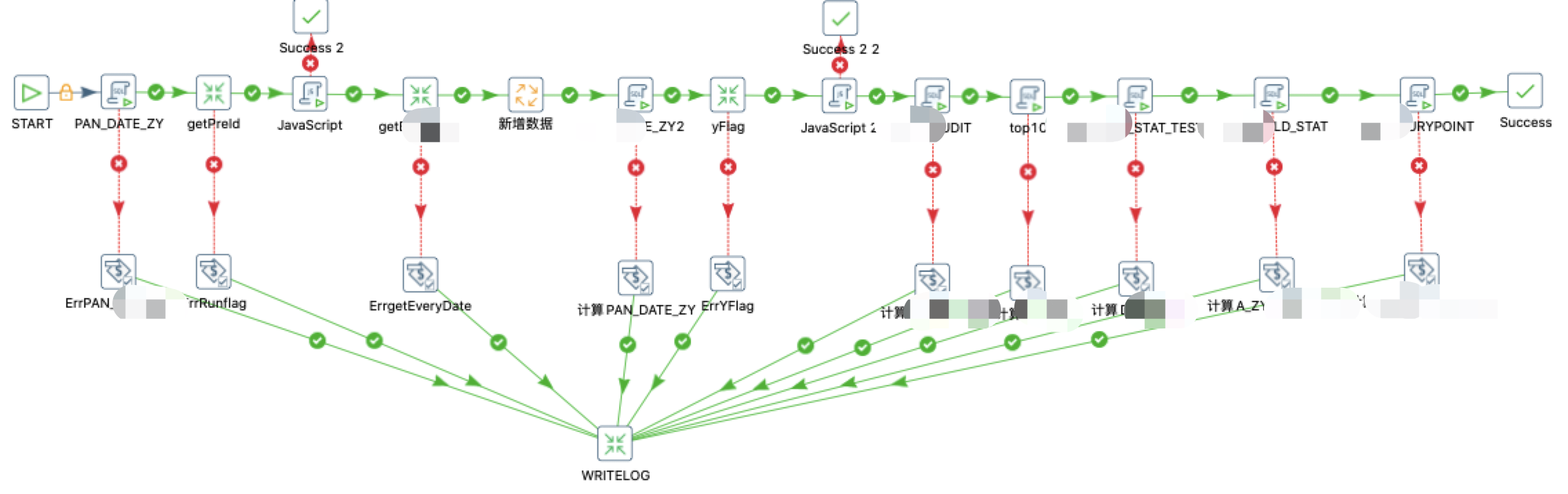
而在实际工作中,可以使用 Kettle 的图形化的方式定义复杂的 ETL 程序和工作流,如下图就是通过一系列的转换(Transformation) 完成一个作业(Job)流程。
![image-20210707143745802]()
Kettle 核心概念
![image-20210708004806905]()
转换
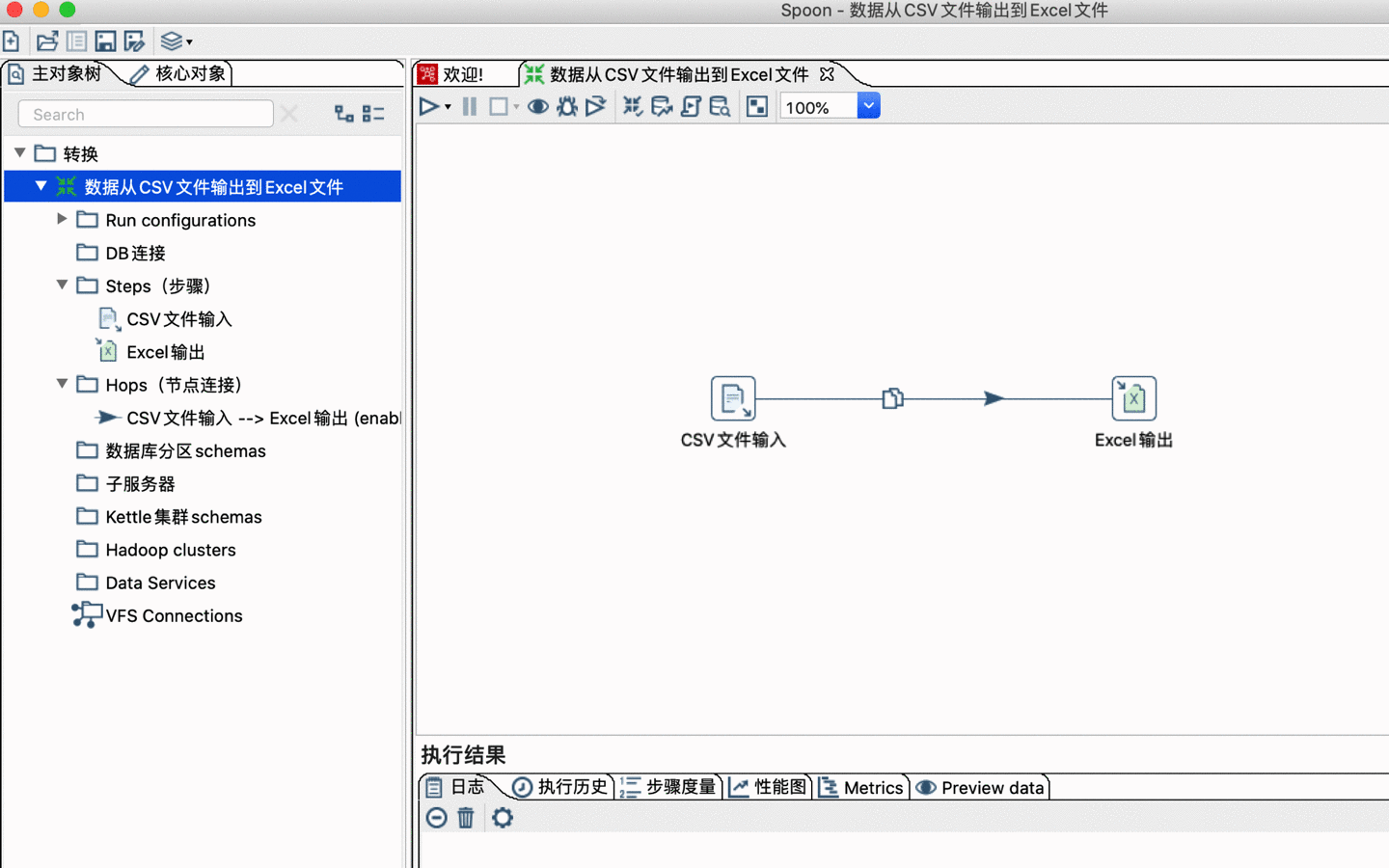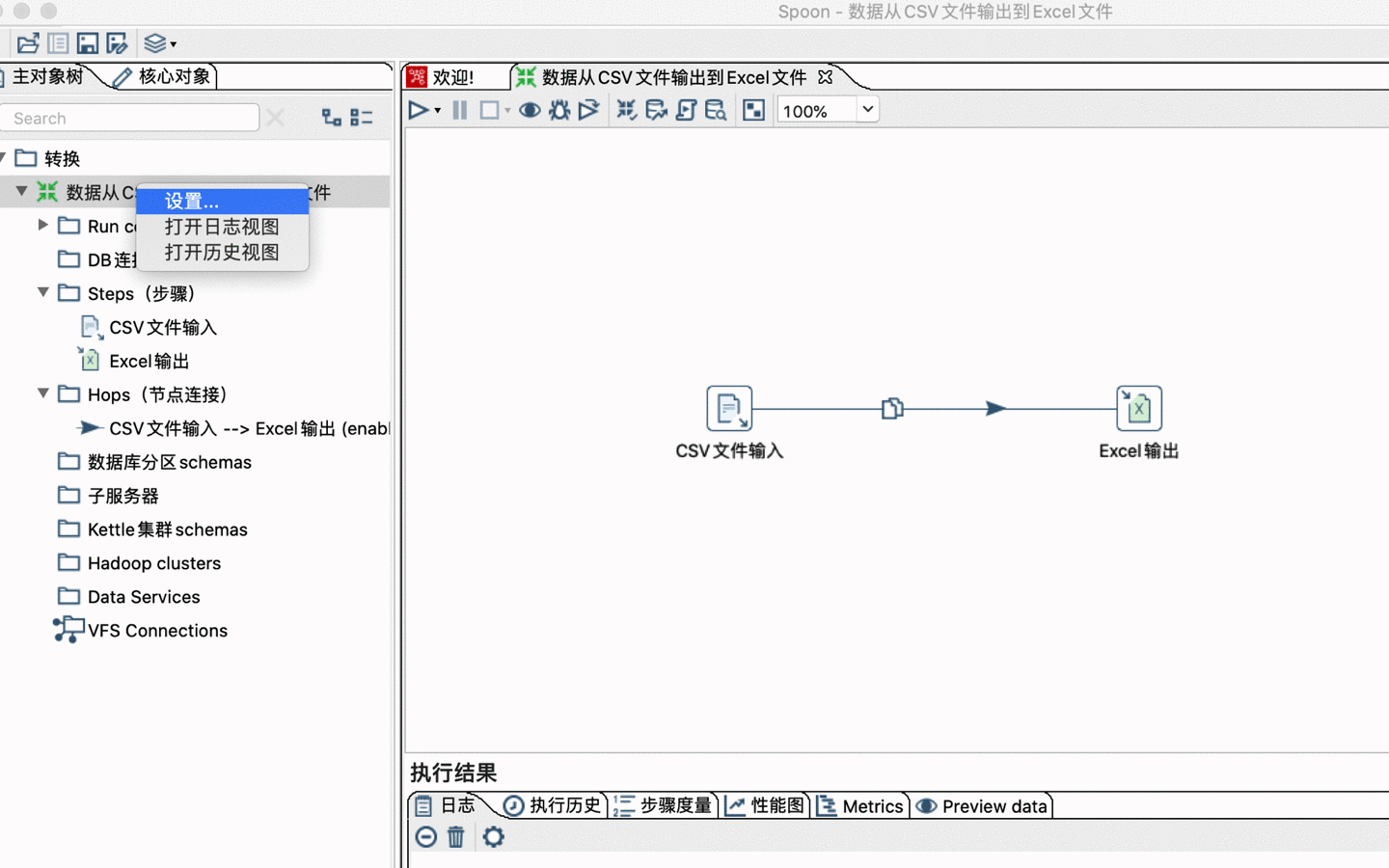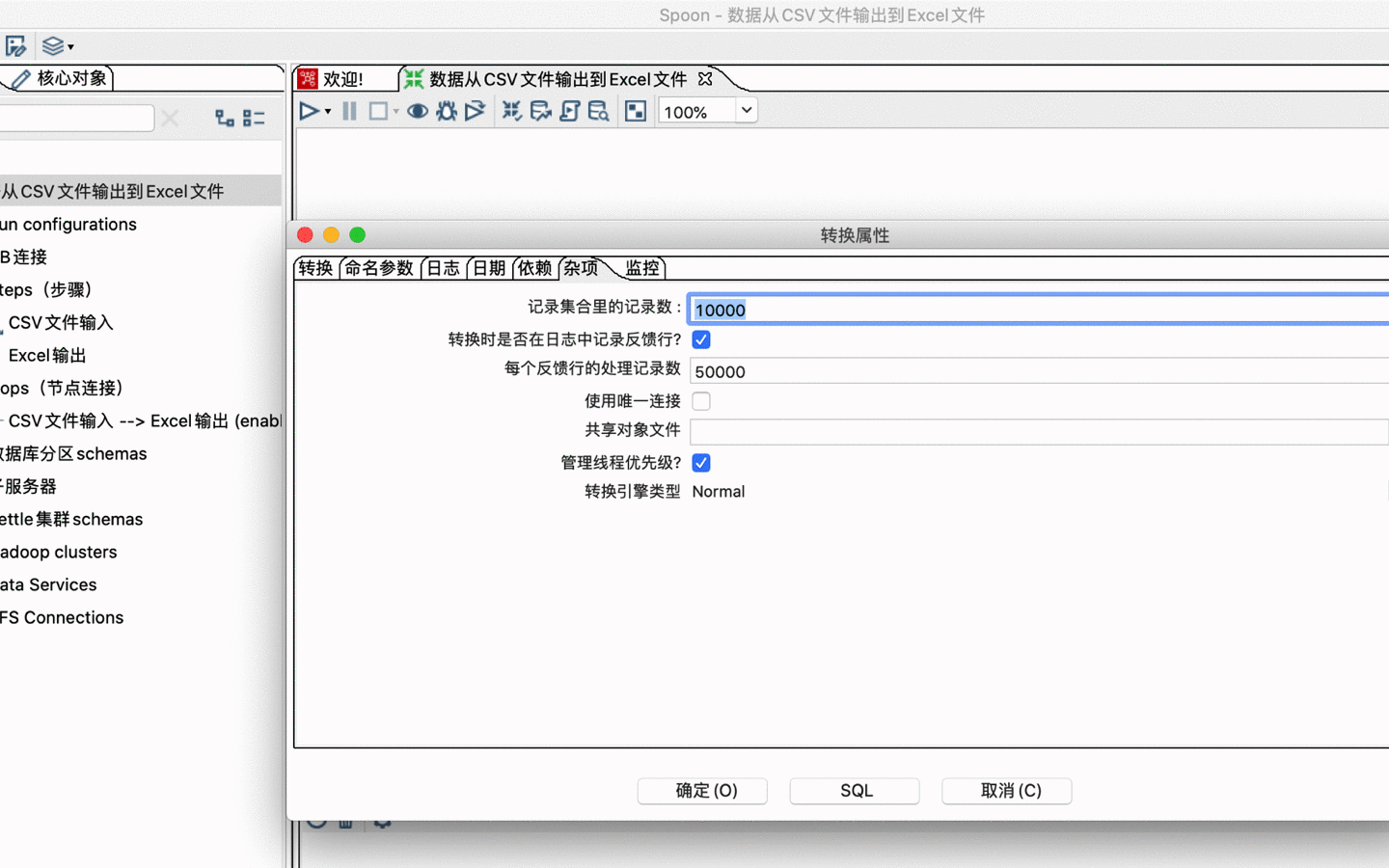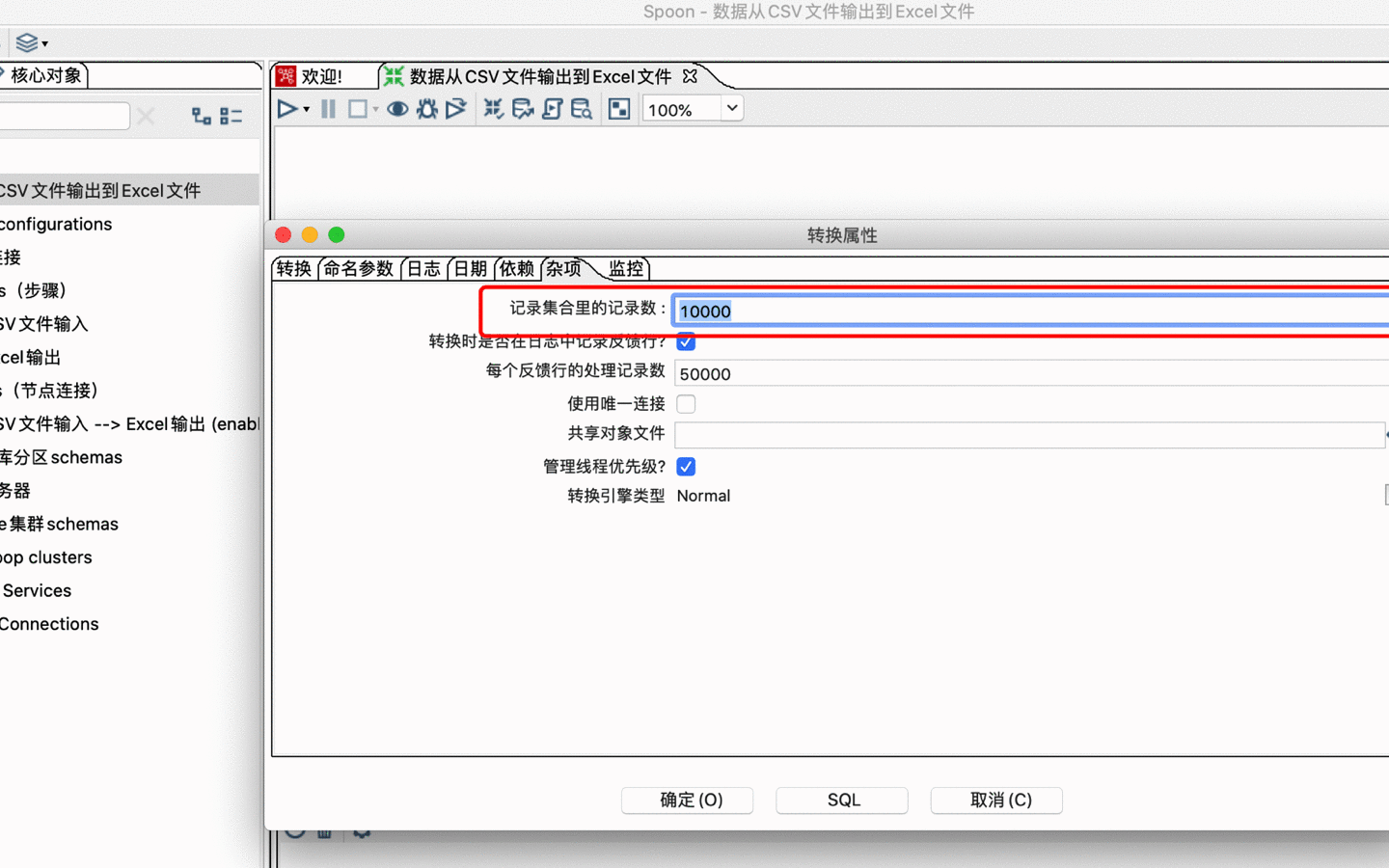
转换(Transaformation)是 ETL 中最主要的部分,它处理抽取、转换、加载各种对数据行的操作。 转换包含一个或多个步骤(Step),如上图中的「CSV 文件输入」、「Excel输出」步骤,还包括过滤数据行、数据清洗、数据去重或将数据加载到数据库等等。 转换里的步骤通过跳(hop)来进行连接,跳定义一个单向通道,允许数据从一个步骤向另一个步骤流动。
步骤(Step)
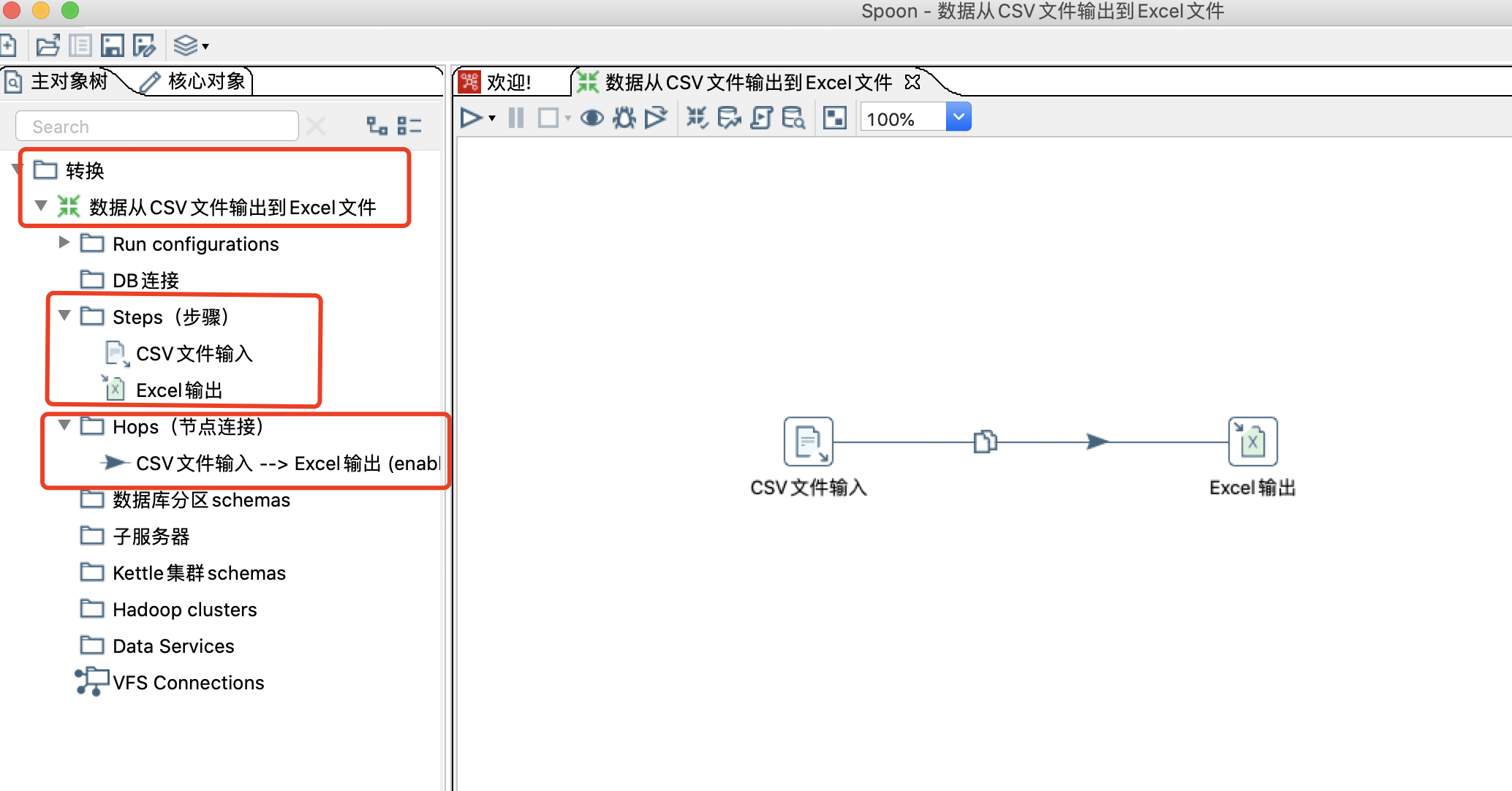
![image-20210708010417687]()
Kettle 里面的,Step 步骤是转换里的基本的组成部分,上篇快速体验的案例中就存在两个步骤,「CSV文件输入」和「Excel输出」,一个步骤有如下几个关键特性:
-
步骤需要有一个名字,这个名字在转换范围内唯一。
-
每个步骤都会读、写数据行(唯一例外是「生成记录」步骤,该步骤只写数据)。
-
步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。
-
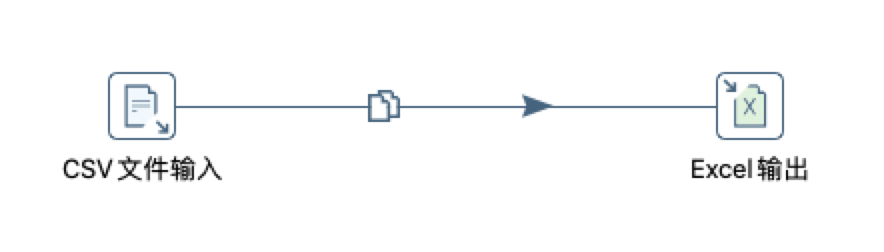
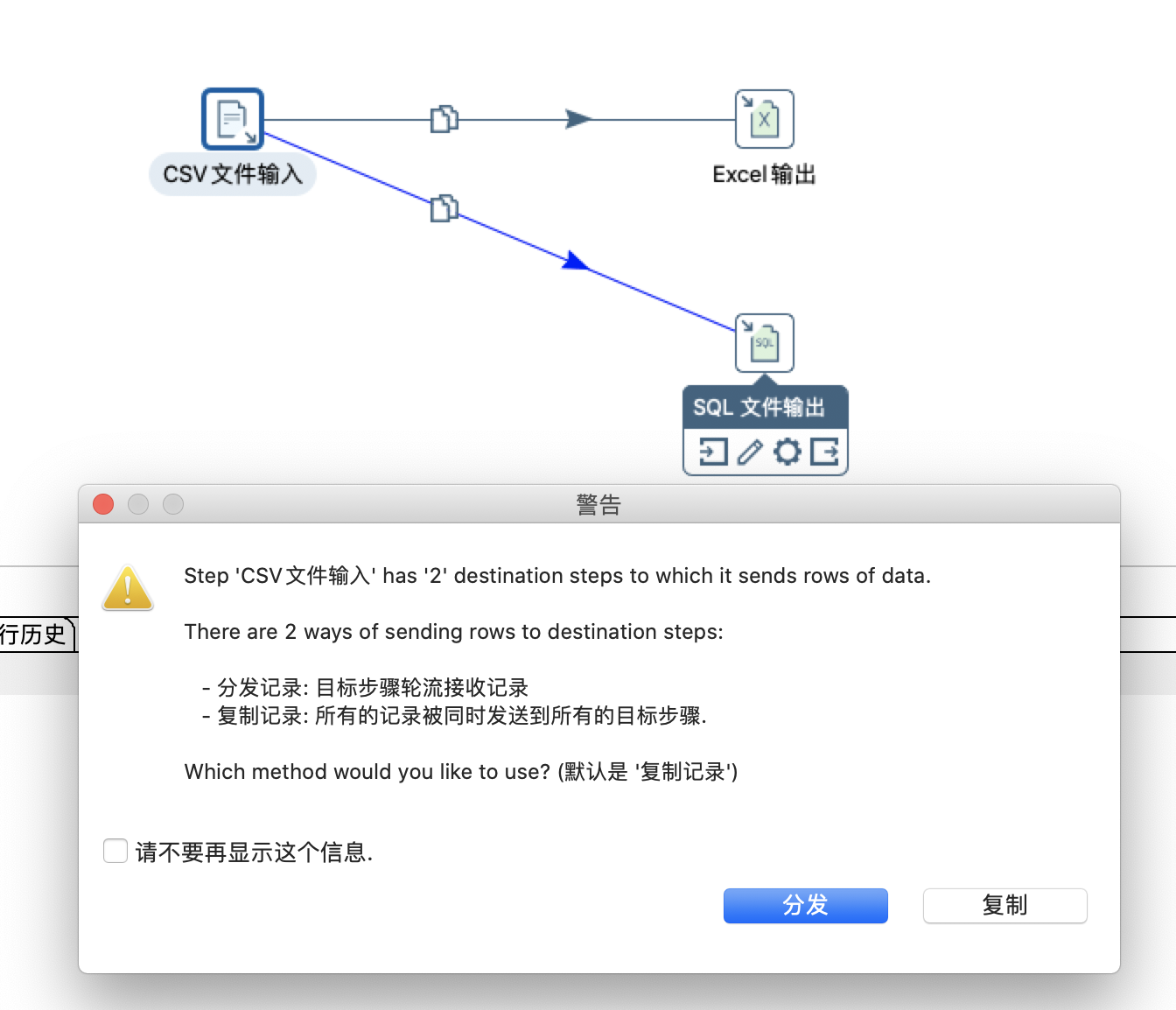
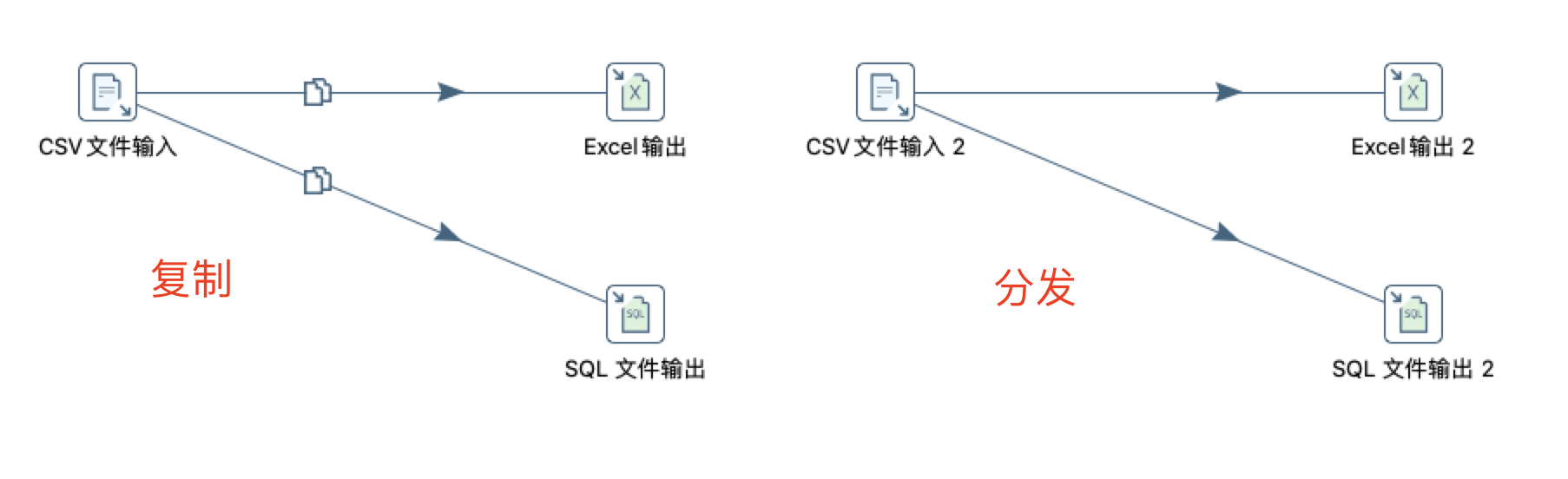
大多数的步骤都可以有多个输出跳,当有多个输出时,会弹出如下图所示的警告进行选择分发还是复制。一个步骤的数据发送可以被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
![image-20210708010916460]()
![image-20210708011405544]()
跳(Hop)
![image-20210708011632619]()
Kettle 里面的,跳(Hop),跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路,如上图。在 Kettle里,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动, 跳是两个步骤之间的被称之为行集的数据行缓存(行集的大小可以在转换的设置里定义,如下图)。当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间;当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
![行集设置]()
数据行
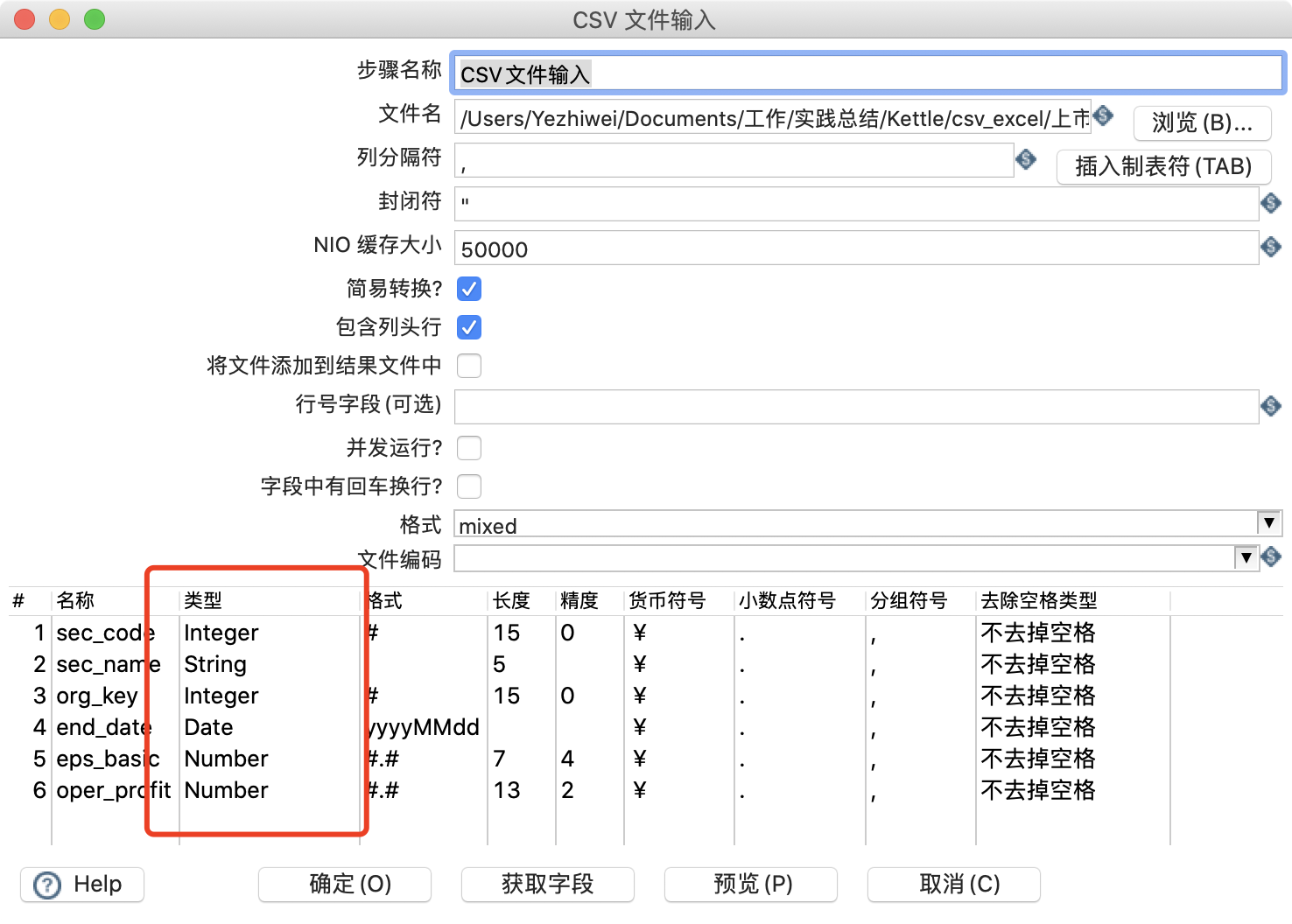
在 Kettle 里,数据的单位是行,数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
- String:字符类型数据
- Number:双精度浮点数
- Integer:带符号长整型(64位)
- BigNumber:任意精度数据
- Date:带毫秒精度的日期时间值
- Boolean:取值为 true 和 false 的布尔值
- Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据
![image-20210708013817323]()
同时,每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。通常包含下面一些信息:
- 名称:行里的字段名应用是唯一的
- 数据类型:字段的数据类型
- 格式:数据显示的方式,如 Integer 的#、0.00
- 长度:字符串的长度或者 BigNumber 类型的长度
- 精度:BigNumber 数据类型的十进制精度
- 货币符号:¥
- 小数点符号:十进制数据的小数点格式
- 分组符号:数值类型数据的分组符号
步骤是并行的
这种基于行集缓存的规则(前面 「跳(Hop)」节提到),允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理(设置合理的行集大小)。在数据仓库建设过程中,经常要处理大量数据,所以这种并发低消耗内存的方式也是 ETL 工具的核心需求。
对于 Kettle 的转换,所有步骤都以并发方式执行,即:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输入跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。
总结
- Kettle 通过一系列的转换(Transformation) 完成一个作业(Job)流程
- 通过了解 Kettle 的核心概念,得知 Kettle 是通过「跳(Hop)」将数据流从一个步骤到另一个步骤的移动,每个步骤都是由一个独立的线程运行,这样提高并发程度,但相比 Hadoop 生态移动计算模型更加昂贵
- Kettle 本身由 Java 开发,需要配置合理的 JVM 参数
欢迎关注公众号:HelloTech,获取更多内容