文章首发于公众号 “蘑菇睡不着”
前言
Redis 的主从复制和 MySQL 差不多,主要起着 数据备份,读写分离等作用。所以说主从复制对 Redis 来说非常重要,而无论是面试还是工作总,了解 Redis主从复制 底层实现有非常有必要,那么接下来就和大家来看看 Redis 主从复制是怎么实现的吧。
什么是 Redis 主从复制?
在 Redis 中,我们可以通过 SLAVEOF 命令或者 slaveof 选项,让一个服务器去复制另一个服务器,被复制的服务器称为“主服务器”,发起复制的服务器称为“从服务器”,由两种服务器组成的模式称为“主从复制”。
![]()
Redis 主从复制有以下特点:
- Redis 使用异步复制,slave 和 master 之间异步地确认处理的数据量。
- 一个 master 可以拥有多个 slave。
- slave 可以接受其他 slave 的连接。除了多个 slave 可以连接到同一个 master 之外, slave 之间也可以像层叠状的结构(cascading-like structure)连接到其他 slave 。自 Redis 4.0 起,所有的 sub-slave 将会从 master 收到完全一样的复制流。
- Redis 复制在 master 侧是非阻塞的。这意味着 master 在一个或多个 slave 进行初次同步或者是部分重同步时,可以继续处理查询请求。
- 复制在 slave 侧大部分也是非阻塞的。当然这个是可配的,如果在 redis.conf配置是非阻塞的,可以使用旧数据集处理查询请求;如果配置的是阻塞的,slave 会返回一个 error 给客户端。
怎么实现主从复制?
假设现在有两个 Redis 服务器,地址分别为 127.0.0.1:6379 和 127.0.0.1:12345,如果在服务器 127.0.0.1:12345 执行以下命令:
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
那么服务器127.0.0.1:12345就是127.0.0.1:6379 的从服务器。主从服务器的数据会保持一致
比如主服务器存储数据:
127.0.0.1:6379> set msg "hello world"
OK
然后从服务器就能直接获取数据:
127.0.0.1:12345>get msg
"hello world"
删除数据也是一样,主从会保持一致。
主从复制原理
首先,Redis 的复制分为同步(sync)和命令传播(command propagate)两个操作:
- 同步操作用于将从服务器数据库的状态更新为主服务器所处的状态。
- 命令传播则相反,它主要作用在主服务器的数据库状态更改时,导致主从服务器的数据库状态出现不一致时,让主从回到一致的的过程。
接下来详细说说这两种复制。
同步
![]()
文字解说:
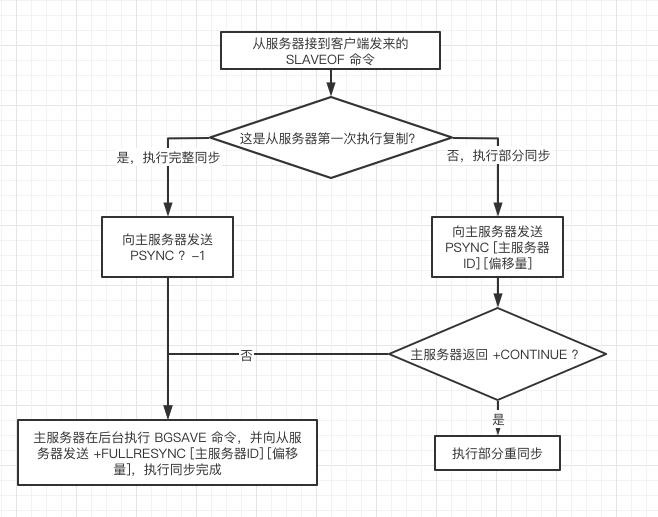
- 客户端向从服务器发送 SLAVEOF 命令,先是判断是否是第一次复制,第一次是复制一般是刚开始组建主从关系。
- 是第一次复制:从服务器会向主服务器发送 PSYNC ? -1 命令,请求主服务器执行完整重同步操作。
- 主服务器接到完整重同步请求之后,将在后台执行 BGSAVE 命令,在后台生成一个 RDB 文件,并使用一个复制积压缓冲区记录从现在开始执行的所有写命令。
- BGSAVE 命令执行完毕之后,主服务器会将 RDB 文件以及 缓冲区中记录的写命令发送给从服务器,还会向从服务器返回 +FULLRESYNC [主服务器ID] [复制偏移量](和图中的 偏移量 是一个)。
- 从服务器接收到后,会载入 RDB 文件,并执行 主服务器给的 写命令,以此来达到和主服务器一致的数据状态。
- 如果不是第一次复制,那么说明从服务器可能是断线,导致和主服务器数据状态不一致,需要同步主服务器的数据。那么从服务器会按照下面的步骤来请求部分同步。
- 向主服务器发送 PSYNC [主服务器ID] [复制偏移量](这个是第一次复制时主服务器传过来的),主服务器ID 时断线前的主服务器,用于定位去同步那个主服务器的;复制偏移量是上一次同步的位置,用于定位具体的同步位置的。
- 主服务器接收到从服务器的命令后,并找到相应同步的位置后,会给从服务器发送 +CONTINUE 命令,表示将于从服务器执行部分同步操作,之后主服务器会将保存在复制积压缓冲区对应 复制偏移量之后的所有数据发送给从服务器,但是如果找不到偏移量之后的数据,就会进行完整同步,这样就可以让从服务器达到和主服务器一致的状态。
命令传播
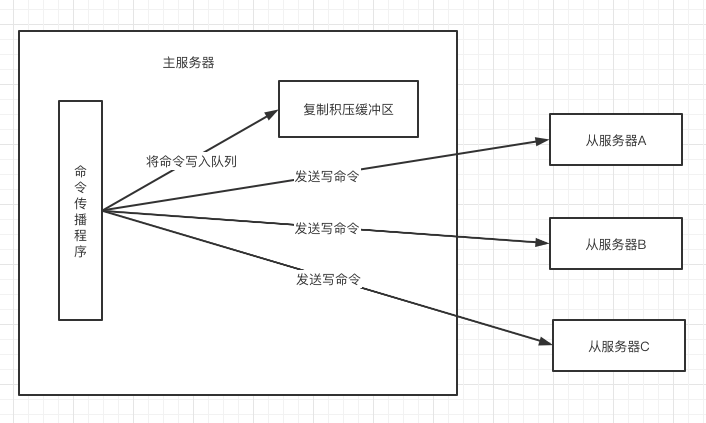
主从服务器同步成功后,并不会一致保持这个状态,主服务器可能会执行写命令,这也主从数据就不知一致了。
为了处理这种问题,主服务器会把自己执行的写命令发送给从服务器,当从服务器执行完这些命令之后,主从服务器的数据就一致了。
![]()
在命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令:
REPLCONF ACK <replication_offset>
<replication_offset> 是从服务器当前的复制偏移量。
发送 REPLCONF ACK 命令对于主从服务器有三个作用:
- 检测主从服务器的网络状态。
- 辅助实现 min-slaves 选项。
- 检测命令丢失。
关键词讲解
- 主服务器ID:用于标识一个服务器。
- 每个服务器,无论是主服务器还是从服务器都有属于自己独一无二的 服务器ID。
- ID 在服务器启动时生成,由 40 个随机的十六进制字符组成。
- 复制积压缓冲区:复制积压缓冲区是由主服务器维护的一个固定长度、先进先出(FIFO)队列,默认大小为 1MB。如下:
| 偏移量 |
... |
10086 |
10087 |
10088 |
10089 |
... |
| 字节值 |
... |
3 |
'\r' |
'\n' |
'$' |
... |
总结
Redis 主从复制主要是通过 PSYNC 命令实现。
复制分为 部分复制 以及 完整复制。
部分复制通过 复制偏移量、复制积压缓冲区、服务器ID来实现。
完整复制通过 RDB 以及 复制积压缓冲区来实现。
主从复制主要解决的是 数据备份、读写分离的问题。
最后
如果觉得文章对你有帮助,点赞、关注、转发 统统走起来~
可以去公众号 蘑菇睡不着 看看,更多精彩内容等你。