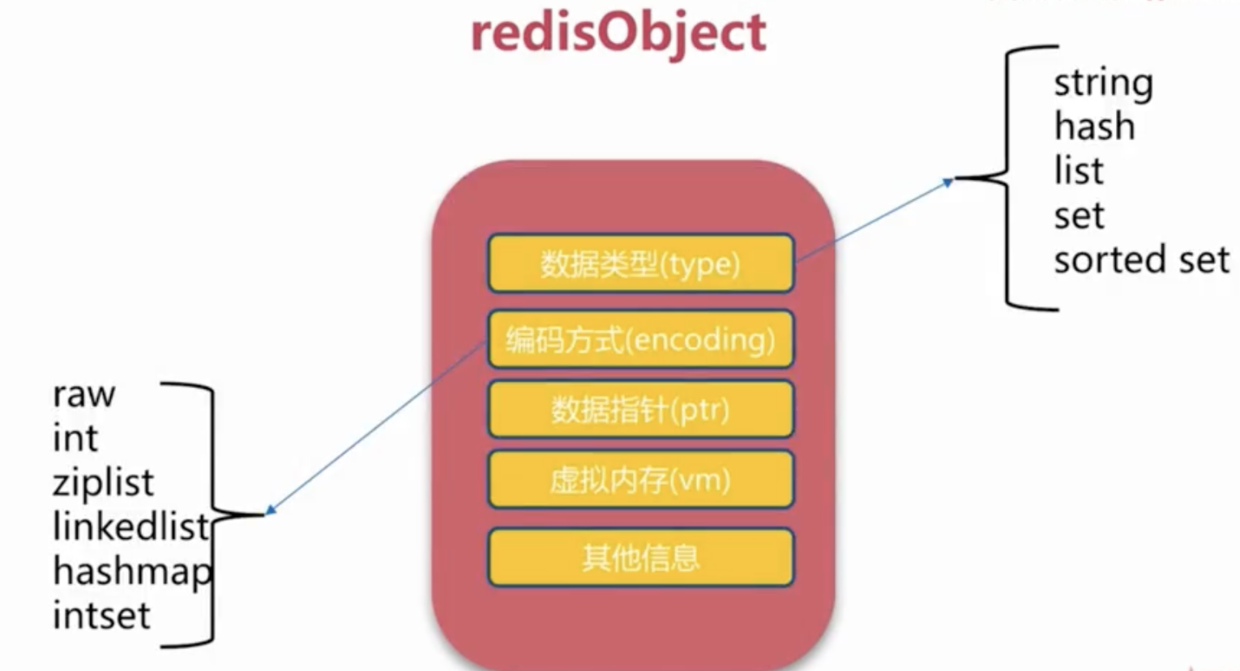
Redis 内部使用一个 RedisObject 对象来表示所有的 key 和 value,RedisObject 中的 type,则是代表一个 value 对象具体是何种数据类型,它包含字符串(String)、链表(List)、哈希结构(Hash)、集合(Set)、有序集合(Sorted set)。
![]()
日常工作中我们存储对象信息的时候,一般有两种做法,一种是用 Hash 存储,另一种是 String 存储。但好像并没有所谓的最佳实践,那么实际上到底用什么数据结构存储更好呢?
首先简单回顾下,Redis 的 Hash 和 String 结构。
String
String 数据结构是简单的 key-value 类型,value 其实不仅是 String,也可以是数字。Redis 中的 String 可以表示很多语义:
这三种类型,Redis 会根据具体的场景完成自动转换,并且根据需要选取底层的承载方式。String 在Redis 内部存储默认就是一个字符串,被 RedisObject 所引用,当遇到 incr、decr 等操作时会转成数值型进行计算,此时 RedisObject 的 encoding 字段为int。
在存储过程中,我们可以将用户信息使用 Json 序列化成字符串,然后将序列化后的字符串存入 Redis 进行缓存。

由于 Redis 的字符串是动态字符串,可以修改,内部结构类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。如上图所示,内部为当前字符串实际分配的空间 capacity,一般高于实际字符串长度 len。
假设我们要存储的结构是:
{
"name": "xiaowang",
"age": "35"
}
如果此时将此用户信息的 name 改为“xiaoli”,再存到 Redis 中,Redis 是不需要重新分配空间的。而且我们在读取和存储数据的时候只需要对做 Json 序列化与反序列化,比较方便。
Hash
Hash 在很多编程语言中都有着很广泛的应用,而在 Redis 中也是如此。在 Redis 中,Hash 常常用来缓存一些对象信息,如用户信息、商品信息、配置信息等,因此也被称为字典(dictionary),Redis 的字典使用 Hash table 作为底层实现, 一个 Hash table 里面可以有多个哈希表节点,而每个哈希表节点保存了字典中的一个键值对。实际上,Redis 数据库底层也是采用 Hash table 来存储键值对的。
Redis 的 Hash 相当于 Java 的 HashMap,内部结构实现与 HashMap 一致,即数组+链表结构。只是 reHash 方式不一样。

前面说到 String 适合存储用户信息,而 Hash 结构也可以存储用户信息,不过是对每个字段单独存储,因此可以在查询时获取部分字段的信息,节省网络流量。不过 Redis 的 Hash 的值只能是字符串,存储上面的那个例子还好,如果存储的用户信息变为:
{
"name": "xiaowang",
"age": 25,
"clothes": {
"shirt": "gray",
"pants": "read"
}
}
那么该如何存储"clothes"属性又变成了该用 String 还是 Hash 的问题。
String 和 Hash 占用内存的比较
既然两种数据结构都可以存储结构体信息。到底哪种更加合适呢?
首先我们用代码先插入 10000 条数据,然后用可视化工具来看看内存的占用情况。
const Redis = require("ioRedis");
const Redis0 = new Redis({port: 6370});
const Redis1 = new Redis({port: 6371});
const user = {
name: 'name12345',
age: 16,
avatar: 'https://dss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=256767015,24101428&fm=26&gp=0.jpg',
phone: '13111111111',
email: '1111111@11.email',
lastLogon: '2021-04-28 10:00:00',
}
async function main() {
for (let i = 0; i < 10000; i++) {
await Redis0.set(`String:user:${i}`, Json.Stringify(user));
await Redis1.hmset(`Hash:user:${i}`, user);
}
}
main().then(process.exit);
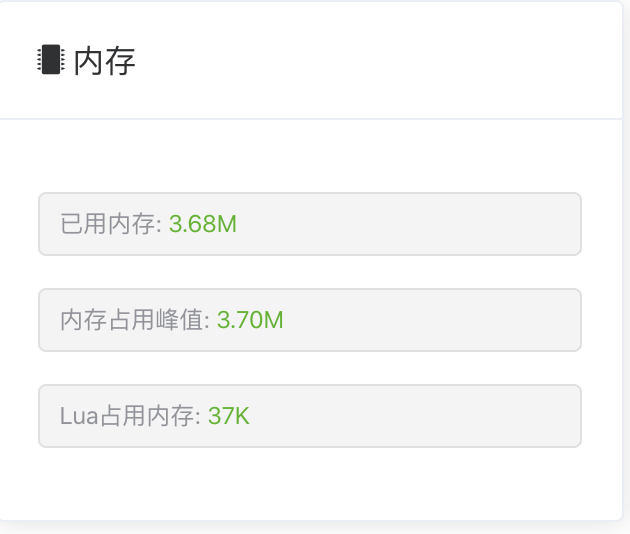
先看 Redis0:
![]()
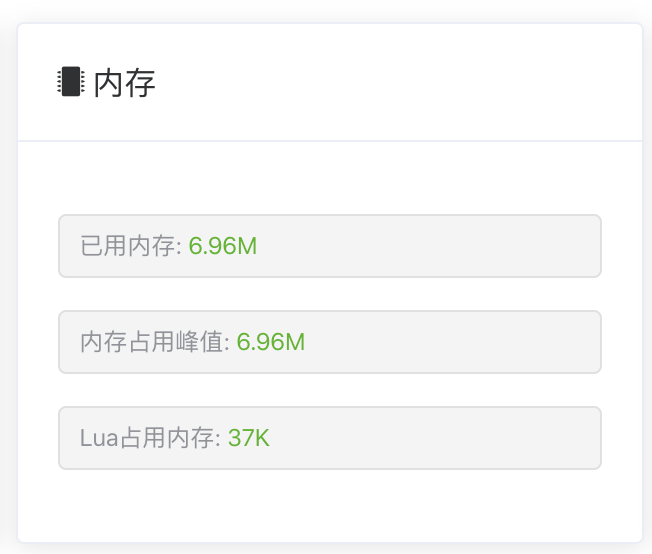
再来看看 Redis1:
![]()
可以看到还是有点差距的,但是差距并不明显。
网友讨论
网上的用户也有同样的疑问, 因为值的长度是不确定的,所以不知道采用 String 还是 Hash 存储更有效率。
")
这里我主要给大家翻译下该问题下优质的答案:
适合用 String 存储的情况:
-
每次需要访问大量的字段
-
存储的结构具有多层嵌套的时候
适合用 Hash 存储的情况:
总结
本文主要介绍了Redis 存储对象信息是用 Hash 还是 String,建议是大部分情况下使用 String 存储就好,毕竟在存储具有多层嵌套的对象时方便很多,占用的空间也比 Hash 小。当我们需要存储一个特别大的对象时,而且在大多数情况中只需要访问该对象少量的字段时,可以考虑使用 Hash。
推荐阅读
告别DNS劫持,一文读懂DoH
Flink 在又拍云日志批处理中的实践


")
