![浅谈前端异常监控平台实现方案]()
异常捕获是改善软件质量的跟踪手段之一,常见的方式是记录日志,从日志分析异常问题进而跟进。对于前端项目来说,异常可能是后端接口数据导致,可能是前端本身业务逻辑问题导致,不管是什么导致的异常,只要能够精准的捕获到就能够分析出问题所在。可能有小伙说有测试阶段,全面的测试机制的确能够降低异常的出现,但是测试大部份情况是在非生产环境上进行的,覆盖面有限。
日志是收集异常的最佳方式,一个异常监控平台就需要包括异常采集、异常存储、异常统计与分析、异常报告、异常告警,而对于一个通用平台来说,就需要项目管理、版本管理、团队管理、仓库管理等等。本文主要介绍一下异常采集需要考虑的问题,并跟大家分享两种现成的解决方案。
异常介绍
异常,是每种编程语言都需要考虑的一种结构,如何友好的跟踪异常而不影响生产环境上的业务,这就需要从项目开发到上线整个过程做一定的规范。下面就来谈谈前端的异常及处理方式。
异常分类
先来说说JavaScript的错误类型,ECMA-262 定义了 7 种错误类型,说明如下:
Error:普通异常,通常与 throw 语句和try/catch 语句一起使用,利用属性 name 可以声明或了解异常的类型,利用message 属性可以设置和读取异常的详细信息。
EvalError:Eval 函数执行异常。
SyntaxError:语法解析不合理,即语法错误。
RangeError:在数字超出合法范围时抛出,比如数组下标越界就会报这种错误。
ReferenceError:在读取不存在的变量时抛出,比如没定义变量 a,后面却使用这个变量 a,就会报这种错。
TypeError:当一个值的类型错误时抛出该异常,比如传递给函数的参数与预期的不符,就会报这种错误。
URIError:以一种错误的方式使用全局 URI 处理函数而产生的错误
异常处理
前端捕获异常分为全局捕获和单点捕获。全局捕获代码集中,易于管理;单点捕获作为补充,对某些特殊情况进行捕获,但分散,不利于管理,容易遗漏。在项目开发过程中,定义一个错误捕获模块,将项目所有的异常(全局异常和单点异常)都交给错误模块来统一处理,这就需要项目约定。
try-catch
try-catch 语句,是 JavaScript 处理异常的一种标准方式。基本语法如下:
try {
} catch (error) {
// 错误处理
}
try 块中的代码发生了错误,就会立即退出代码执行过程,然后执行 catch 块。catch 块会接收到一个包含错误信息的对象。一般是error.message。
finally
finally 在 try-catch 语句中是可选的,如果 finally 子句已经使用,则其代码无论如何都会执行。无论 try 或 catch 语句块中包含什么代码——甚至 return 语句,都不会阻止 finally 子句的执行。只要代码中包含 finally 子句,那么无论 try 还是 catch 语句块中的 return 语句都将被忽略。因此,在使用 finally 子句之前,一定要非常清楚想让代码怎么样。看下面这个函数:
const errorHelper = () => {
try {
return devpoint;
} catch (error) {
return "error";
} finally {
return "不管有无错误,我都执行了!";
}
};
console.log(errorHelper()); // 函数本身是发生了异常,但是最终打印的结果为:不管有无错误,我都执行了!
上面的函数代码实际上是有异常的,因为变量 devpoint 并没有定义,不过最终执行了 finally 子句输出了 不管有无错误,我都执行了!。
throw
与 try-catch 语句相配的 throw 操作符,用于随时的主动抛出自定义错误。
const errorHelper = () => {
try {
return devpoint;
} catch (error) {
return "error";
} finally {
throw new Error("devpoint变量未定义");
}
};
console.log(errorHelper());
window.onerror
window.onerror,是全局异常捕获,对于单点异常捕获不到的异常就到这里了。
异常采集
触发异常有很多原因,为了更好的分析,除了捕获程序的错误信息外,还需要采集执行程序的外部环境,对于前端项目,外部环境就包括系统(Window、IOS、Android)和系统版本、浏览器(Chrome、IE、火狐等)和版本、IP地址、用户信息、运行的页面、网络环境、API接口数据。针对这些信息就需要设计采集的日志结构。
在采集异常日志的时候,有个原则需要注意:采集日志行为不影响用户体验及应用本身的性能。
下面是一个参考的日志结构:
projectId:项目信息eventId:事件ID,日志的唯一标志stack:错误stack信息requestId:开发者定义的异常标志level:异常级别,可以是 error、info、warnbrowser:浏览器信息device:设备信息os:操作系统信息release:应用版本信息url:异常触发页面urluser:用户信息,可以是iPcreateAt:异常产生时间network:网络信息eventKey:触发的键dataRes:API响应数据screenWidth:屏幕宽度screenHeight:屏幕高度message:异常详细信息
异常上报
收集到异常数据如何上报呢?即需要将异常日志收集到云端存储,供项目开发跟进分析,一种方式是直接通过API异步上报,在捕获信息比较多的情况下,还是会占用网络请求,影响应用本身。可以考虑将采集的异常日志存储在本地,最佳的选择是IndexedDB,容量大,支持异步操作,可以自定义查询。
IndexedDB 是WEB离线存储的一种方式,因此存储只是暂时的,还需要设计一个同步机制,将本地存储的日志同步到云端服务器上。为了更好的同步,就需要设计暂存区、归档区,新产生的日志存储在暂存区,已成功同步的日志存储在归档区。有了本地存储,同步的过程批量同步。
后端存储,可以考虑使用leveldb,在性能方面,基本可以碾压了mongodb和sqlite。
LevelDB是google公司开发出来的一款超高性能kv存储引擎,以其惊人的读性能和更加惊人的写性能在轻量级nosql数据库中鹤立鸡群,此开源项目目前是支持处理十亿级别规模Key-Value型数据持久性存储的C++ 程序库。在优秀的表现下对于内存的占用也非常小,大量数据都直接存储在磁盘上,可以理解为以空间换取时间。
第三方平台
上面简单介绍实现异常监控平台的几个关键点,现在就跟大家分享两个可以用于前端异常跟踪的工具Google Analytics 和 Sentry 。
Google Analytics
没错,Google Analytics一般想到的是用于网站流量统计分析。可以借助Google Analytics的事件统计来跟踪异常,下面是简单的方法:
function postEvents(error) {
var category = error.level || "warn",
action = error.action || "",
label = error.message || "";
ga("send", "event", category, action, label);
}
缺点就是无法方便的确定触发异常的环境条件,后续也无法跟踪版本等等。
Sentry
sentry 是一个实时事件日志记录和聚合平台。它专门用于监视错误和提取执行适当的事后操作所需的所有信息, 而无需使用标准用户反馈循环的任何麻烦。
这是一个比较专业的异常监控工具,基本支持所有主流编程语言,这里只是简单介绍一个前端的使用。
首先在页面上加入以下脚本:
<script src="https://cdn.ravenjs.com/3.20.1/raven.min.js" crossorigin="anonymous"></script>
<script type="text/javascript">
try {
if ((typeof Raven) != "undefined"){
Raven.config('https://ffd39f4582184540a7214fb82bb3e888@sentry.io/248888',{
release: 'release_0.0.5',
allowSecretKey: true
}).install()
}
} catch (error) {
}
</script>
然后项目中可以写一个统一的入口:
function ExceptionJs() {
const ravenJs = typeof Raven != "undefined" ? Raven : {};
this.capture = function (error) {
try {
if (!(error instanceof Error)) {
if (typeof error === "object") {
error = JSON.stringify(error);
}
}
if (typeof ravenJs.captureException === "function") {
ravenJs.captureException(error);
}
} catch (e) {
// 这里是确保异常跟踪脚本出错了不至于影响应用程序
}
};
}
在需要的位置加入以下代码:
const exceptionHelper = new ExceptionJs(),
try {
} catch (error) {
exceptionHelper.capture(error);
}
现在来看看收集上来的异常信息:
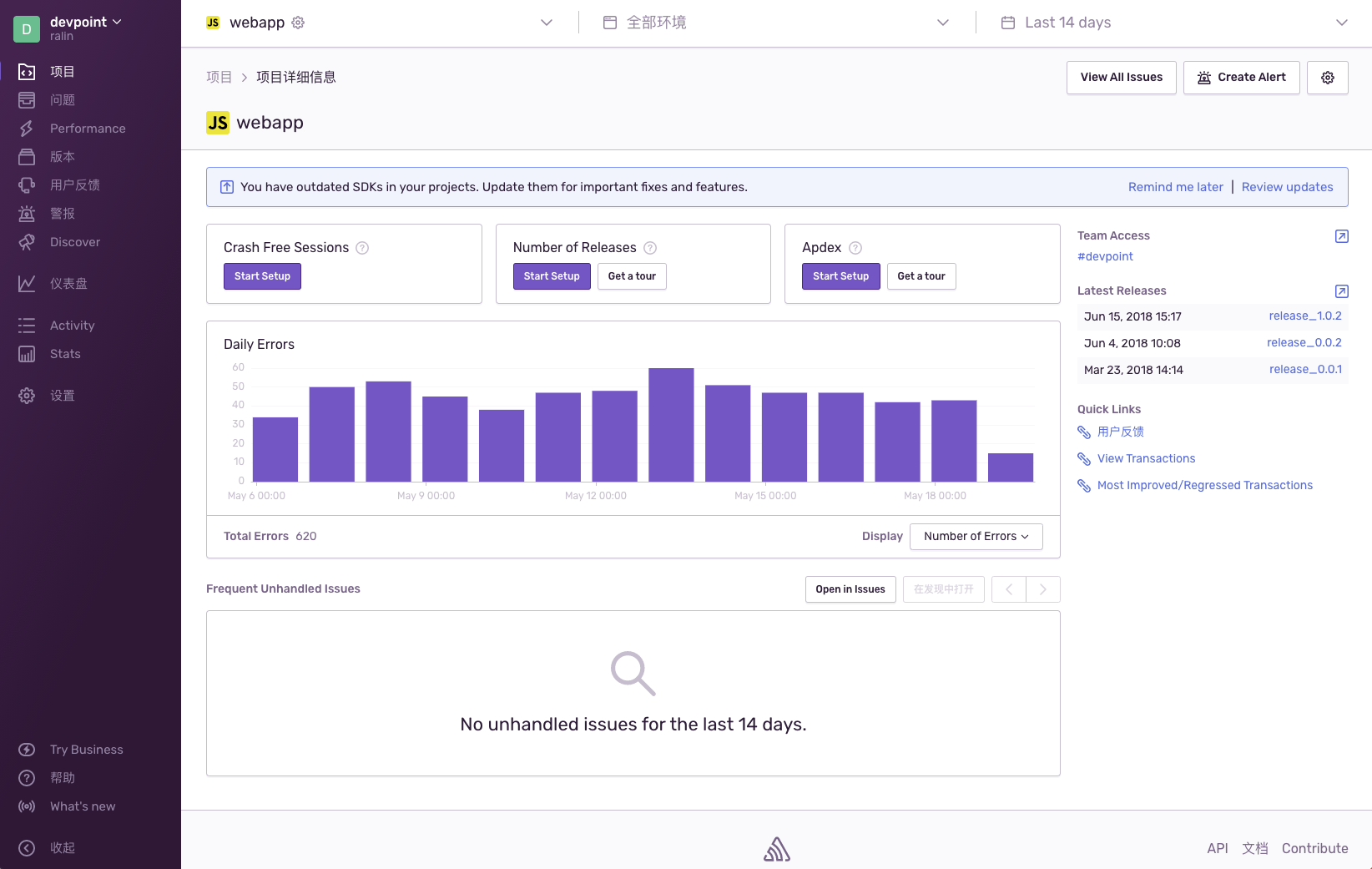
下面这个是异常的统计
![异常统计]()
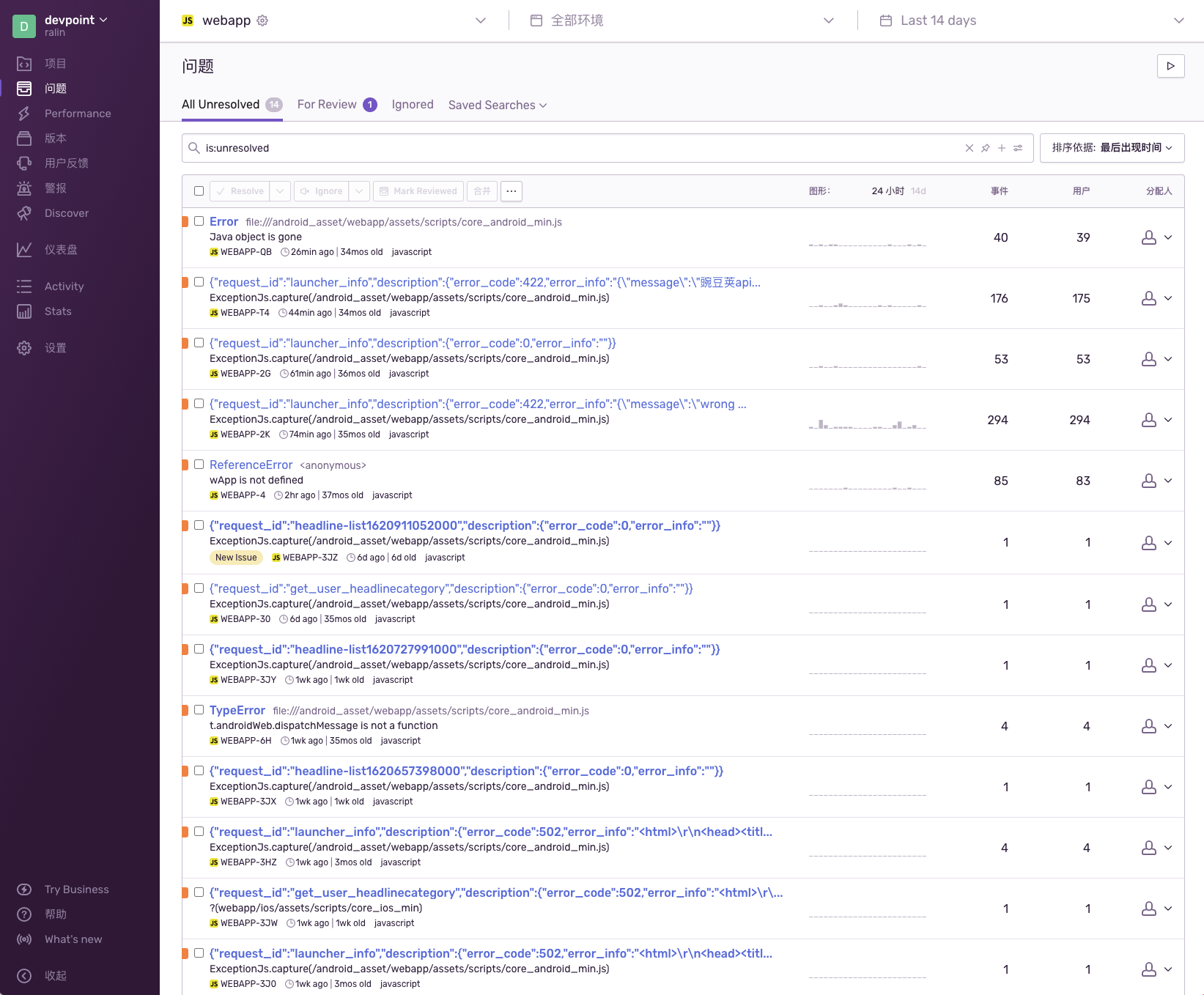
异常列表
![异常列表]()
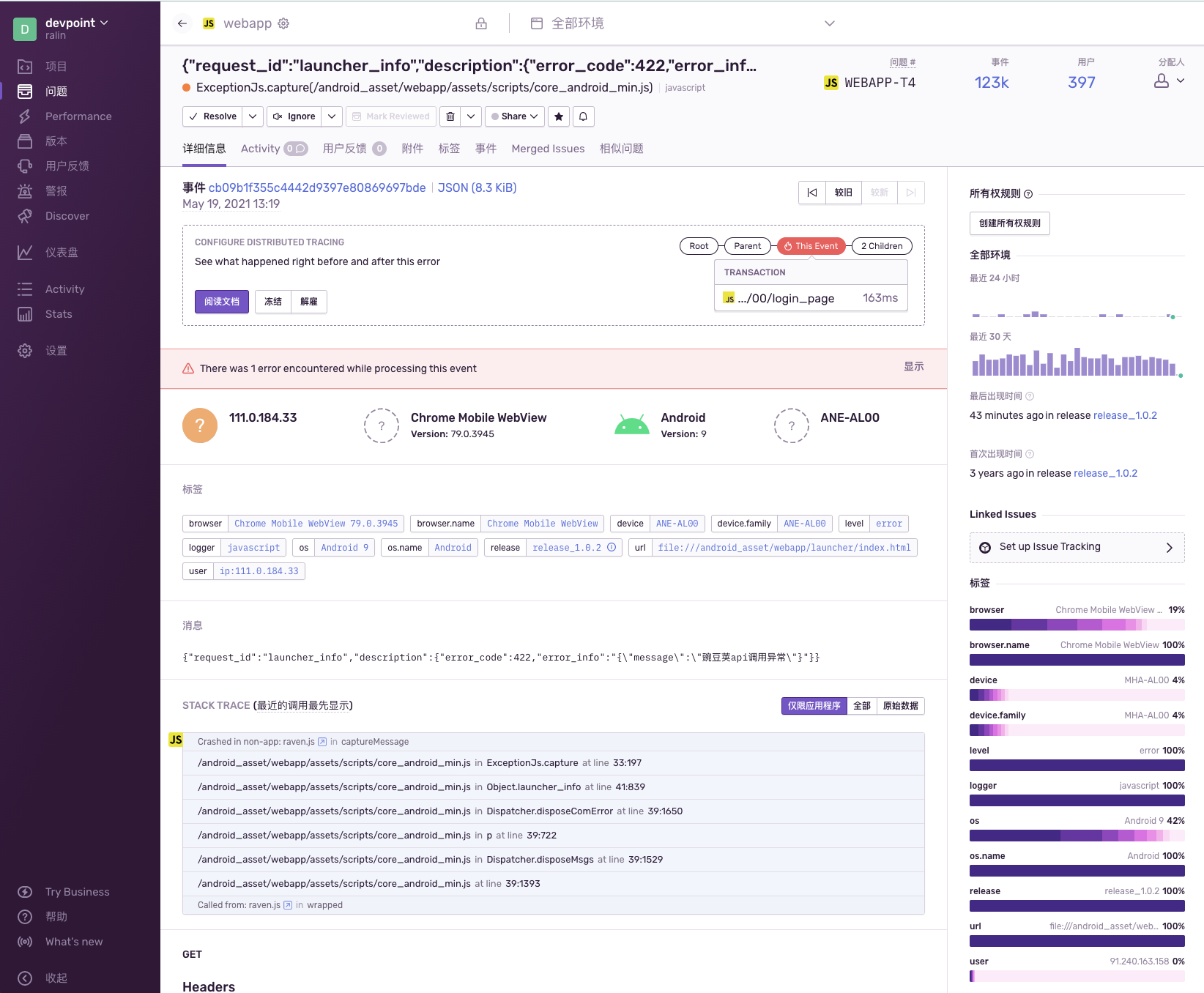
异常详情
![异常详情]()
sentry 工具还提供了异常跟踪处理的功能,有兴趣的小伙伴可以去尝试体验一下。
完