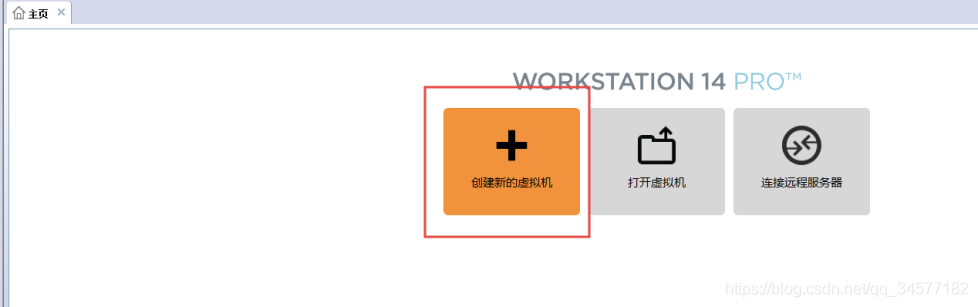
 2:选择自定义安装配置
2:选择自定义安装配置 
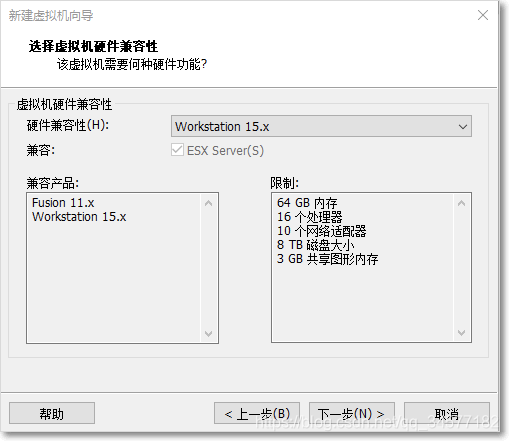 3:选择稍后安装操作系统
3:选择稍后安装操作系统 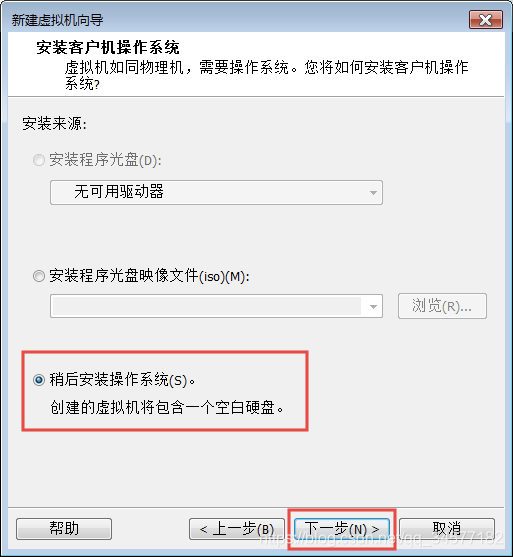
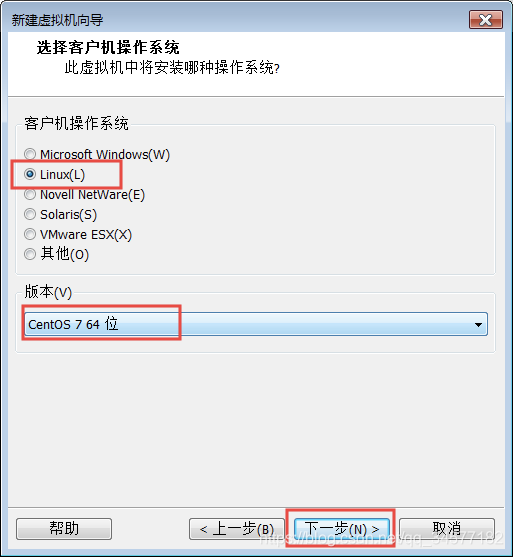 5:选择安装路径,==尽量不要放在C盘,并且所在盘符的剩余空间尽量大些==
5:选择安装路径,==尽量不要放在C盘,并且所在盘符的剩余空间尽量大些== 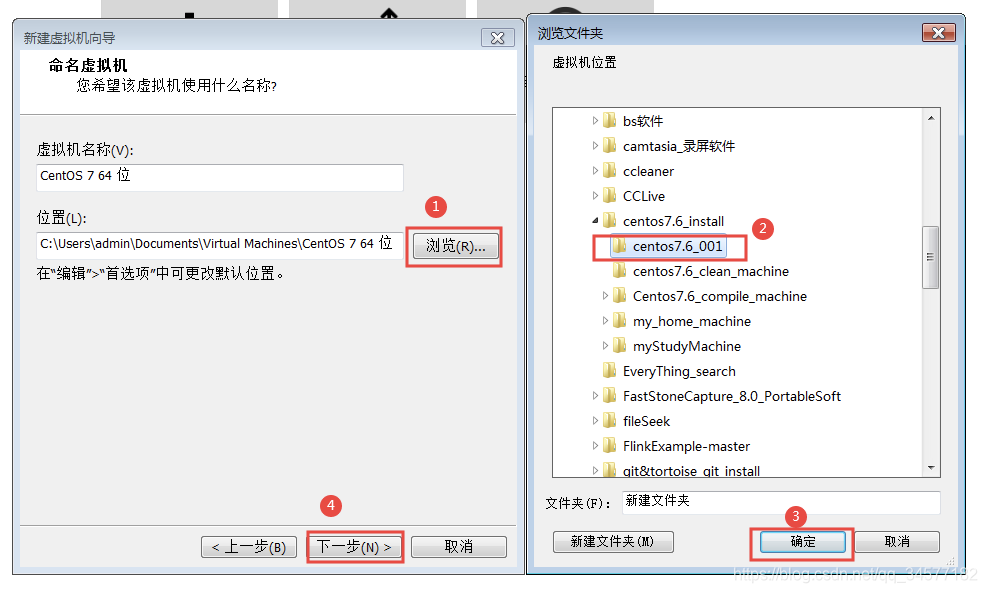 6:CPU核数,默认即可
6:CPU核数,默认即可 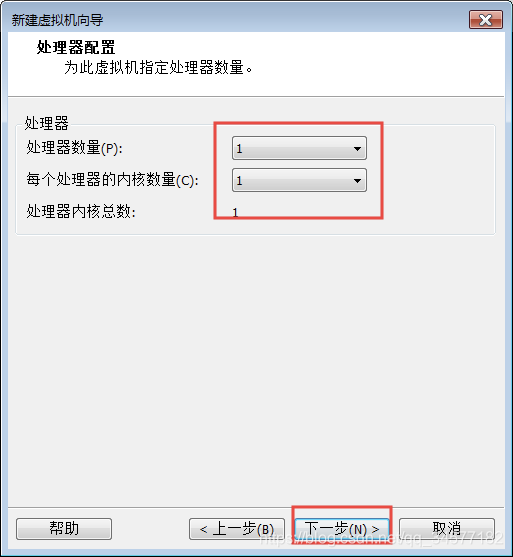 7:虚拟机内存根据自身windows电脑进行调整 例如如果windows是8GB内存,那么每台虚拟机内存给2048M内存,如果windows是16GB内存,那么每台虚拟机可以给4096M内存即可(强烈建议16G,不然后面导大量数据的时候容易挂)
7:虚拟机内存根据自身windows电脑进行调整 例如如果windows是8GB内存,那么每台虚拟机内存给2048M内存,如果windows是16GB内存,那么每台虚拟机可以给4096M内存即可(强烈建议16G,不然后面导大量数据的时候容易挂) 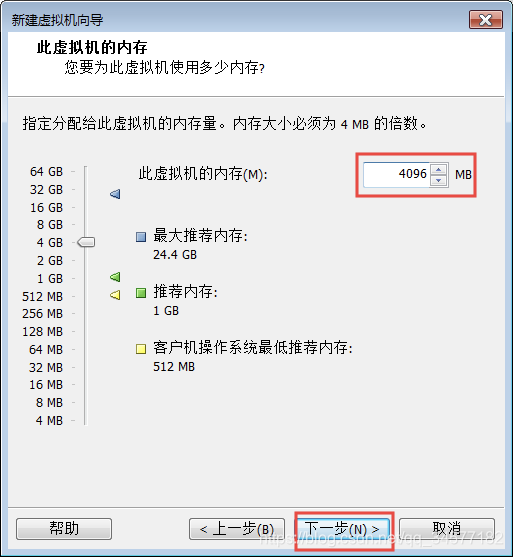 8:网络配置一定要选择==NAT==
8:网络配置一定要选择==NAT== 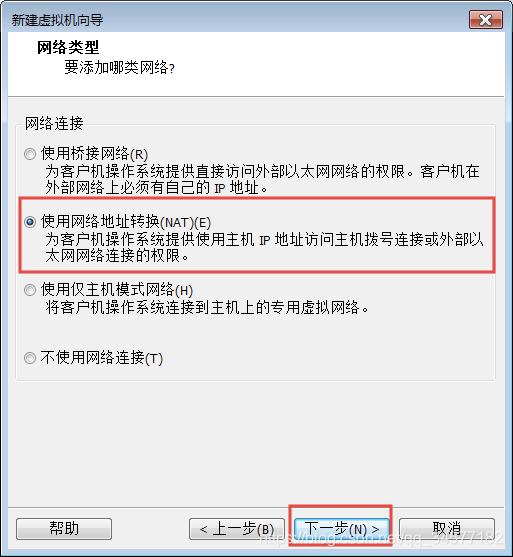
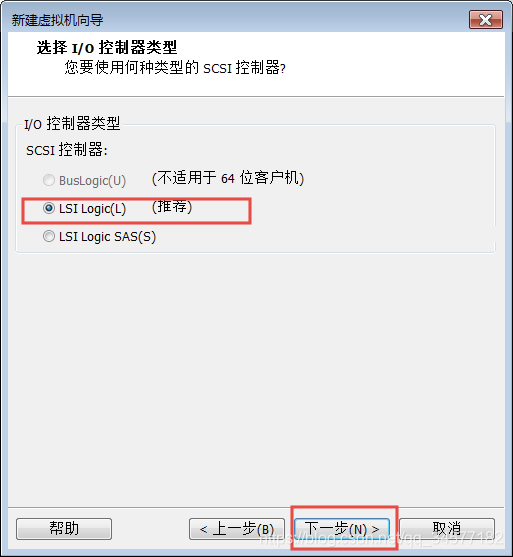
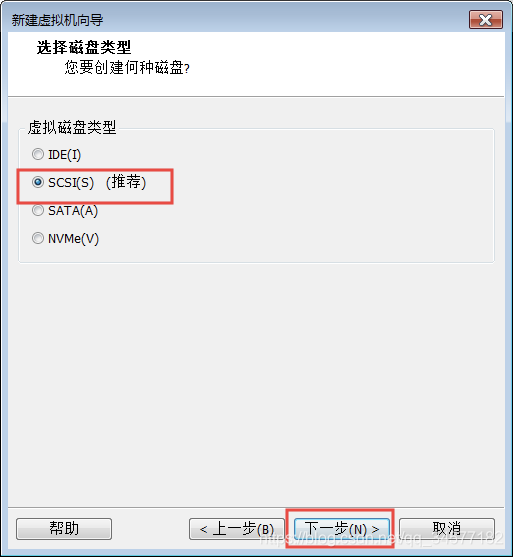 9:磁盘大小尽量给40GB或以上
9:磁盘大小尽量给40GB或以上 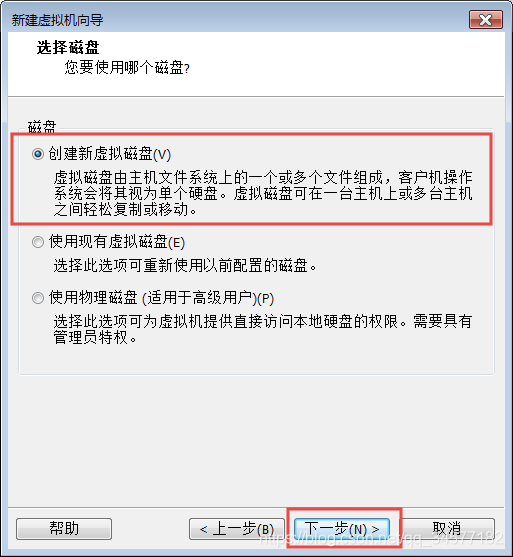 注意:千万==不要==勾选“立即分配所有磁盘空间”
注意:千万==不要==勾选“立即分配所有磁盘空间” 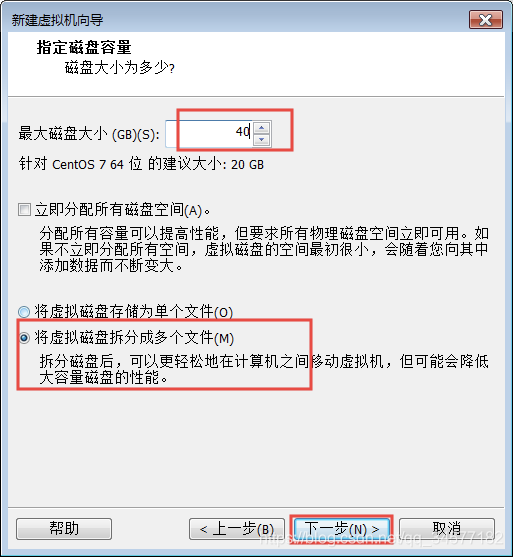
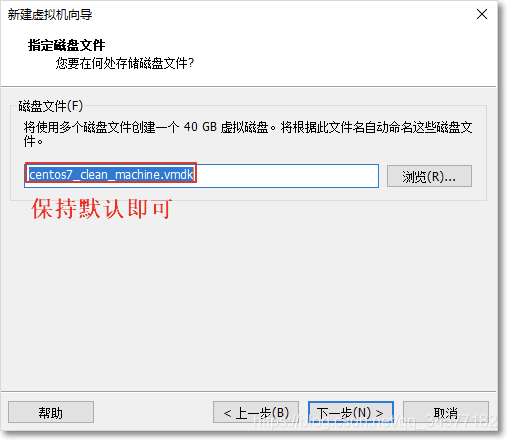 10:完成
10:完成 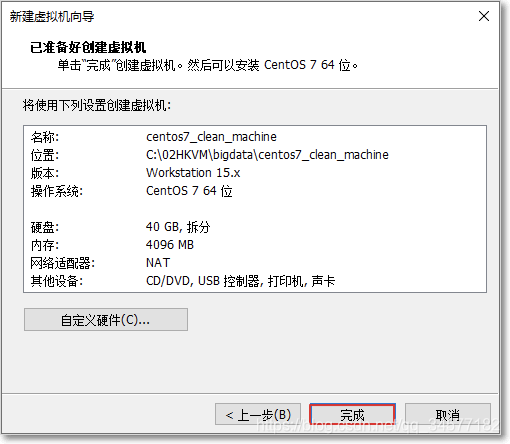
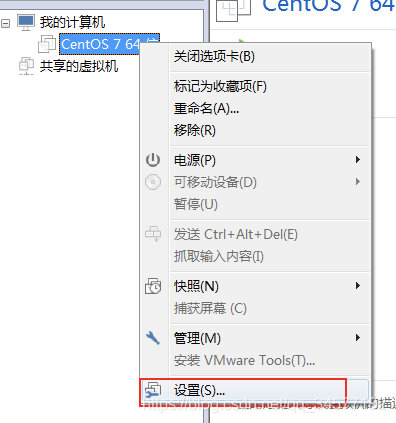 需要自行下载64位Centos7的操作系统
需要自行下载64位Centos7的操作系统 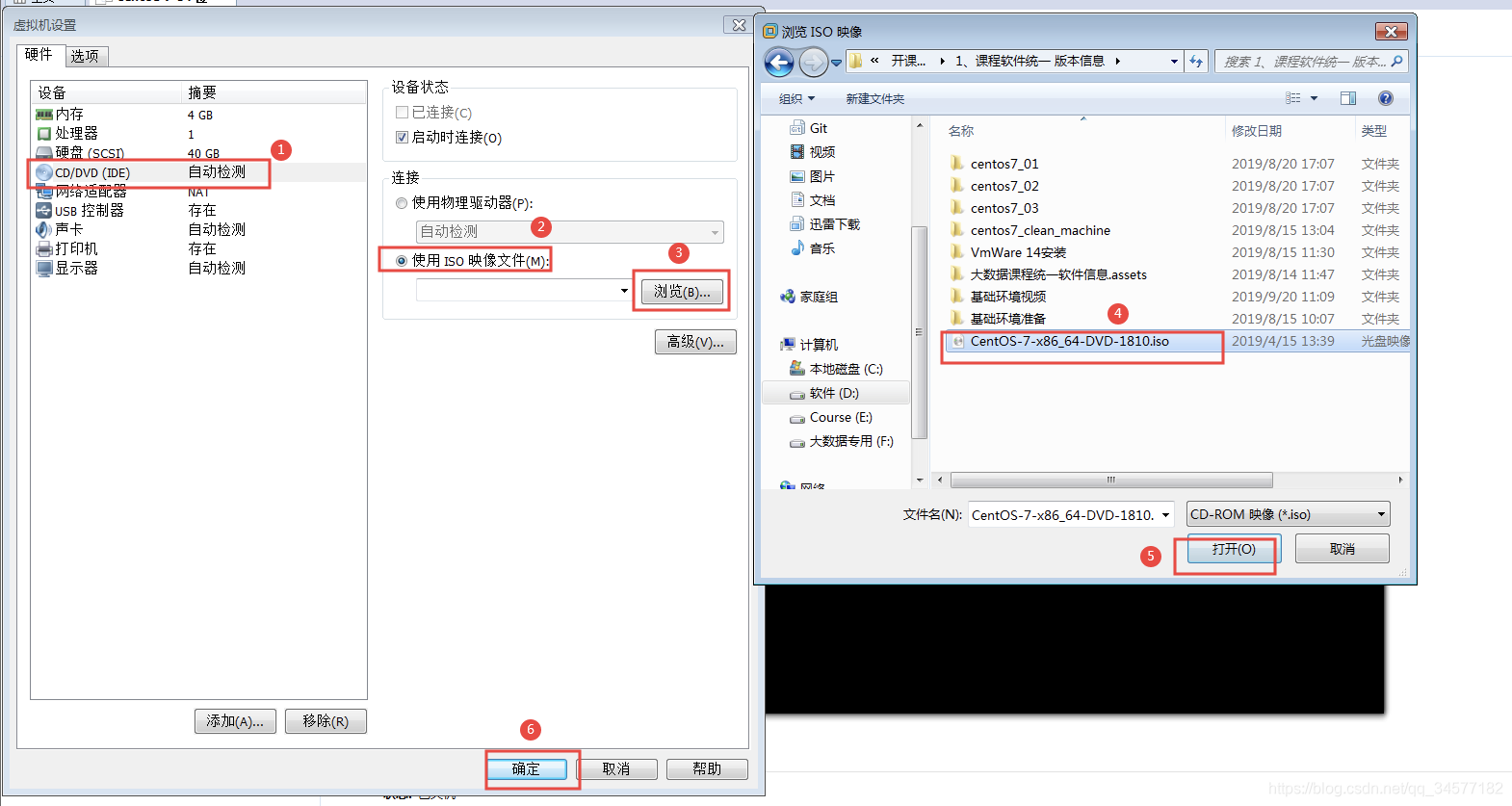
 2:直接回车开始安装
2:直接回车开始安装 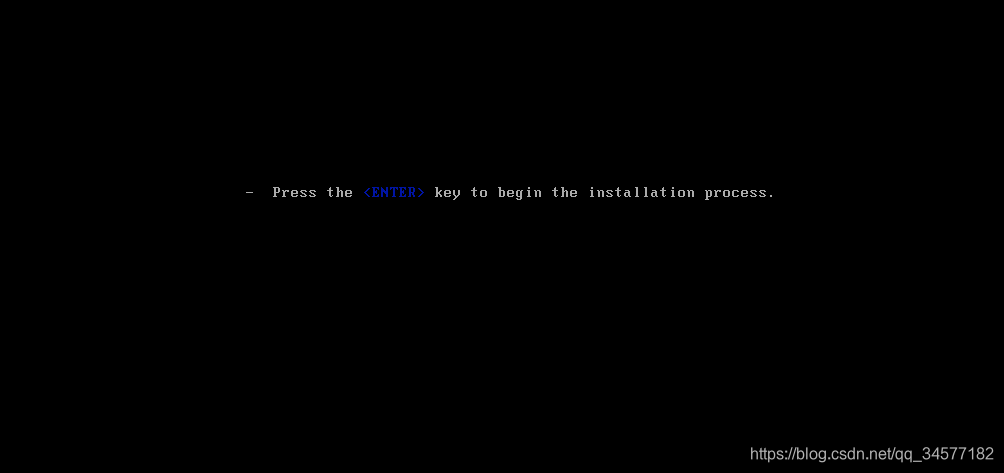 3:设置键盘为英文键盘
3:设置键盘为英文键盘 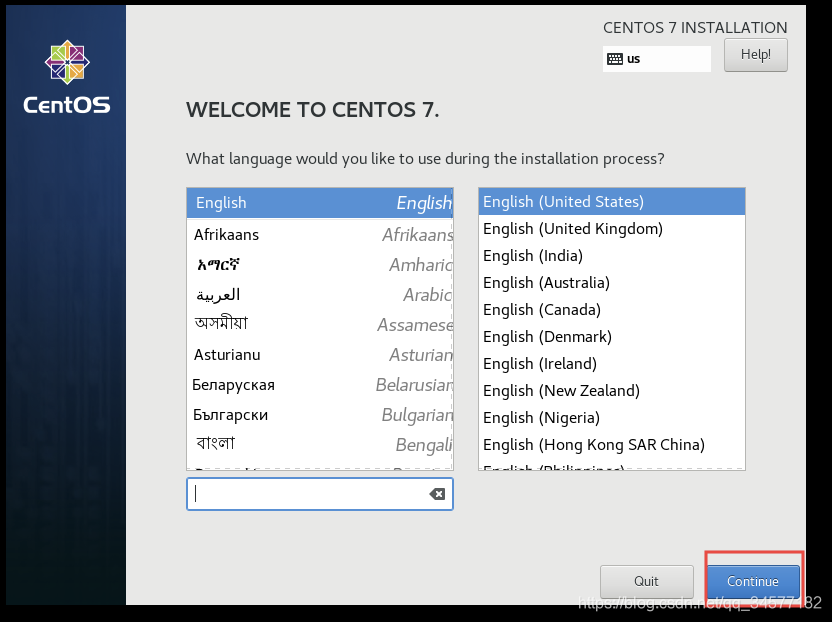 4:接下来配置这三项
4:接下来配置这三项 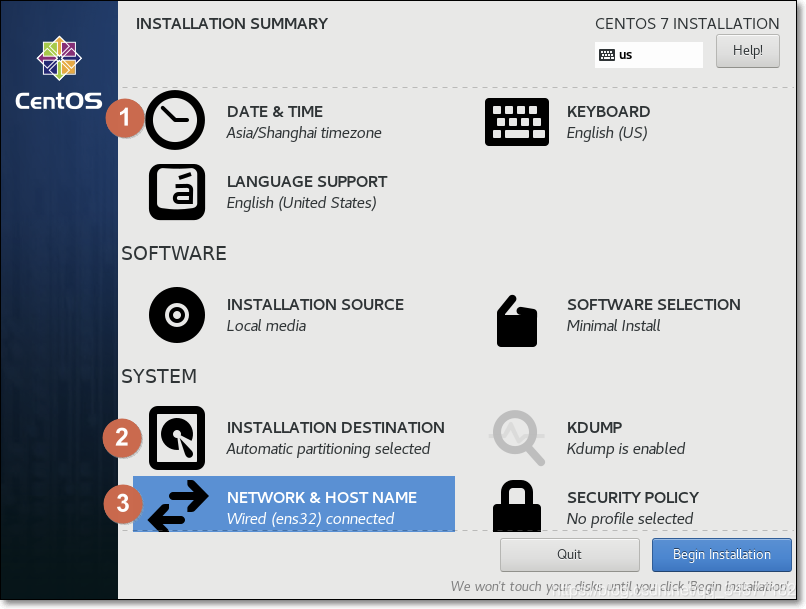 (1)设置①时区为Asia/Shanghai
(1)设置①时区为Asia/Shanghai 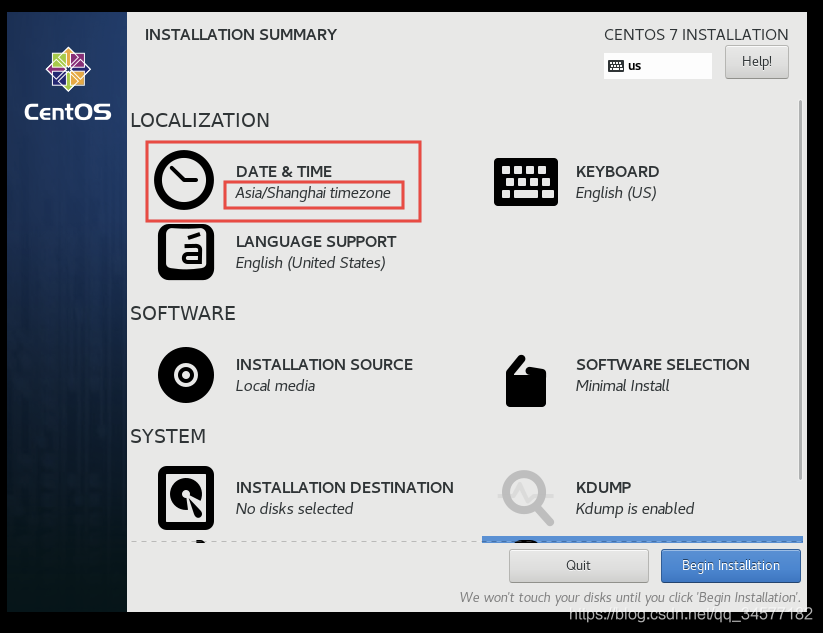 (2)设置②INSTALATION DESTINATION
(2)设置②INSTALATION DESTINATION 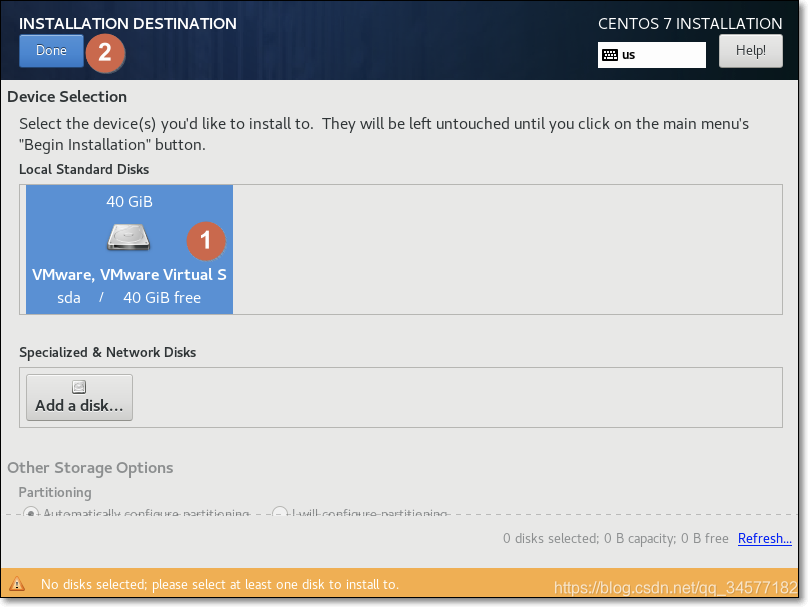 (3)设置③NETWORK & HOST NAME
(3)设置③NETWORK & HOST NAME 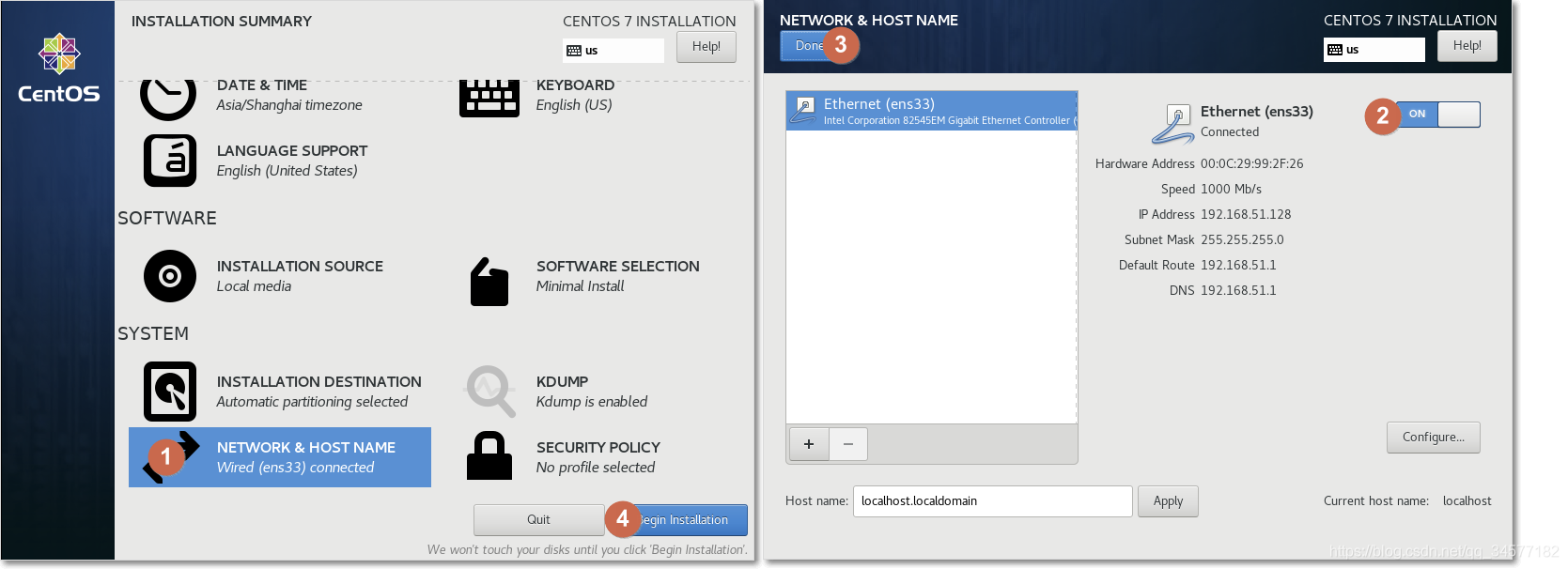 5:设置root用户密码
5:设置root用户密码 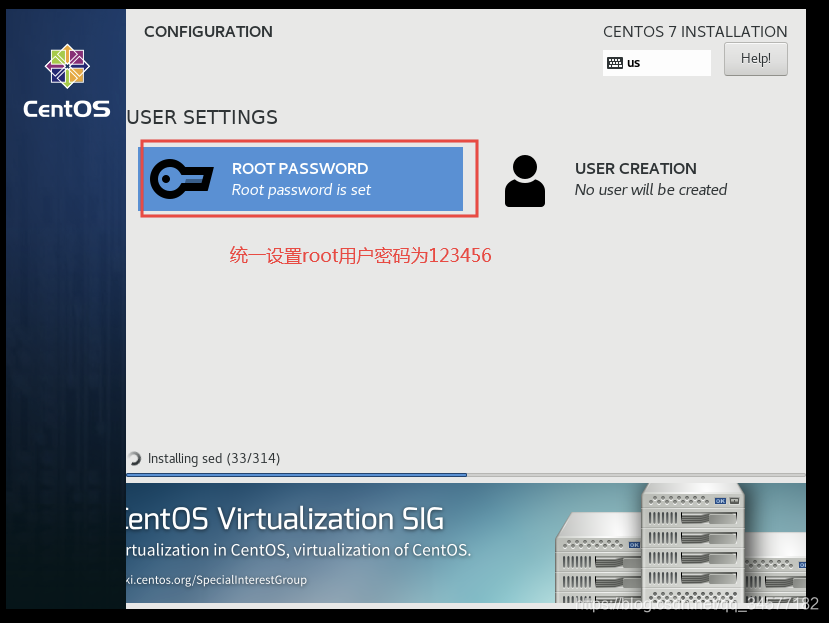 6:安装完成之后重启reboot即可 此过程稍长,耐心等待
6:安装完成之后重启reboot即可 此过程稍长,耐心等待 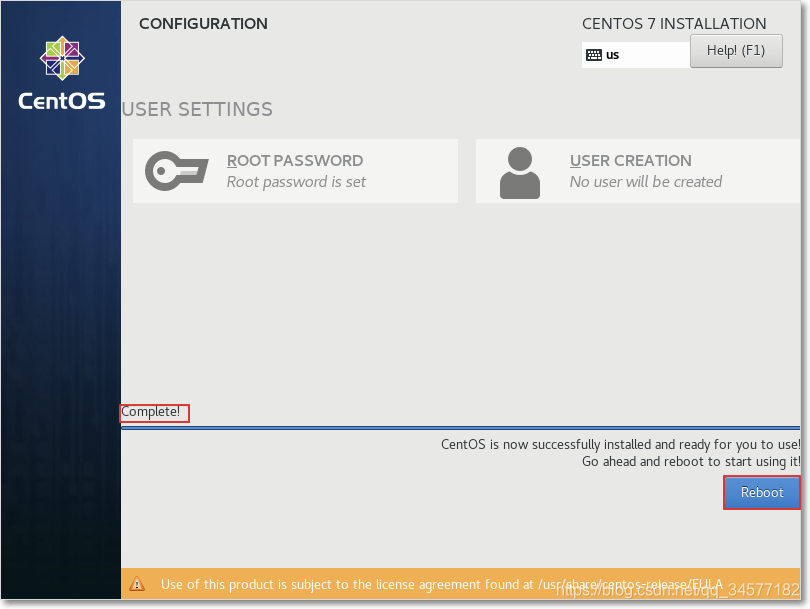
 2:查看==NAT模式==的网关,子网IP以及子网掩码
2:查看==NAT模式==的网关,子网IP以及子网掩码 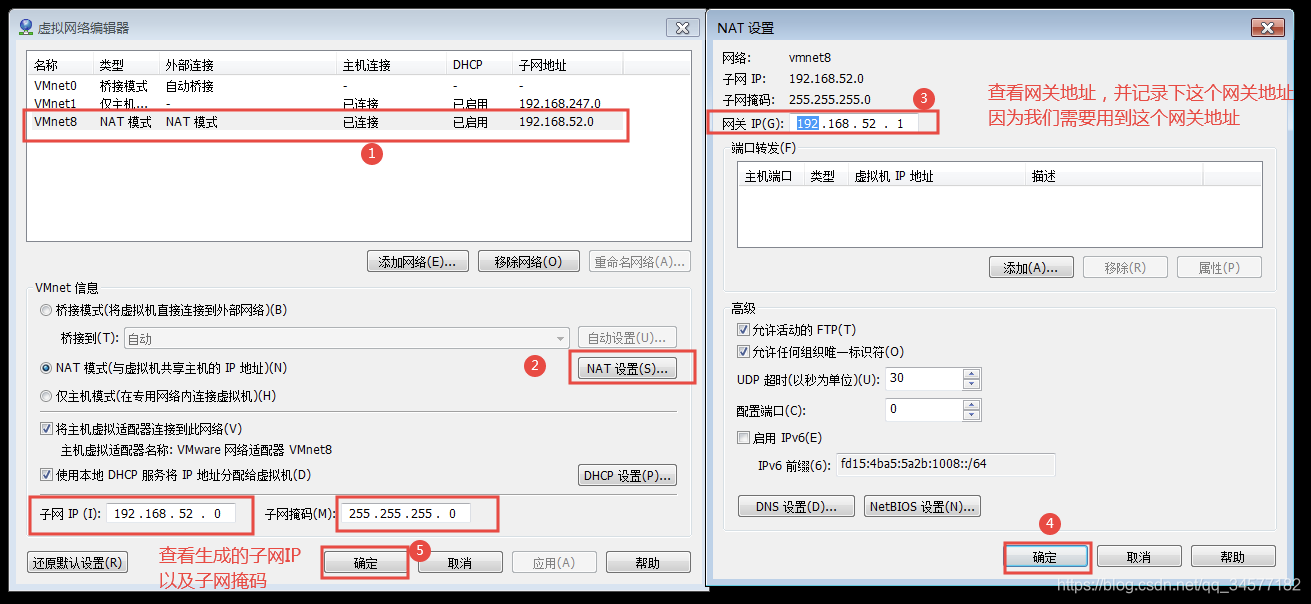 3:设置window当中的VMNet8网络地址
3:设置window当中的VMNet8网络地址 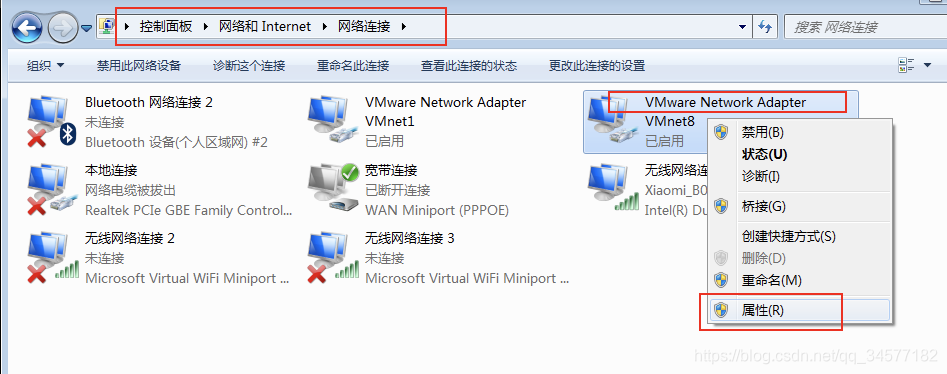
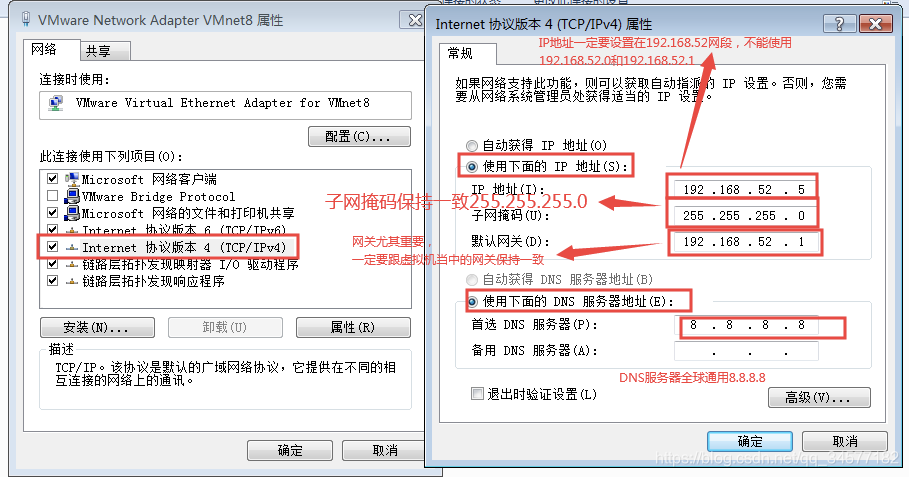 4:设置linux当中的网络
4:设置linux当中的网络 编辑配置文件
编辑配置文件 更改完成配置,重启网络服务
更改完成配置,重启网络服务
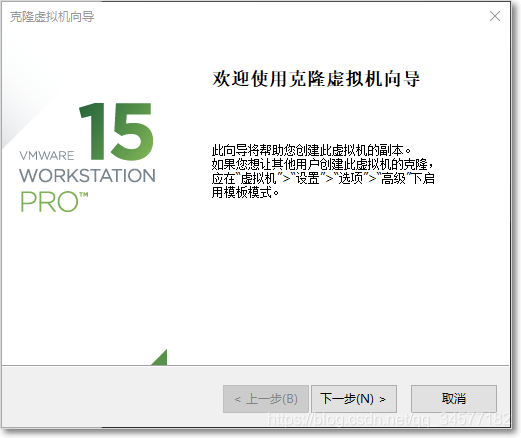
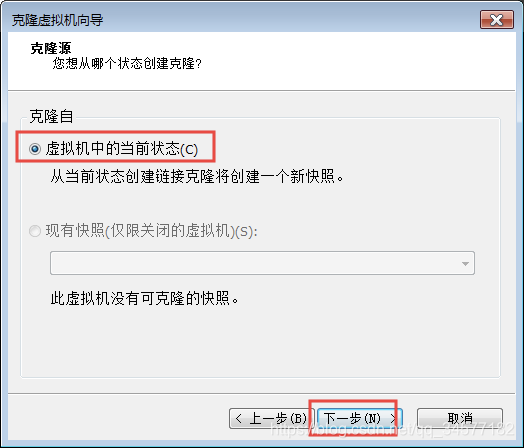 选择创建完整克隆
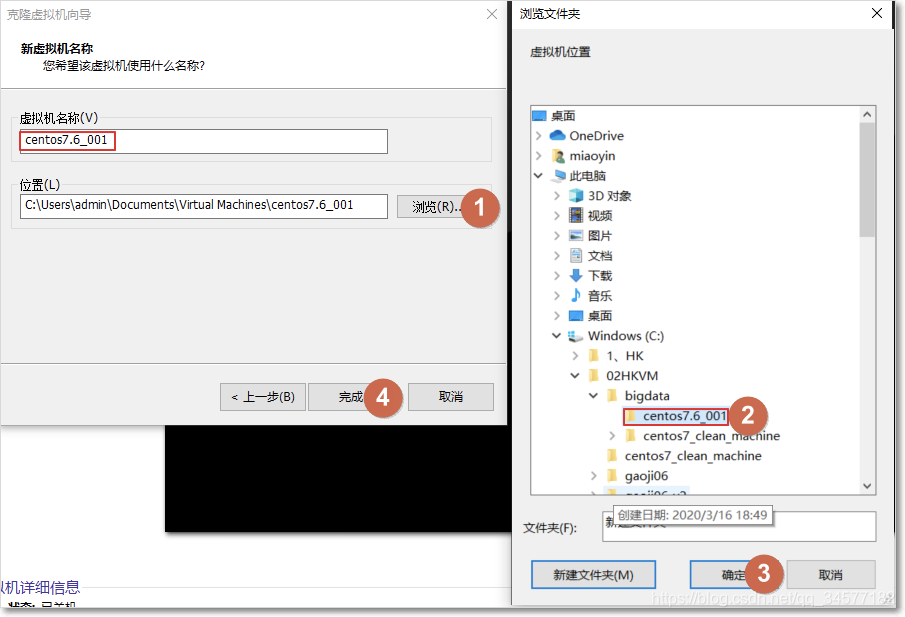
选择创建完整克隆 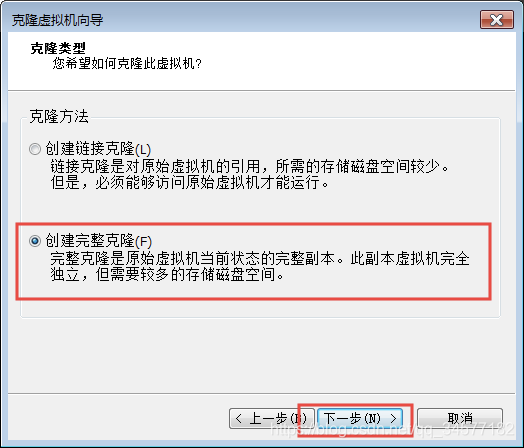


机器学习(五):通俗易懂决策树与随机森林及代码实践
与SVM一样,决策树是通用的机器学习算法。随机森林,顾名思义,将决策树分类器集成到一起就形成了更强大的机器学习算法。它们都是很基础但很强大的机器学习工具,虽然我们现在有更先进的算法工具来训练模型,但决策树与随机森林因其简单灵活依然广受喜爱,建议大家学习。 一、决策树 1.1 什么是决策树 我们可以把决策树想象成IF/ELSE判别式深度嵌套的二叉树形结构。以我们在《机器学习(三):理解逻辑回归及二分类、多分类代码实践》所举的鸢尾花数据集为例。 我们曾用seaborn绘制花瓣长度和宽度特征对应鸢尾花种类的散点图,如下: 当花瓣长度小于2.45则为山鸢尾(setosa),剩下的我们判断花瓣宽度小于1.75则为变色鸢尾(versicolor)剩下的为维吉尼亚鸢尾(virginica)。那么我用导图画一下这种判别式的树形结构如下: 因此,当我们面对任意鸢尾花的样本,我们只需要从根节点到叶子节点遍历决策树,就可以得到鸢尾花的分类结论。 这就是决策树。 1.2 决策树代码实践 我们导入数据集(大家不用在意这个域名),并训练模型: importnumpyasnpimportpandasaspdfrom...