❝
【GiantPandaCV导语】这是一篇ICLR2015的论文,文章针对现有网络设计,探索了「最大池化层是否能被卷积层给完全替代」 。作者在 CIFAR10/100 数据集上设计了一系列对比实验,从而得出可以在不损失精度下,将最大池化层替换成卷积层的结论。
❞
1. 前言 在现有的网络结构设计指导下,似乎卷积层后跟一个池化层下采样,已经是一个准则。我们重新思考了现有SOTA网络,并得出结论最大池化层是能被卷积层给替代。我们设计了一系列小网络,并提出了一种新的「反卷积方法」 来去可视化CNN学习到的特征
2. 模型描述 为了理解池化层和卷积层为什么有效,我们返回到公式里面 我们令 「f为特征图」 ,W, H, N分别是特征图的「宽,高,通道数」 对于一般的池化窗口为K的p范数下采样,我们有「θ代表的是卷积核权重」 , 从1到N求和,「代表是对多个特征图的卷积窗口进行求和」
这里有个细节需要强调下:「池化层是分别对每张特征图做池化/P范数操作」 而卷积层在多通道情况下,「是通过相加各个特征图来进行特征融合」
因此在比较这两个公式后,论文里也说到:「池化层可以看作是一种 特征级别上的卷积,其激活函数为对应的p范数」
分析完上述公式后,作者假定了池化层有效的几个因素
「P范数形式能增加CNN的平移不变性」 ,这里存疑我后续会解释
池化层的下采样,能为后续的卷积操作 「提供更大的感受野」
池化层仅仅是在特征图上操作,不会带来额外的参数, 「因此有助于整个网络优化过程」
我们假设第二点是提升CNN性能的关键。我们有以下两个选择来替代池化层
去除掉池化层,将卷积层的步长变为2。这种方法参数量与此前一致
用步长为2的池化层,来替代池化层。由于引入新的卷积层,参数量会适当增加
考虑到3x3卷积叠加能达到5x5卷积的感受野,减少大量参数,我们也将其加入到实验对比。因此我们的网络设计如下
P范数定义如下「某个范围内x的P次方和」 ,最后「再开P次方」
那「如果是平均池化」 ,我们可以看作是P=1的范数下采样,前面需要乘上一个系数 「K分之一」
具体可以参考下 「证伪:CNN中的图片平移不变性」 (https://zhuanlan.zhihu.com/p/38024868)
简单来说,我们下采样因子是固定的,常用的我们都是步长为2的操作,来进行叠加,缩小特征图分辨率
举个例子,1张224x224的图片,经过多次下采样至 7x7,那么整个采样因子就是 32x32。为了保证平移不变性,我需要让物体平移距离是32的整数倍。
换句话说,我相当于将整个图片划分成了32x32个小格子,物体需要落到这个格子里,才能具有不变性。这个概率是
3. 实验 我们在CIFAR10, CIFAR100, ImageNet2012数据集上进行测试
3.1 实验设置 我们在先前的Model C上,又引申出三种模型
第一个模型,将每一层最后一个卷积层步长设置为2,去除掉了池化层
第二个模型,为了与第三个模型做对比,在保持相同卷积层时,用最大池化层下采样 因为原始的ModelC,已经包含了两次卷积层+一次池化层的结构。所以针对第一个模型就不再多设置一个模型对比
3.2 实验结果
再B,C两组中, ALL-CNN都得到了最好的效果。而在A组,池化的效果比Strided的效果更好。「为了保证不是因为参数量增加而引起的,我们也对比了ALL-CNN-A」 。事实证明池化操作是能提高网络性能的
后续,我们针对训练过程是否加入图像增广也做了一组实验
4. 笔者理解 在现代的网络设计中,池化层出现的越来越少了。早在几年前,这个问题还是很令人深思的。郑安坤大佬也做过一系列实验「CNN真的需要下采样吗」 (https://zhuanlan.zhihu.com/p/94477174),并且后面也探讨了maxpooling。
我也是比较同意文中的观点,因为无论是均值池化层还是最大池化层,都可以对应传统图像处理的一个人为设计的滤波器。如果没有下采样操作,它完全是可以做一个抑制图像噪声的操作在。并且池化层是与多通道之间没有关系的,只是在单一特征图上做。
我会认为在浅层特征图中,空间相关特征比较明显,可以使用池化层。在高维特征图上,特征经过编码后,空间相关不太明显,这时候用卷积层做下采样会比较好。
而且还是需要具体任务具体分析,比如在CVPR2020的Small Big Net
在时间维度上对视频帧应用最大池化来提取特征信息,因此我还是认为池化操作是有其必要性的。
为了感谢读者朋友们的长期支持,我们今天将送出3本由机械工业出版社提供的《机器学习算法框架实战》书籍,对本书感兴趣的可以在留言版留言,我们将抽取其中三位读者送出一本正版书籍。
留言板
没中奖的读者如果对这本书有需求的可以考虑点击下面的当当网链接进行购买。
有需要加入交流群的读者可以添加下方的微信
或者加入公众号的QQ交流群和大佬交流算法问题
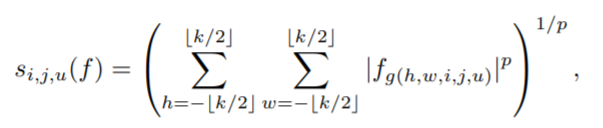 而对于一般的卷积层,我们需要设定一个权重,进行相乘,并将多个通道结果进行相加。最后再通过激活函数进行激活,形式如下
而对于一般的卷积层,我们需要设定一个权重,进行相乘,并将多个通道结果进行相加。最后再通过激活函数进行激活,形式如下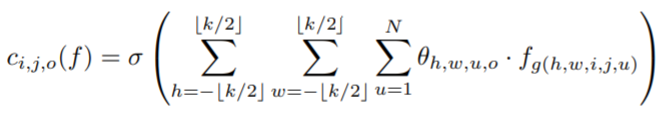 「θ代表的是卷积核权重」, 从1到N求和,「代表是对多个特征图的卷积窗口进行求和」
「θ代表的是卷积核权重」, 从1到N求和,「代表是对多个特征图的卷积窗口进行求和」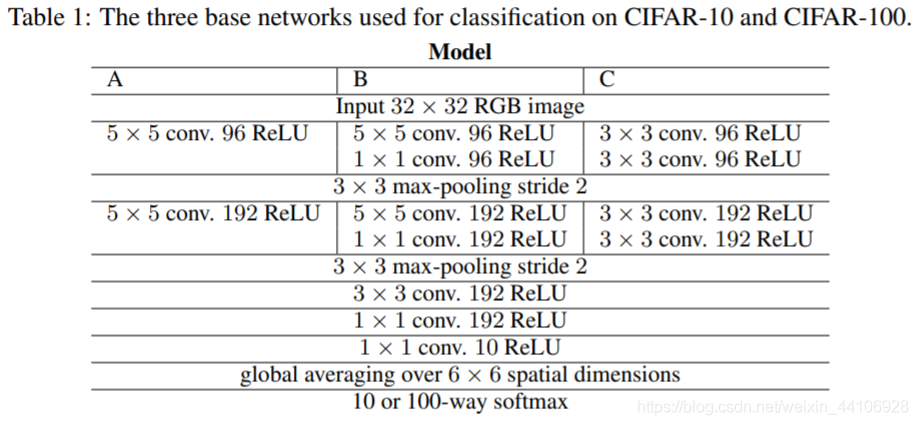
 即求「某个范围内x的P次方和」,最后「再开P次方」
即求「某个范围内x的P次方和」,最后「再开P次方」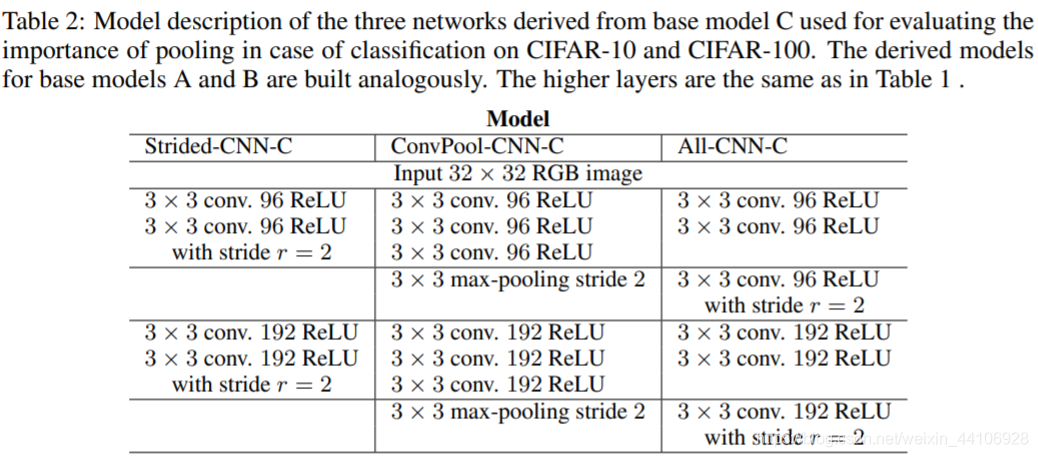
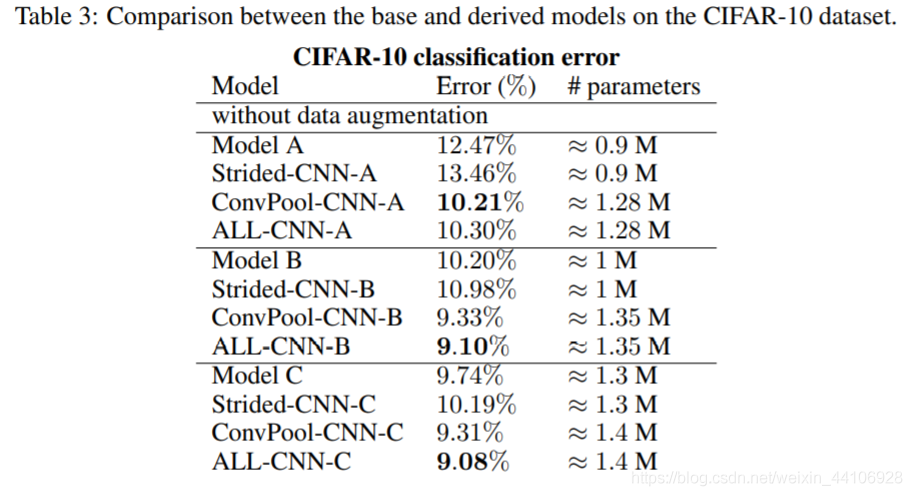 首先我们来看下Model A,B,C 最主要的区别就是拿3x3卷积来替代大卷积核和部分1x1卷积。事实证明使用3x3卷积替代大卷积核,能得到性能上的提升
首先我们来看下Model A,B,C 最主要的区别就是拿3x3卷积来替代大卷积核和部分1x1卷积。事实证明使用3x3卷积替代大卷积核,能得到性能上的提升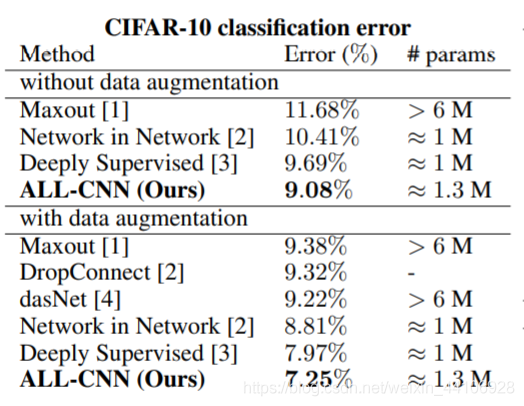 在这两种情况下,网络表现的都比前面的要好很多 我们将这个最佳模型,放到CIFAR100进一步进行测试
在这两种情况下,网络表现的都比前面的要好很多 我们将这个最佳模型,放到CIFAR100进一步进行测试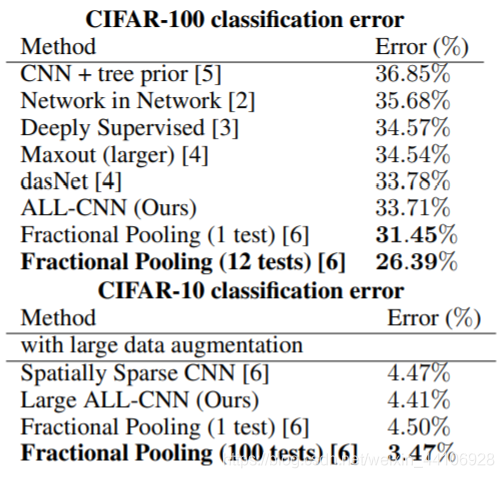 可以看到我们的效果依然很好,超越了前面的网络模型。仅仅被Fractional Pooling超过,但这个模型参数过大,大概50M左右的参数。所以我们的模型表现是十分不错的。
可以看到我们的效果依然很好,超越了前面的网络模型。仅仅被Fractional Pooling超过,但这个模型参数过大,大概50M左右的参数。所以我们的模型表现是十分不错的。


