我们设计数据表的时候,一般都会有ID字段,ID的生成方法有多种,比如数据库自增,UUID,雪花算法等。
考虑到以后数据的增长,分库分表,分布式等要求,我们选择雪花算法来生成ID。
开发Web系统需要后端跟前端交互,前端JavaScript支持的最大整型是53位,超过53位会丢失精度,原版的雪花算法会超过53位,我们使用缩小版的雪花算法,把位数减小到53位。
原版Snowflake算法的极限是每毫秒的每一个节点生成4059个id值,也就是说每毫秒的极限是生成023*4059=4 152 357个id值 ,缩小后极限是每秒生成15*131071=1 966 065个分布式id,够我们在开发里面的日常使用了。
package cn.gintone.asso.util;
/**
* @description:缩小版的雪花算法
* @author:Elon He
* @create:2020-10-06
*/
public class SnowflakeMini {
/**
* 开始时间截 (1970-01-01)
*/
private final static long twepoch = 0L;
/**
* 机器id,范围是1到15
*/
private final static long workerId =1L;
/**
* 机器id所占的位数,占4位
*/
private final static long workerIdBits = 4L;
/**
* 支持的最大机器id,结果是15
*/
private final static long maxWorkerId = ~(-1L << workerIdBits);
/**
* 生成序列占的位数
*/
private final static long sequenceBits = 15L;
/**
* 机器ID向左移15位
*/
private final static long workerIdShift = sequenceBits;
/**
* 生成序列的掩码,这里为最大是32767 (1111111111111=32767)
*/
private final static long sequenceMask = ~(-1L << sequenceBits);
/**
* 时间截向左移19位(4+15)
*/
private final static long timestampLeftShift = 19L;
/**
* 秒内序列(0~32767)
*/
private static long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private static long lastTimestamp = -1L;
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public static synchronized long nextId() {
//返回以秒为单位的当前时间
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//蓝色代码注释结束
//红色代码注释开始
//如果是同一时间生成的,则进行秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//秒内序列溢出
if (sequence == 0) {
//阻塞到下一个秒,获得新的秒值
timestamp = tilNextMillis(lastTimestamp);
}
//时间戳改变,秒内序列重置
}
//红色代码注释结束
//绿色代码注释开始
else {
sequence = 0L;
}
//绿色代码注释结束
//上次生成ID的时间截
lastTimestamp = timestamp;
//黄色代码注释开始
//移位并通过或运算拼到一起组成53 位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (workerId << workerIdShift)
| sequence;
//黄色代码注释结束
}
/**
* 阻塞到下一个秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected static long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以秒为单位的当前时间
*
* @return 当前时间(秒)
*/
protected static long timeGen() {
return System.currentTimeMillis()/1000L;
}
}
创建两个线程,同时测试ID获取。
测试线程类A
package cn.gintone.asso;
import cn.gintone.asso.util.SnowflakeMini;
/**
* @description:线程A
* @author:Elon He
* @create:2020-10-06
*/
public class ThreadA extends Thread{
@Override
public void run() {
super.run();
for (int i = 0; i < 10; i++) {
long id = SnowflakeMini.nextId();
System.out.println("A:"+id);
}
}
}
测试线程类B
package cn.gintone.asso;
import cn.gintone.asso.util.SnowflakeMini;
/**
* @description:线程B
* @author:Elon He
* @create:2020-10-06
*/
public class ThreadB extends Thread{
@Override
public void run() {
super.run();
for (int i = 0; i < 10; i++) {
long id = SnowflakeMini.nextId();
System.out.println("B:"+id);
}
}
}
测试类(注释掉的代码是修改成静态方法前的测试方法)
package cn.gintone.asso;
/**
* @description:雪花算法测试类
* @author:Elon He
* @create:2020-10-06
*/
public class TestSnowflake {
public static void main(String[] args) {
//不同线程使用同一个对象,不重复
// SnowflakeMini idWorker = new SnowflakeMini(0);
// ThreadA t1 = new ThreadA(idWorker);
// ThreadB t2 = new ThreadB(idWorker);
// t1.start();
// t2.start();
//不同线程使用不同对象,会重复
// SnowflakeMini idWorker1 = new SnowflakeMini(0);
// SnowflakeMini idWorker2 = new SnowflakeMini(0);
// ThreadA t1 = new ThreadA(idWorker1);
// ThreadB t2 = new ThreadB(idWorker2);
// t1.start();
// t2.start();
//nextId修改成静态方法后测试,不重复
ThreadA t1 = new ThreadA();
ThreadB t2 = new ThreadB();
t1.start();
t2.start();
}
}
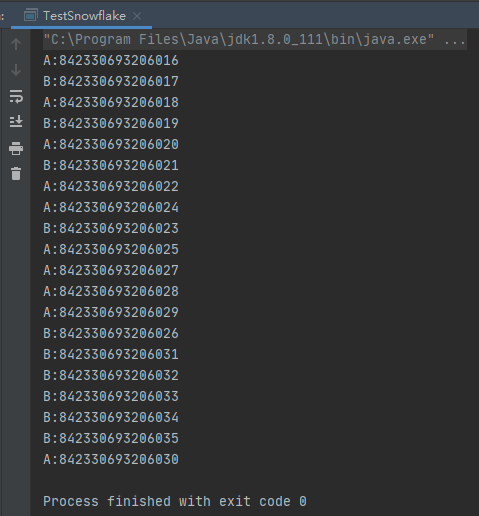
测试结果
![]()