![]()
一文带你爬取传统古诗词(超级简单!)
目录
一、小小课堂
二、网页分析
2.7.1 拼接URL
2.7.2 内容解析
1. xpath解析
2. 代码实现
3. 运行结果
2.1 确定要爬取的内容对应的url
2.2 分析抓取的主要内容
2.3 获取所有的一级类型(错误版本)
2.4 获取所有的一级类型(修改版本)
2.5 获取二级标题
2.6 获取二级类型下诗词的名称和url
2.7 查询数据
三、完整代码
四、保存结果
一、小小课堂
![]()
中国文学源远流长,早在远古时代,虽然文字还没有产生,但在人民中间已经流传着神话传说和民间歌谣等口头文学。随着时间线的推移,先后出现了:诗经(西周)——楚辞(战国)——乐府(汉)——赋(晋)——唐诗——宋词——元曲——明清小说。
现在一提,不知各位想到的是什么。但是本人首先想到的诗歌是《阿房宫赋》、《水调歌头·明月几时有》、《念奴娇·赤壁怀古》、《茅屋为秋风所破歌》等等。可能是因为这些个别的诗歌贼长,在高中时期折磨过我的原因吧-。-
现在有一个新的职业——网络文学作家,他们写小说发布在网上,通过其有趣的故事情节及其丰富的主分线并行等特点吸引大批作者,从而达到挣钱的目的。但是,不知你知道与否,早在我国古代的明清时期,白话小说就已经蓬勃发展了。在那是,出现了“章回体小说”。一提到“章回体小说”,我们就不得不提到四大名著。名著之所以能够成为名著,是与其特点分不开的。它们的特点是分回标目,常取一个或两个中心事件为一回,每回篇幅大致相等,情节前后衔接,开头、结尾常用“话说”“且听下回分解”等口头语,中间穿插诗词韵文,结尾故设悬念吸引读者。除了四大名著之外,还有博主最喜欢的两本书:《儒林外史》、《聊斋志异》。哈哈,博主在此声明,我不是推销小说的啊。只是单纯的有感而发而已。如果各位想要看看博主推荐的书的话,也是可以的。总之你看了也没有任何坏处。
我国古典文学如此之多,在整个世界上也是实属罕见的。那么,作为新世纪国家的创造者,我们因该的做的就是传承好古典文学。古为今用,弘扬社会主义价值观,好让中国文学能够继续更好的继承下去。
现在因该会有读者会说,改进入正题了。🆗,从现在开始进入正题。
上面说了那么多,虽然看似与本文无关,但是其实是有关系的。想象一下,既然我们要更多的品味古典文学,我们是不是要专门的查看借鉴。但是又由于现在我们的时间都是零碎化的时间快,单独看书又不太现实。现如今网络如此之发达,我们每个人基本上都已经离不开电脑、手机了。那么我们可不可以通过Python爬虫的方式,把这些内容全不爬取出来,然后通过电子设备进行阅读呢?
![]()
下面就开始实现此设想。
二、网页分析
从理想到现实的第一步,当然是先找到网站了。
古诗文网:https://www.gushiwen.org/
我们打开网址之后,发现网页如下:
![]()
2.1 确定要爬取的内容对应的url
我们先查看网页的结构
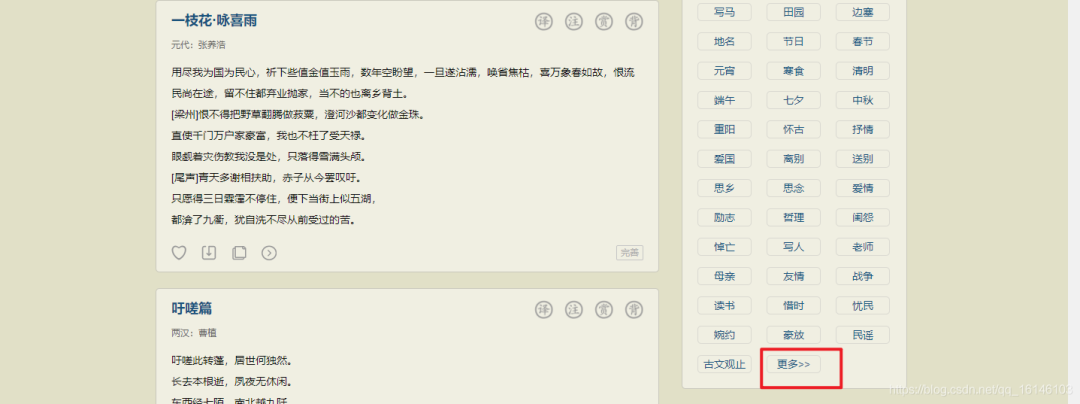
1. 先点击更多 查看多有的类型
![]()
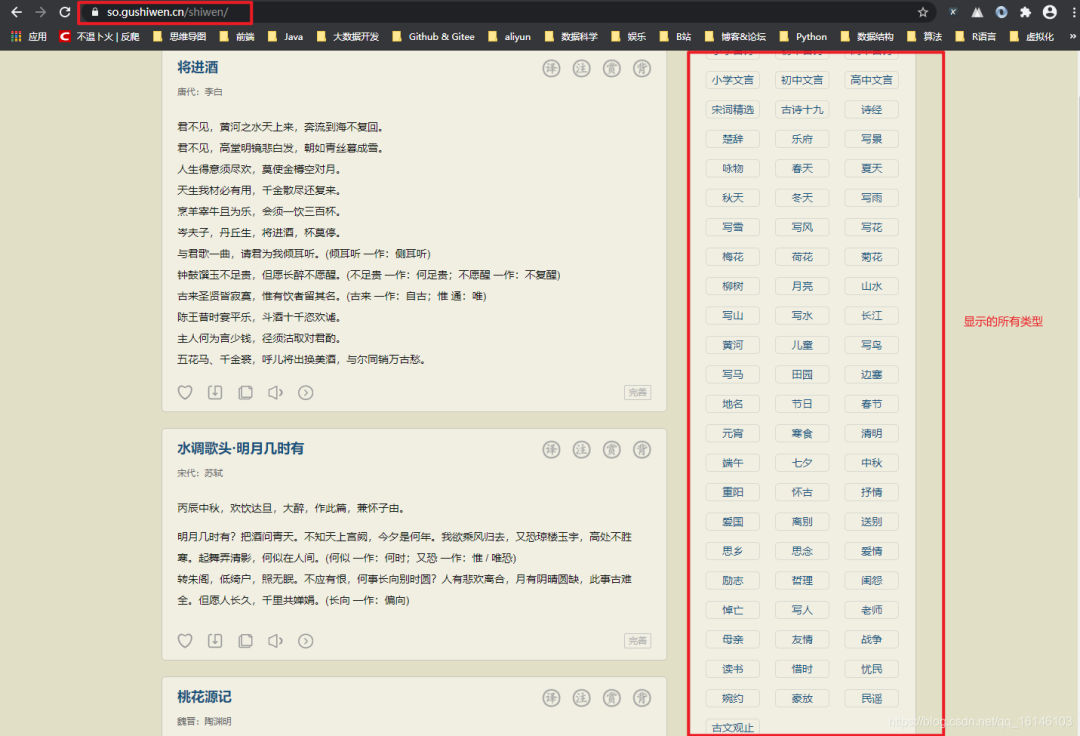
2. 我们可以看到下图已经把所有的类型显示出来
![]()
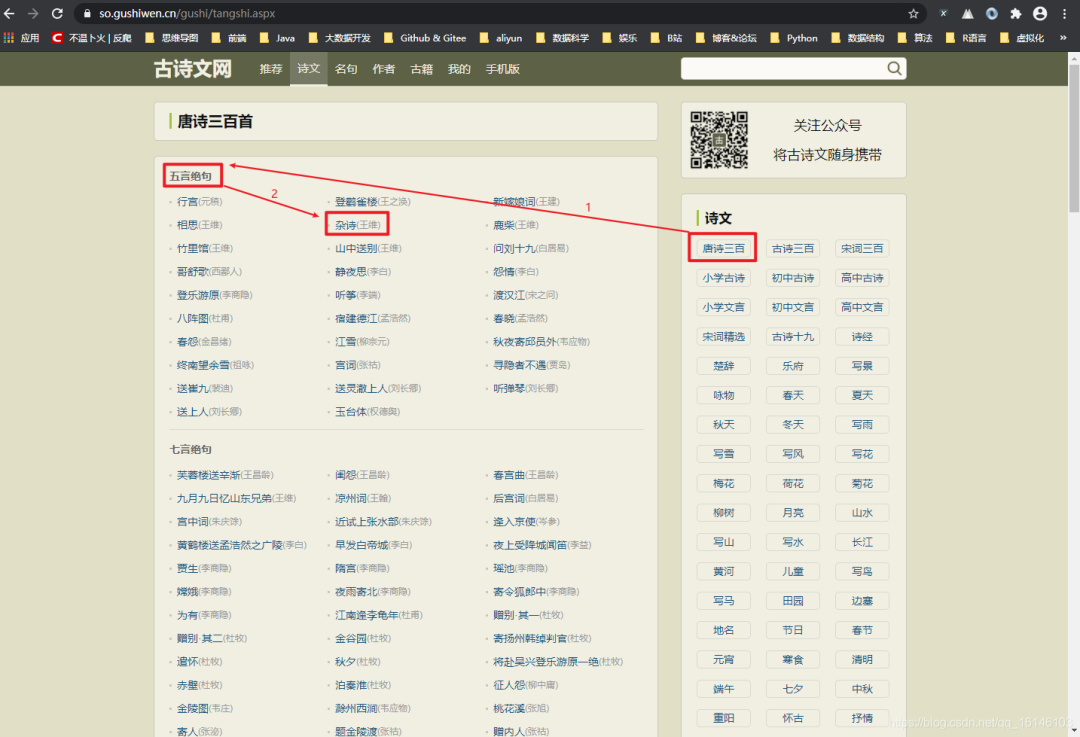
3. 通过开发者选项确定起始URL
![]()
通过查看,我们可以判定我们的起始URL为:https://so.gushiwen.cn/shiwen/
代码:
start_url = "https://so.gushiwen.cn/shiwen/"base_url = "https://so.gushiwen.cn"
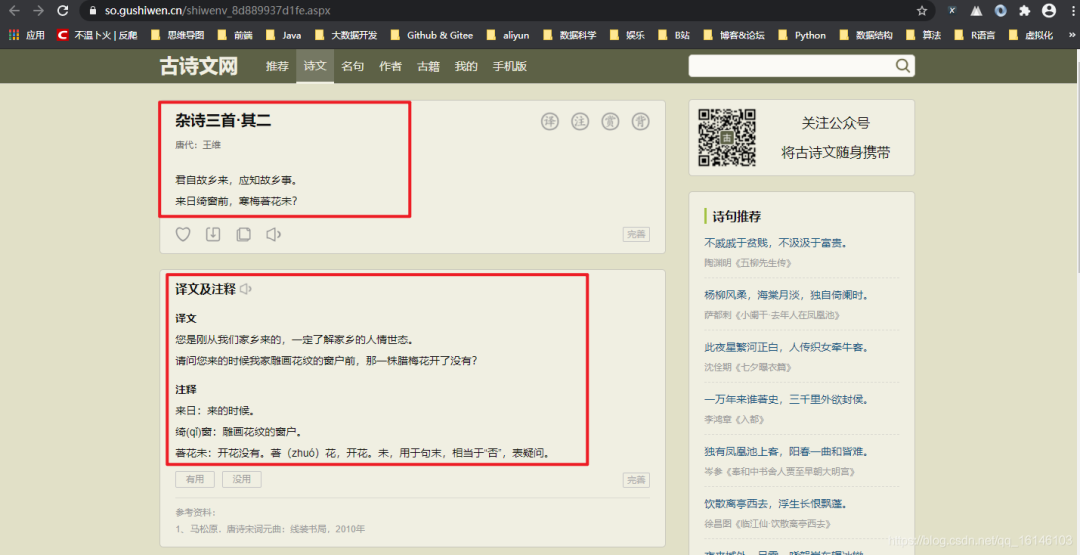
2.2 分析抓取的主要内容
![]()
![]()
根据上述两图我们先确定爬取的内容:一级类型,二级类型,诗词名称,诗词作者,诗词内容,诗词译文及注释
![]()
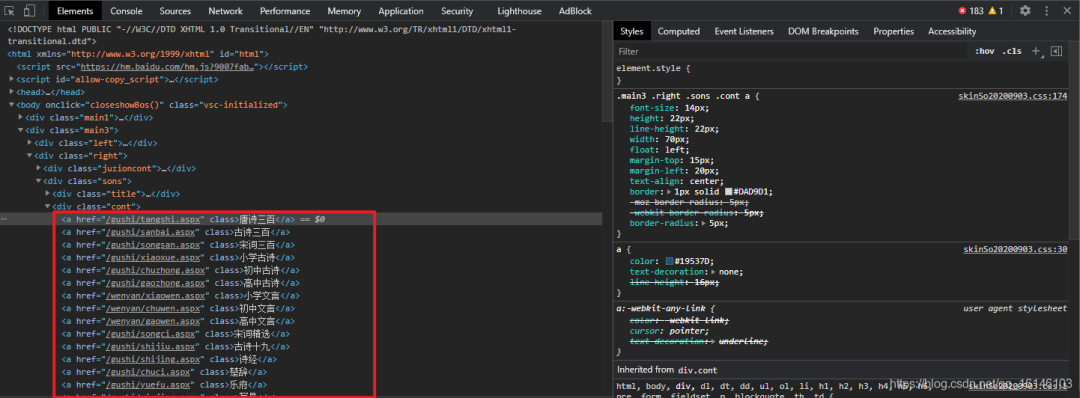
2.3 获取所有的一级类型(错误版本)
1.分析
![]()
2. 尝试xpath解析
![]()
![]()
3.代码实现
import requestsfrom lxml import etree
start_url = "https://so.gushiwen.cn/shiwen/"base_url = "https://so.gushiwen.cn"
headers = { "user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",}
items = []
def parse_url(url): """解析url,得到响应内容""" response = requests.get(url=url, headers=headers) return response.content.decode("utf-8")
def parse_html(html): """使用xpath解析html,返回xpath对象""" etree_obj = etree.HTML(html) return etree_obj
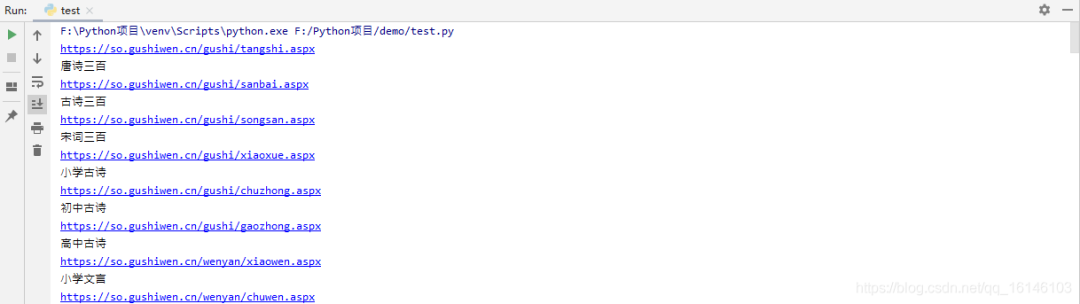
html = parse_url(start_url)etree_obj = parse_html(html)first_type_name_list = etree_obj.xpath('//div[@class="cont"]/a/text()')first_type_url_list = etree_obj.xpath('//div[@class="cont"]/a/@href')print(first_type_name_list)print(first_type_url_list)
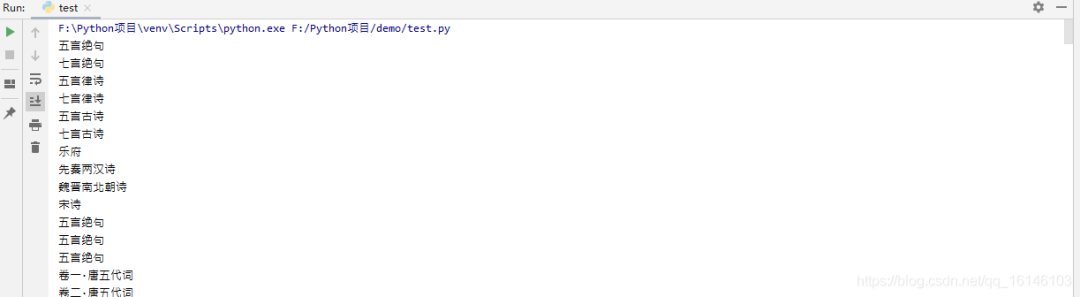
4. 结果
![]()
不知道,同学们有没有发现此处有问题呢?
![]()
2.4 获取所有的一级类型(修改版本)
我们上述的解析式其实是有问题的,它是吧所有的包括作者也解析出来了,看下图:
![]()
正确的写法是这样的
first_type_name_list = etree_obj.xpath('(//a[contains(@href,"/gushi/")]|//a[contains(@href,"/wenyan/")])/text()')first_type_url_list = etree_obj.xpath('(//a[contains(@href,"/gushi/")]|//a[contains(@href,"/wenyan/")])/@href')
![]()
2.5 获取二级标题
1. 解析
![]()
2. 代码
for div in div_list: second_type_name = div.xpath(".//strong/text()") if second_type_name: second_type_name = second_type_name[0] else: second_type_name = "" print(second_type_name)
3. 结果
![]()
2.6 获取二级类型下诗词的名称和url
![]()
1. xpath解析
![]()
![]()
2. 代码
poetry_name_list = div.xpath(".//span/a/text()") poetry_url_list = div.xpath(".//span/a/@href") data_zip = zip(poetry_name_list,poetry_url_list)
2.7 查询数据
2.7.1 拼接URL
1. 拼接一级标题的URL
查询数据的话,首先我们先拼接一级URL
url = base_url + first_type["url"] print(url) first_type_name = first_type["name"] print(first_type_name)
![]()
2. 拼接二级标题的URL
for data in data_zip: item = {} item["first_type_name"] = first_type_name item["second_type_name"] = second_type_name item["poetry_name"] = data[0] poetry_url = base_url+data[1] print(poetry_url)
![]()
2.7.2 内容解析
1. xpath解析
1.诗词名称
![]()
2.诗词作者
![]()
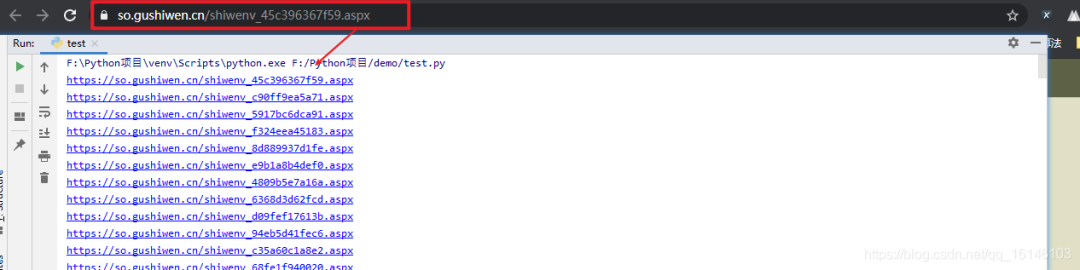
3.诗词内容
![]()
4.诗词译文及注释
![]()
![]()
2. 代码实现
#诗词作者 poetry_author = etree_obj.xpath('//p[@class="source"]')[0].xpath(".//text()") item["poetry_author"] = "".join(poetry_author).strip() #诗词内容 poetry_content = etree_obj.xpath('//*[@id="contson45c396367f59"]/text()') item["poetry_content"] = "".join(poetry_content).strip() #诗词译文和注释 if etree_obj.xpath('//div[@class="contyishang"]'):#有的没有注释 poetry_explain = etree_obj.xpath('//div[@class="contyishang"]')[0].xpath(".//text()") item["poetry_explain"] = "".join(poetry_explain).strip() else: item["poetry_explain"] = "" print(item)
为什么会加上判断语句,是因为网站有反爬机制,通过加上判断机制,才能够正常的循环爬取。
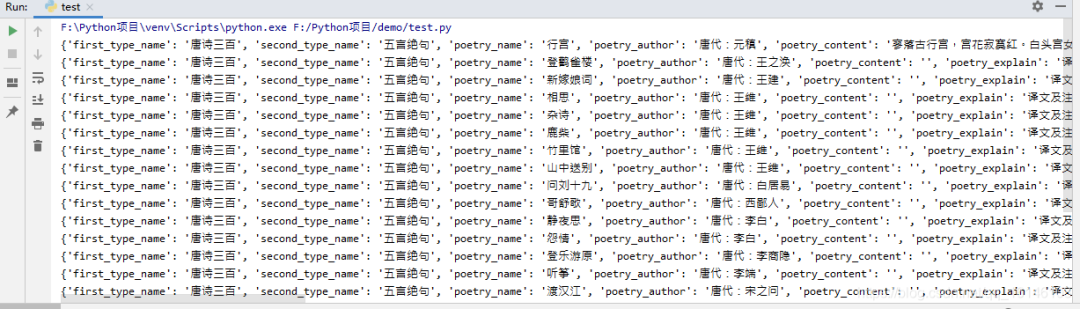
3. 运行结果
![]()
三、完整代码
![]()
''' @software: Pycharm @file: 古诗词.py @Version:1.0 '''"""https://www.gushiwen.cn/https://so.gushiwen.cn/shiwen/"""import requestsimport timeimport randomimport csvfrom lxml import etree
start_url = "https://so.gushiwen.cn/shiwen/"base_url = "https://so.gushiwen.cn"
headers = { "user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",}
items = []
def parse_url(url): """解析url,得到响应内容""" response = requests.get(url=url, headers=headers) return response.content.decode("utf-8")
def parse_html(html): """使用xpath解析html,返回xpath对象""" etree_obj = etree.HTML(html) return etree_obj
def get_first_type(): """获取所有的一级类型""" first_type_list = []
html = parse_url(start_url) etree_obj = parse_html(html)
first_type_name_list = etree_obj.xpath('(//a[contains(@href,"/gushi/")]|//a[contains(@href,"/wenyan/")])/text()') first_type_url_list = etree_obj.xpath('(//a[contains(@href,"/gushi/")]|//a[contains(@href,"/wenyan/")])/@href') data_zip = zip(first_type_name_list, first_type_url_list)
for data in data_zip: first_type = {} first_type["name"] = data[0] first_type["url"] = data[1] first_type_list.append(first_type)
return first_type_list
def get_data(first_type): """查询数据"""
url = base_url + first_type["url"] first_type_name = first_type["name"]
html = parse_url(url) etree_obj = parse_html(html) div_list = etree_obj.xpath('//div[@class="typecont"]') for div in div_list: second_type_name = div.xpath(".//strong/text()") if second_type_name: second_type_name = second_type_name[0] else: second_type_name = "" poetry_name_list = div.xpath(".//span/a/text()") poetry_url_list = div.xpath(".//span/a/@href") data_zip = zip(poetry_name_list,poetry_url_list) for data in data_zip: item = {} item["first_type_name"] = first_type_name item["second_type_name"] = second_type_name item["poetry_name"] = data[0] poetry_url = base_url+data[1] html = parse_url(poetry_url) etree_obj = parse_html(html) poetry_author = etree_obj.xpath('//p[@class="source"]')[0].xpath(".//text()") item["poetry_author"] = "".join(poetry_author).strip() poetry_content = etree_obj.xpath('//*[@id="contson45c396367f59"]/text()') item["poetry_content"] = "".join(poetry_content).strip() if etree_obj.xpath('//div[@class="contyishang"]'): poetry_explain = etree_obj.xpath('//div[@class="contyishang"]')[0].xpath(".//text()") item["poetry_explain"] = "".join(poetry_explain).strip() else: item["poetry_explain"] = "" print(item) save(item)
def save(item): """将数据保存到csv中""" with open("./古诗词.csv", "a", encoding="utf-8") as file: writer = csv.writer(file) writer.writerow(item.values())
def start(): first_type_list = get_first_type() for first_type in first_type_list: get_data(first_type)
if __name__ == '__main__': start()
四、保存结果
![]()
此程序还有一点小问题,就是由于网站存在有JS加密。有一部分无法正常保存下来。不过没关系,后期再进行改进!
正文结束!!!!
![]()
欢迎关注公众号:Python爬虫数据分析挖掘
记录学习python的点点滴滴;
回复【开源源码】免费获取更多开源项目源码;
公众号每日更新python知识和【免费】工具;
本文已同步到【开源中国】、【腾讯云社区】、【CSDN】;
![]()