在stackoverflow关于为什么选择31作为固定乘积值,有一篇讨论文章,Why does Java's hashCode() in String use 31 as a multiplier? 这是一个时间比较久的问题了,摘取两个回答点赞最多的;
「413个赞👍的回答」
最多的这个回答是来自《Effective Java》的内容;
The value 31 was chosen because it is an odd prime. If it were even and the multiplication overflowed, information would be lost, as multiplication by 2 is equivalent to shifting. The advantage of using a prime is less clear, but it is traditional. A nice property of 31 is that the multiplication can be replaced by a shift and a subtraction for better performance: 31 * i == (i << 5) - i. Modern VMs dothis sort of optimization automatically.
这段内容主要阐述的观点包括;
31 是一个奇质数,如果选择偶数会导致乘积运算时数据溢出。
另外在二进制中,2个5次方是32,那么也就是 31 * i == (i << 5) - i。这主要是说乘积运算可以使用位移提升性能,同时目前的JVM虚拟机也会自动支持此类的优化。
「80个赞👍的回答」
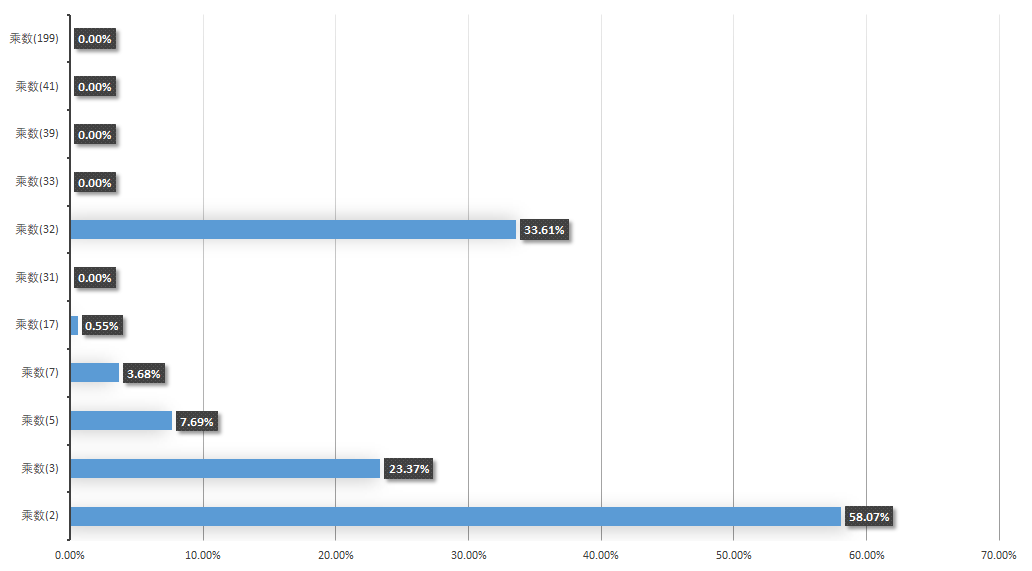
As Goodrich and Tamassia point out, If you take over 50,000English words(formed as the union of the word lists provided in two variants of Unix), using the constants 31, 33, 37, 39, and 41 will produce less than 7 collisions in each case. Knowing this, it should come as no surprise that many Java implementations choose one of these constants.
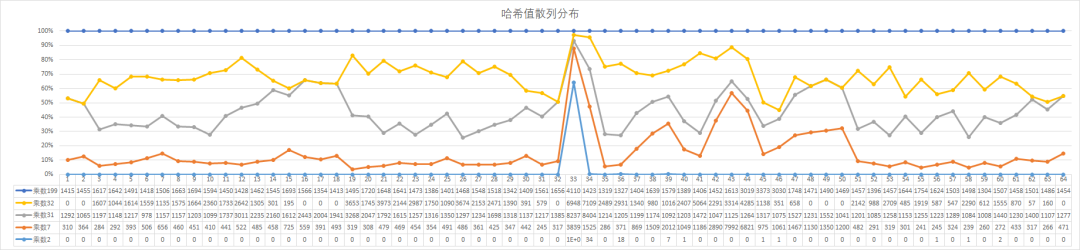
publicstatic Map<Integer, Integer> hashArea(List<Integer> hashCodeList){ Map<Integer, Integer> statistics = new LinkedHashMap<>(); int start = 0; for (long i = 0x80000000; i <= 0x7fffffff; i += 67108864) { long min = i; long max = min + 67108864; // 筛选出每个格子里的哈希值数量,java8流统计;https://bugstack.cn/itstack-demo-any/2019/12/10/%E6%9C%89%E7%82%B9%E5%B9%B2%E8%B4%A7-Jdk1.8%E6%96%B0%E7%89%B9%E6%80%A7%E5%AE%9E%E6%88%98%E7%AF%87(41%E4%B8%AA%E6%A1%88%E4%BE%8B).html int num = (int) hashCodeList.parallelStream().filter(x -> x >= min && x < max).count(); statistics.put(start++, num); } return statistics;
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。