1. 红外小目标检测 红外小目标检测的目标比较小,目标极其容易和其他物体混淆,有一定的挑战性。
另外,这本质上也是一个小目标领域的问题,很多适用于小目标的创新点也会被借鉴进来。
数据来源自@小武
此外,该数据集还有一个特点,就是分背景,虽然同样是检测红外小目标,区别是背景的不同,我们对数据集进行了统计以及通过人工翻看的方式总结了其特点,如下表所示:
背景类别
数量
特点
数据难度
测试mAP+F1
建议
trees
581
背景干净,目标明显,数量较多
低
0.99+0.97
无
cloudless_sky
1320
背景干净,目标明显,数量多
低
0.98+0.99
无
architecture
506
背景变化较大,目标形态变化较大,数量较多
一般
0.92+0.96
focal loss
continuous_cloud_sky
878
背景干净,目标形态变化不大,但个别目标容易会发生和背景中的云混淆
一般
0.93+0.95
focal loss
complex_cloud
561
目标形态基本无变化,但背景对目标的定位影响巨大
较难
0.85+0.89
focal loss
sea
17
背景干净,目标明显,数量极少
一般
0.87+0.88
生成高质量新样本,可以让其转为简单样本(Mixup)
sea_sky
45
背景变化较大,且单张图像中目标个数差异变化大,有密集的难点,且数量少
困难
0.68+0.77
paste策略
通过以上结果,可以看出背景的不同对结果影响还是蛮大的,最后一列也给出了针对性的建议,打算后续实施。
2. 实验过程 首先,我们使用的是U版的yolov3: https://github.com/ultralytics/yolov3,那时候YOLOv4/5、PPYOLO还都没出,当时出了一个《从零开始学习YOLOv3》就是做项目的时候写的电子书,其中的在YOLOv3中添加注意力机制那篇很受欢迎(可以水很多文章出来,毕业要紧:)
我们项目的代码以及修改情况可以查看:https://github.com/GiantPandaCV/yolov3-point
将数据集转成VOC格式的数据集,之前文章有详细讲述如何转化为标准的VOC数据集,以及如何将VOC格式数据集转化为U版的讲解。当时接触到几个项目,都需要用YOLOv3,由于每次都需要转化,大概分别调用4、5个脚本吧,感觉很累,所以当时花了一段时间构建了一个一键从VOC转U版YOLOv3格式的脚本库: https://github.com/pprp/voc2007_for_yolo_torch。
到此时为止,我们项目就已经可以运行了,然后就是很多细节调整了。
2.1 修改Anchor
红外小目标的Anchor和COCO等数据集的Anchor是差距很大的,为了更好更快速的收敛,采用了BBuf总结的一套专门计算Anchor的脚本:
#coding=utf-8 import xml.etree.ElementTree as ETimport numpy as npdef iou (box, clusters) :""" 0 ], box[0 ])1 ], box[1 ])if np.count_nonzero(x == 0 ) > 0 or np.count_nonzero(y == 0 ) > 0 :raise ValueError("Box has no area" )0 ] * box[1 ]0 ] * clusters[:, 1 ]return iou_def avg_iou (boxes, clusters) :""" return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0 ])])def kmeans (boxes, k, dist=np.median) :""" # 即是上面提到的r 0 ]# 距离数组,计算每个ground truth和k个Anchor的距离 # 上一次每个ground truth"距离"最近的Anchor索引 # 设置随机数种子 # 初始化聚类中心,k个簇,从r个ground truth随机选k个 False )]# 开始聚类 while True :# 计算每个ground truth和k个Anchor的距离,用1-IOU(box,anchor)来计算 for row in range(rows):1 - iou(boxes[row], clusters)# 对每个ground truth,选取距离最小的那个Anchor,并存下索引 1 )# 如果当前每个ground truth"距离"最近的Anchor索引和上一次一样,聚类结束 if (last_clusters == nearest_clusters).all():break # 更新簇中心为簇里面所有的ground truth框的均值 for cluster in range(k):0 )# 更新每个ground truth"距离"最近的Anchor索引 return clusters# 加载自己的数据集,只需要所有labelimg标注出来的xml文件即可 def load_dataset (path) :for xml_file in glob.glob("{}/*xml" .format(path)):# 图片高度 "./size/height" ))# 图片宽度 "./size/width" ))for obj in tree.iter("object" ):# 偏移量 "bndbox/xmin" )) / width"bndbox/ymin" )) / height"bndbox/xmax" )) / width"bndbox/ymax" )) / heightif xmax == xmin or ymax == ymin:# 将Anchor的长宽放入dateset,运行kmeans获得Anchor return np.array(dataset)if __name__ == '__main__' :"F:\Annotations" #xml文件所在文件夹 9 #聚类数量,anchor数量 416 #输入网络大小 'Boxes:' )"Accuracy: {:.2f}%" .format(avg_iou(data, out) * 100 )) 0 ] / out[:, 1 ], decimals=2 ).tolist()"Before Sort Ratios:\n {}" .format(final_anchors))"After Sort Ratios:\n {}" .format(sorted(final_anchors)))通过浏览脚本就可以知道,Anchor和图片的输入分辨率有没有关系 这个问题了,当时这个问题有很多群友都在问。通过kmeans函数得到的结果实际上是归一化到0-1之间的,然后Anchor的输出是在此基础上乘以输入分辨率的大小。所以个人认为Anchor和图片的输入分辨率是有关系 的。
此外,U版也提供了Anchor计算,如下:
def kmean_anchors (path='./2007_train.txt' , n=5 , img_size=(416 , 416 ) ) :# from utils.utils import *; _ = kmean_anchors() # Produces a list of target kmeans suitable for use in *.cfg files from utils.datasets import LoadImagesAndLabels0.20 # IoU threshold def print_results (thr, wh, k) :1 ))] # sort small to large 1 )[0 ], iou.min(1 )[0 ]# best possible recall, anch > thr '%.2f iou_thr: %.3f best possible recall, %.2f anchors > thr' %'kmeans anchors (n=%g, img_size=%s, IoU=%.3f/%.3f/%.3f-min/mean/best): ' '' )for i, x in enumerate(k):'%i,%i' % (round(x[0 ]), round(x[1 ])),', ' if i < len(k) - 1 else '\n' ) # use in *.cfg return kdef fitness (thr, wh, k) :# mutation fitness 1 )[0 ] # max iou # best possible recall return iou.mean() * bpr # product # Get label wh True ,True ,True )1 if img_size[0 ] == img_size[1 ] else 10 # number augmentation repetitions for s, l in zip(dataset.shapes, dataset.labels):3 :5 ] *# image normalized to letterbox normalized wh 0 ).repeat(nr, axis=0 ) # augment 10x 0 ], img_size[1 ],0 ],1 )) # normalized to pixels (multi-scale) # Darknet yolov3.cfg anchors False if use_darknet:10 , 13 ], [16 , 30 ], [33 , 23 ], [30 , 61 ], [62 , 45 ],59 , 119 ], [116 , 90 ], [156 , 198 ], [373 , 326 ]])else :# Kmeans calculation from scipy.cluster.vq import kmeans'Running kmeans for %g anchors on %g points...' % (n, len(wh)))0 ) # sigmas for whitening 30 ) # points, mean distance # Evolve 2000 # fitness, generations for _ in tqdm(range(ng), desc='Evolving anchors' ):1 + np.random.random() * np.random.randn(*k.shape) * 0.30 )).clip(2.0 )if fg > f:return k这个和超参数搜索那篇采用的方法类似,也是一种类似遗传算法的方法,通过一代一代的筛选找到合适的Anchor。以上两种方法笔者并没有对比,有兴趣可以试试这两种方法,对比看看。
Anchor这方面设置了三个不同的数量进行聚类:
3 anchor:
13, 18, 16, 22, 19, 256 anchor:
12,17, 14,17, 15,19, 15,21, 13,20, 19,249 anchor:
10,16, 12,17, 13,20, 13,22, 15,18, 15,20, 15,23, 18,23, 21,262.2 构建Baseline
由于数据集是单类的,并且相对VOC等数据集来看,比较单一,所以不打算使用Darknet53这样的深度神经网络,采用的Baseline是YOLOv3-tiny模型,在使用原始Anchor的情况下,该模型可以在验证集上达到mAP@0.5=93.2%,在测试集上达到mAP@0.5=0.869的结果。
那接下来换Anchor,用上一节得到的新Anchor替换掉原来的Anchor,该改掉的模型为yolov3-tiny-6a:
Epoch
Model
P
R
mAP@0.5
F1
dataset
baseline
yolov3-tiny原版
0.982
0.939
0.932
0.96
valid
baseline
yolov3-tiny原版
0.96
0.873
0.869
0.914
test
6a
yolov3-tiny-6a
0.973
0.98
0.984
0.977
valid
6a
yolov3-tiny-6a
0.936
0.925
0.915
0.931
test
可以看到几乎所有的指标都提升了,这说明Anchor先验的引入是很有必要的。
2.3 数据集部分改进
上边已经分析过了,背景对目标检测的结果还是有一定影响的,所以我们先后使用了几种方法进行改进。
第一个:过采样
通过统计不同背景的图像的数量,比如以sea为背景的图像只有17张,而最多的cloudless_sky为背景的图像有1300+张,这就产生了严重的不平衡性。显然cloudless_sky为背景的很简单,sea为背景的难度更大,这样由于数据不平衡的原因,训练得到的模型很可能也会在cloudless_sky这类图片上效果很好,在其他背景下效果一般。
所以首先要采用过采样的方法,这里的过采样可能和别的地方的不太一样,这里指的是将某些背景数量小的图片通过复制的方式扩充。
Epoch
Model
P
R
mAP@0.5
F1
dataset
baseline(os)
yolov3-tiny原版
0.985
0.971
0.973
0.978
valid
baseline(os)
yolov3-tiny原版
0.936
0.871
0.86
0.902
test
baseline
yolov3-tiny原版
0.982
0.939
0.932
0.96
valid
baseline
yolov3-tiny原版
0.96
0.873
0.869
0.914
test
:( 可惜实验结果不支持想法,一起分析一下。ps:os代表over sample
然后进行分背景测试,结果如下:
均衡后的分背景测试
data
num
model
P
R
mAP
F1
trees
506
yolov3-tiny-6a
0.924
0.996
0.981
0.959
sea_sky
495
yolov3-tiny-6a
0.927
0.978
0.771
0.85
sea
510
yolov3-tiny-6a
0.923
0.935
0.893
0.929
continuous_cloud_sky
878
yolov3-tiny-6a
0.957
0.95
0.933
0.953
complex_cloud
561
yolov3-tiny-6a
0.943
0.833
0.831
0.885
cloudless_sky
1320
yolov3-tiny-6a
0.993
0.981
0.984
0.987
architecture
506
yolov3-tiny-6a
0.959
0.952
0.941
0.955
从分背景结果来看,确实sea训练数据很少的结果很好,mAP提高了2个点,但是complex_cloud等mAP有所下降。总结一下就是对于训练集中数据很少的背景类mAP有提升,但是其他本身数量就很多的背景mAP略微下降或者保持。
第二个:在图片中任意位置复制小目标
修改后的版本地址:https://github.com/pprp/SimpleCVReproduction/tree/master/SmallObjectAugmentation
具体实现思路就是,先将所有小目标抠出来备用。然后在图像上复制这些小目标,要求两两之间重合率不能达到一个阈值并且复制的位置不能超出图像边界。
效果如下:(这个是示意图,比较夸张,复制的个数比较多
增强结果
这种做法来自当时比较新的论文《Augmentation for small object detection》,文中最好的结果是复制了1-2次。实际我们项目中也试过1次、2次、3次到多次的结果,都不尽如人意,结果太差就没有记录下来。。(话说论文中展示的效果最佳组合是原图+增强后的图,并且最好的结果也就提高了1个百分点)╮(╯﹏╰)╭
2.4 修改Backbone
修改Backbone经常被群友问到这样一件事,修改骨干网络以后无法加载预训练权重了,怎么办?
有以下几个办法:
干脆不加载,从头训练,简单问题(比如红外小目标)从头收敛效果也不次于有预训练权重的。
不想改代码的话,可以选择修改Backbone之后、YOLO Head之前的部分(比如SPP的位置属于这种情况)
能力比较强的,可以改一下模型加载部分代码,跳过你新加入的模块,这样也能加载(笔者没试过,别找我)。
修改Backbone我们也从几个方向入的手,分为注意力模块、即插即用模块、修改FPN、修改激活函数、用成熟的网络替换backbone和SPP系列。
1. 注意力模块
这个项目中使用的注意力模块,大部分都在公号上写过代码解析,感兴趣的可以翻看一下。笔者前一段时间公布了一个电子书《卷积神经网络中的即插即用模块》也是因为这个项目中总结了很多注意力模块,所以开始整理得到的结果。具体模块还在继续更新:https://github.com/pprp/SimpleCVReproduction
当时实验的模块有:SE、CBAM等,由于当时Baseline有点高,效果并不十分理想。(注意力模块插进来不可能按照预期一下就提高多少百分点,需要多调参才有可能超过原来的百分点)根据群友反馈,SE直接插入成功率比较高。笔者在一个目标检测比赛中见到有一个大佬是在YOLOv3的FPN的三个分支上各加了一个CBAM,最终超过Cascade R-CNN等模型夺得冠军。
2. 即插即用模块
注意力模块也属于即插即用模块,这部分就说的是非注意力模块的部分如 FFM、ASPP、PPM、Dilated Conv、SPP、FRB、CorNerPool、DwConv、ACNet等,效果还可以,但是没有超过当前最好的结果。
3. 修改FPN
FPN这方面花了老久时间,参考了好多版本才搞出了一个dt-6a-bifpn(dt代表dim target红外目标;6a代表6个anchor),令人失望的是,这个BiFPN效果并不好,测试集上效果更差了。可能是因为实现的cfg有问题,欢迎反馈。
大家都知道通过改cfg的方式改网络结构是一件很痛苦的事情,推荐一个可视化工具:
https://lutzroeder.github.io/netron/除此以外,为了方便查找行数,笔者写了一个简单脚本用于查找行数(献丑了
import osimport shutil"./cfg/yolov3-dwconv-cbam.cfg" "./cfg/preprocess_cfg/" 'r' )# 去除以#开头的,属于注释部分的内容 # lines = [x for x in lines if x and not x.startswith('#')] # lines = [x.rstrip().lstrip() for x in lines] -1 for num, line in enumerate(lines):if line.startswith('[' ):1 # s = s.join("") # s = s.join(line) for i,num in enumerate(layers_nums):-1 , '# layer-%d\n' % (num-1 ))'w' )'' .join(lines))我们也尝试了只用一个、两个和三个YOLO Head的情况,结果是3>2>1,但是用3个和2个效果几乎一样,差异不大小数点后3位的差异,所以还是选用两个YOLO Head。
4. 修改激活函数
YOLO默认使用的激活函数是leaky relu,激活函数方面使用了mish。效果并没有提升,所以无疾而终了。
5. 用成熟的网络替换backbone
这里使用了ResNet10(第三方实现)、DenseNet、BBuf修改的DenseNet、ENet、VOVNet(自己改的)、csresnext50-panet(当时AB版darknet提供的)、PRN(作用不大)等网络结构。
当前最强的网络是dense-v3-tiny-spp,也就是BBuf修改的Backbone+原汁原味的SPP组合的结构完虐了其他模型,在测试集上达到了mAP@0.5=0.932、F1=0.951的结果。
6. SPP系列
这个得好好说说,我们三人调研了好多论文、参考了好多trick,大部分都无效,其中从来不会让人失望的模块就是SPP。我们对SPP进行了深入研究,在《卷积神经网络中的各种池化操作》中提到过。
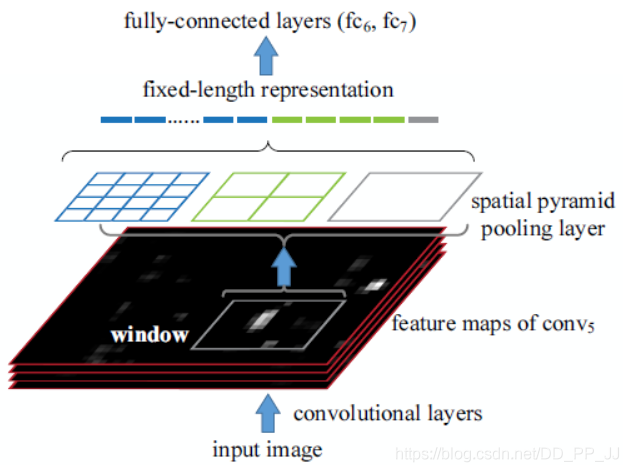
SPP是在SPPNet中提出的,SPPNet提出比较早,在RCNN之后提出的,用于解决重复卷积计算和固定输出的两个问题,具体方法如下图所示:
在feature map上通过selective search获得窗口,然后将这些区域输入到CNN中,然后进行分类。
实际上SPP就是多个空间池化的组合,对不同输出尺度采用不同的划窗大小和步长以确保输出尺度相同,同时能够融合金字塔提取出的多种尺度特征,能够提取更丰富的语义信息。常用于多尺度训练和目标检测中的RPN网络。
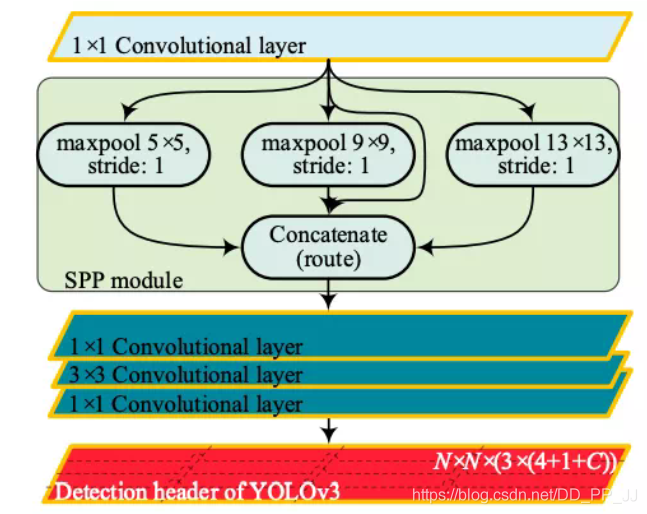
在YOLOv3中有一个网络结构叫yolov3-spp.cfg, 这个网络往往能达到比yolov3.cfg本身更高的准确率,具体cfg如下:
### SPP ### 1 5 -2 1 9 -4 1 13 -1 ,-3 ,-5 ,-6 ### End SPP ### 这里的SPP相当于是原来的SPPNet的变体,通过使用多个kernel size的maxpool,最终将所有feature map进行concate,得到新的特征组合。
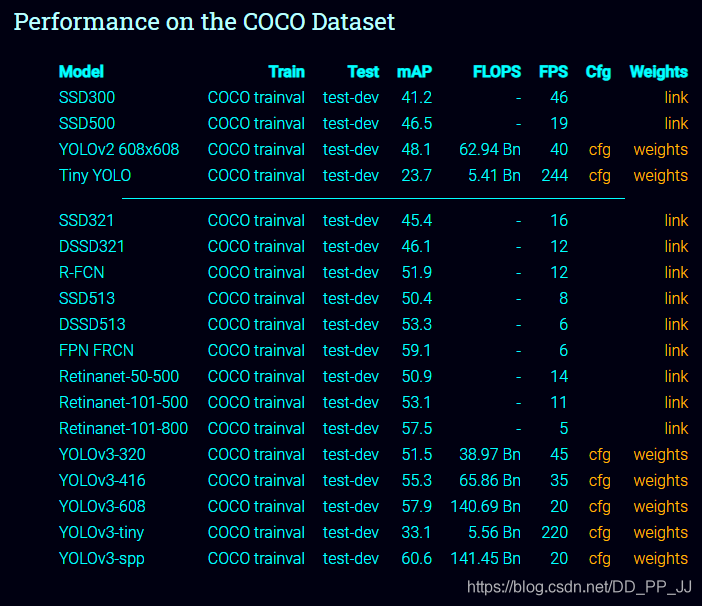
再来看一下官方提供的yolov3和yolov3-spp在COCO数据集上的对比:
可以看到,在几乎不增加FLOPS的情况下,YOLOv3-SPP要比YOLOv3-608mAP高接近3个百分点。
分析一下SPP有效的原因:
从感受野角度来讲,之前计算感受野的时候可以明显发现,maxpool的操作对感受野的影响非常大,其中主要取决于kernel size大小。在SPP中,使用了kernel size非常大的maxpool会极大提高模型的感受野,笔者没有详细计算过darknet53这个backbone的感受野,在COCO上有效很可能是因为backbone的感受野还不够大。
第二个角度是从Attention的角度考虑,这一点启发自CSDN@小楞,他在文章中这样讲:
出现检测效果提升的原因:通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
Attention机制很多都是为了解决远距离依赖问题,通过使用kernel size接近特征图的size可以以比较小的计算代价解决这个问题。另外就是如果使用了SPP模块,就没有必要在SPP后继续使用其他空间注意力模块比如SK block,因为他们作用相似,可能会有一定冗余。
在本实验中,确实也得到了一个很重要的结论,那就是:
SPP是有效的,其中size的设置应该接近这一层的feature map的大小
口说无凭,看一下实验结果:
SPP系列实验
Epoch
Model P R mAP F1 dataset
baseline
dt-6a-spp
0.99
0.983
0.984
0.987
valid
baseline
dt-6a-spp
0.955
0.948
0.929
0.951
test
直连+5x5
dt-6a-spp-5
0.978
0.983
0.981
0.98
valid
直连+5x5
dt-6a-spp-5
0.933
0.93
0.914
0.932
test
直连+9x9
dt-6a-spp-9
0.99
0.983
0.982
0.987
valid
直连+9x9
dt-6a-spp-9
0.939
0.923
0.904
0.931
test
直连+13x13
dt-6a-spp-13
0.995
0.983
0.983
0.989
valid
直连+13x13
dt-6a-spp-13
0.959
0.941
0.93
0.95
test
直连+5x5+9x9
dt-6a-spp-5-9
0.988
0.988
0.981
0.988
valid
直连+5x5+9x9
dt-6a-spp-5-9
0.937
0.936
0.91
0.936
test
直连+5x5+13x13
dt-6a-spp-5-13
0.993
0.988
0.985
0.99
valid
直连+5x5+13x13
dt-6a-spp-5-13
0.936
0.939
0.91
0.938
test
直连+9x9+13x13
dt-6a-spp-9-13
0.981
0.985
0.983
0.983
valid
直连+9x9+13x13
dt-6a-spp-9-13
0.925
0.934
0.907
0.93
test
当前的feature map大小就是13x13,实验结果表示,直接使用13x13的效果和SPP的几乎一样,运算量还减少了。
2.5 修改Loss
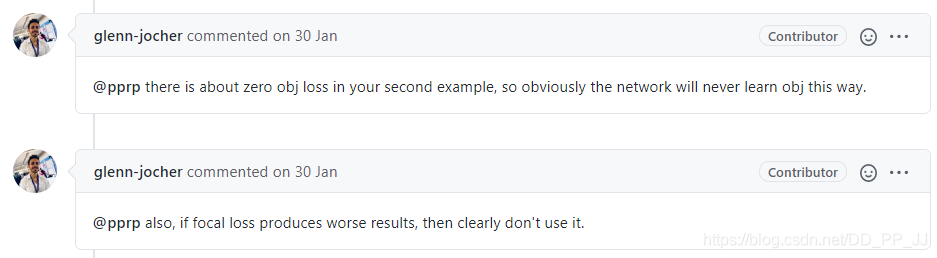
loss方面尝试了focal loss,但是经过调整alpha和beta两个参数,不管用默认的还是自己慢慢调参,网络都无法收敛,所以当时给作者提了一个issue: https://github.com/ultralytics/yolov3/issues/811
glenn-jocher说效果不好就别用:(
作者回复
BBuf也研究了好长时间,发现focal loss在Darknet中可以用,但是效果也一般般。最终focal loss也是无疾而终。此外还试着调整了ignore thresh,来配合focal loss,实验结果如下(在AB版Darknet下完成实验):
state
model
P
R
mAP
F1
data
ignore=0.7
dt-6a-spp-fl
0.97
0.97
0.9755
0.97
valid
ignore=0.7
dt-6a-spp-fl
0.96
0.93
0.9294
0.94
test
ignore=0.3
dt-6a-spp-fl
0.95
0.99
0.9874
0.97
valid
ignore=0.3
dt-6a-spp-fl
0.89
0.92
0.9103
0.90
test
3. 经验性总结 在这个实验过程中,和BBuf讨论有了很多启发,也进行了总结,在这里公开出来,(可能部分结论不够严谨,没有经过严格对比实验,感兴趣的话可以做一下对比实验)。
SPP层是有效的,Size设置接近feature map的时候效果更好。
YOLOv3、YOLOv3-SPP、YOLOv3-tiny三者在检测同一个物体的情况下,YOLOv3-tiny给的该物体的置信度相比其他两个模型低。(其实也可以形象化理解,YOLOv3-tiny的脑容量比较小,所以唯唯诺诺不敢确定)
个人感觉Concate的方法要比Add的方法更柔和,对小目标效果更好。本实验结果上是DenseNet作为Backbone的时候效果是最佳的。
多尺度训练问题,这个文中没提。多尺度训练对于尺度分布比较广泛的问题效果明显,比如VOC这类数据集。但是对于尺度单一的数据集反而有反作用,比如红外小目标数据集目标尺度比较统一,都很小。
Anchor对模型影响比较大,Anchor先验不合理会导致更多的失配,从而降低Recall。
当时跟群友讨论的时候就提到一个想法,对于小目标来说,浅层的信息更加有用,那么进行FPN的时候,不应该单纯将两者进行Add或者Concate,而是应该以一定的比例完成,比如对于小目标来说,引入更多的浅层信息,让浅层网络权重增大;大目标则相反。后边通过阅读发现,这个想法被ASFF实现了,而且想法比较完善。
PyTorch中的Upsample层是不可复现的。
PS: 以上内容不保证结论完全正确,只是经验性总结,欢迎入群讨论交流。
4. 致谢 感谢BBuf和小武和我一起完成这个项目,感谢小武提供的数据和算法,没有小武的支持,我们无法完成这么多实验。感谢BBuf的邀请,我才能加入这个项目,一起讨论对我的帮助非常大(怎么没早点遇见BB:)
虽然最后是烂尾了,但是学到了不少东西,很多文章都是在这个过程中总结得到的,在这个期间总结的文章有《CV中的Attention机制》、《从零开始学习YOLOv3》、《目标检测和感受野的总结和想法》、《PyTorch中模型的可复现性》、《目标检测算法优化技巧》等,欢迎去干货锦集中回顾。
以上是整个实验过程的一部分,后边阶段我们还遇到了很多困难,想将项目往轻量化的方向进行,由于种种原因,最终没有继续下去,在这个过程中,总结一下教训,实验说明和备份要做好,修改的数据集、训练得到的权重、当时的改动点要做好备份。现在回看之前的实验记录和cfg文件都有点想不起来某些模型的改动点在哪里了,还是整理的不够详细,实验记录太乱。
最后希望这篇文章能给大家提供一些思路。
5. 资源列表 官方代码:https://github.com/ultralytics/yolov3
改进代码:https://github.com/GiantPandaCV/yolov3-point
Focal Loss Issue: https://github.com/ultralytics/yolov3/issues/811
小目标增强库(复制和粘贴的方式):https://github.com/pprp/SimpleCVReproduction/tree/master/SmallObjectAugmentation
pprp Github: https://github.com/pprp
BBuf Github:https://github.com/BBuf
以上涉及到的所有实验结果已经整理成markdown文件,请在后台回复“红外”获得。
为了感谢读者朋友们的长期支持,我们今天将送出3本由机械工业出版社提供的《人脸识别与美颜算法实战》书籍,对本书感兴趣的可以在留言版留言,我们将抽取其中三位读者送出一本正版书籍。
!!!留言区在这里!!!
没中奖的读者如果有对此书感兴趣的,可以考虑点击下方的当当网链接自行购买。
对文章有疑问或者希望加入GiantPandaCV交流群的可以添加以下微信
BBuf
pprp