点击上方
“AI小白学视觉
”,选择加"
星标
"或“
置顶
”
重磅干货,第一时间送达
![]()
![]()
图像拼接是计算机视觉中最成功的应用之一。如今,很难找到不包含此功能的手机或图像处理API。在本文中,我们将讨论如何使用Python和OpenCV进行图像拼接。也就是,给定两张共享某些公共区域的图像,目标是“缝合”它们并创建一个全景图像场景。当然也可以是给定多张图像,但是总会转换成两张共享某些公共区域图像拼接的问题,因此本文以最简单的形式进行介绍。
本文主要的知识点包含一下内容:
关键点检测
局部不变描述符(SIFT,SURF等)
特征匹配
使用RANSAC进行单应性估计
透视变换
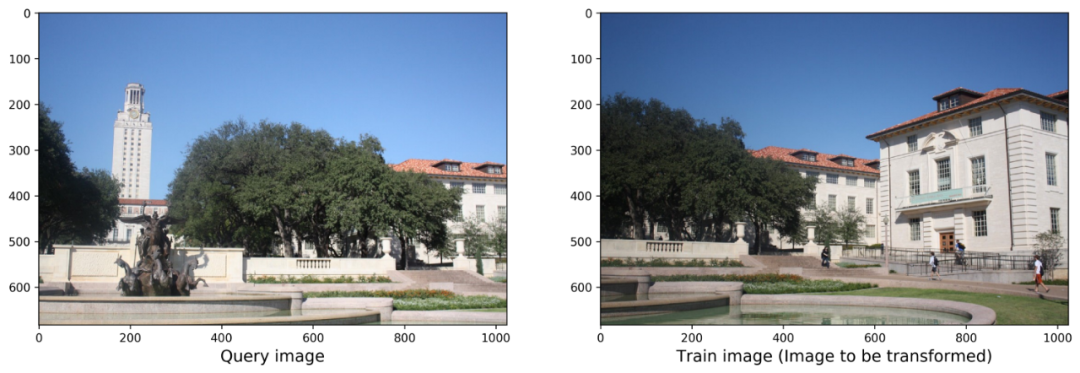
我们需要拼接的两张图像如下:
![]()
特征检测与提取
给定上述一对图像,我们希望将它们缝合以创建全景场景。重要的是要注意,两个图像都需要有一些公共区域。当然,我们上面给出的两张图像时比较理想的,有时候两个图像虽然具有公共区域,但是同样还可能存在缩放、旋转、来自不同相机等因素的影响。但是无论哪种情况,我们都需要检测图像中的特征点。
关键点检测
最初的并且可能是幼稚的方法是使用诸如Harris Corners之类的算法来提取关键点。然后,我们可以尝试基于某种相似性度量(例如欧几里得距离)来匹配相应的关键点。众所周知,角点具有一个不错的特性:角点不变。这意味着,一旦检测到角点,即使旋转图像,该角点仍将存在。
但是,如果我们旋转然后缩放图像怎么办?在这种情况下,我们会很困难,因为角点的大小不变。也就是说,如果我们放大图像,先前检测到的角可能会变成一条线!
总而言之,我们需要旋转和缩放不变的特征。那就是更强大的方法(如SIFT,SURF和ORB)。
关键点和描述符
诸如SIFT和SURF之类的方法试图解决角点检测算法的局限性。通常,角点检测器算法使用固定大小的内核来检测图像上的感兴趣区域(角)。不难看出,当我们缩放图像时,该内核可能变得太小或太大。为了解决此限制,诸如SIFT之类的方法使用高斯差分(DoD)。想法是将DoD应用于同一图像的不同缩放版本。它还使用相邻像素信息来查找和完善关键点和相应的描述符。
首先,我们需要加载2个图像,一个查询图像和一个训练图像。最初,我们首先从两者中提取关键点和描述符。通过使用OpenCV detectAndCompute()函数,我们可以一步完成它。请注意,为了使用detectAndCompute(),我们需要一个关键点检测器和描述符对象的实例。它可以是ORB,SIFT或SURF等。此外,在将图像输入给detectAndCompute()之前,我们将其转换为灰度。
def detectAndDescribe(image, method=None): """ Compute key points and feature descriptors using an specific method """
assert method is not None, "You need to define a feature detection method. Values are: 'sift', 'surf'"
# detect and extract features from the image if method == 'sift': descriptor = cv2.xfeatures2d.SIFT_create() elif method == 'surf': descriptor = cv2.xfeatures2d.SURF_create() elif method == 'brisk': descriptor = cv2.BRISK_create() elif method == 'orb': descriptor = cv2.ORB_create()
# get keypoints and descriptors (kps, features) = descriptor.detectAndCompute(image, None)
return (kps, features)
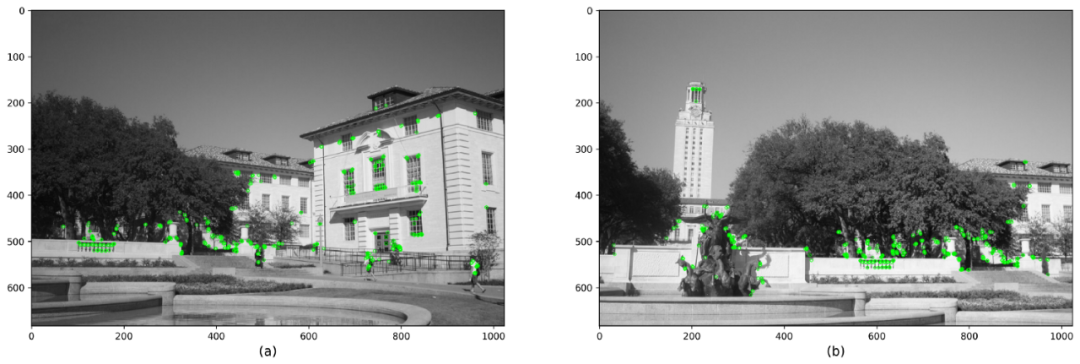
我们为两个图像都设置了一组关键点和描述符。如果我们使用SIFT作为特征提取器,它将为每个关键点返回一个128维特征向量。如果选择SURF,我们将获得64维特征向量。下图显示了使用SIFT,SURF,BRISK和ORB得到的结果。
![]()
使用ORB和汉明距离检测关键点和描述符
![]()
使用SIFT检测关键点和描述符
![]()
使用SURF检测关键点和描述符
![]()
使用BRISK和汉明距离检测关键点和描述符
特征匹配
如我们所见,两个图像都有大量特征点。现在,我们想比较两组特征,并尽可能显示更多相似性的特征点对。使用OpenCV,特征点匹配需要Matcher对象。在这里,我们探索两种方式:暴力匹配器(BruteForce)和KNN(k最近邻)。
BruteForce(BF)Matcher的作用恰如其名。给定2组特征(来自图像A和图像B),将A组的每个特征与B组的所有特征进行比较。默认情况下,BF Matcher计算两点之间的欧式距离。因此,对于集合A中的每个特征,它都会返回集合B中最接近的特征。对于SIFT和SURF,OpenCV建议使用欧几里得距离。对于ORB和BRISK等其他特征提取器,建议使用汉明距离。我们要使用OpenCV创建BruteForce Matcher,一般情况下,我们只需要指定2个参数即可。第一个是距离度量。第二个是是否进行交叉检测的布尔参数。具体代码如下:
def createMatcher(method,crossCheck): "Create and return a Matcher Object"
if method == 'sift' or method == 'surf': bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=crossCheck) elif method == 'orb' or method == 'brisk': bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=crossCheck) return bf
交叉检查布尔参数表示这两个特征是否具有相互匹配才视为有效。换句话说,对于被认为有效的一对特征(f1,f2),f1需要匹配f2,f2也必须匹配f1作为最接近的匹配。此过程可确保提供更强大的匹配功能集,这在原始SIFT论文中进行了描述。
但是,对于要考虑多个候选匹配的情况,可以使用基于KNN的匹配过程。KNN不会返回给定特征的单个最佳匹配,而是返回k个最佳匹配。需要注意的是,k的值必须由用户预先定义。如我们所料,KNN提供了更多的候选功能。但是,在进一步操作之前,我们需要确保所有这些匹配对都具有鲁棒性。
比率测试
为了确保KNN返回的特征具有很好的可比性,SIFT论文的作者提出了一种称为比率测试的技术。一般情况下,我们遍历KNN得到匹配对,之后再执行距离测试。对于每对特征(f1,f2),如果f1和f2之间的距离在一定比例之内,则将其保留,否则将其丢弃。同样,必须手动选择比率值。
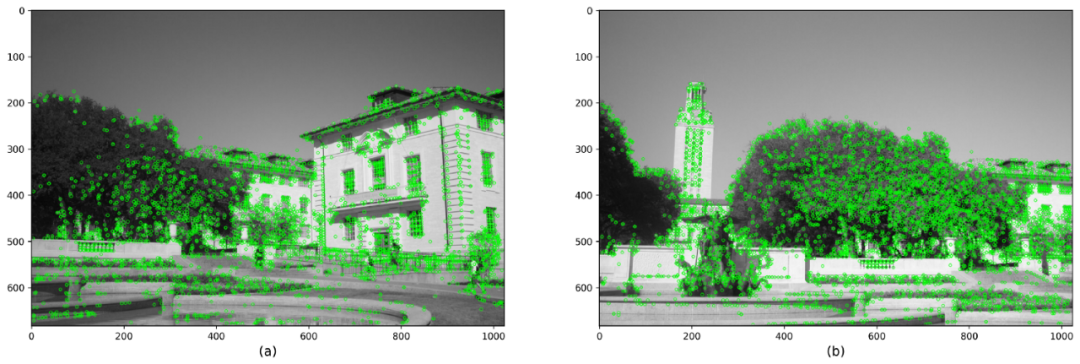
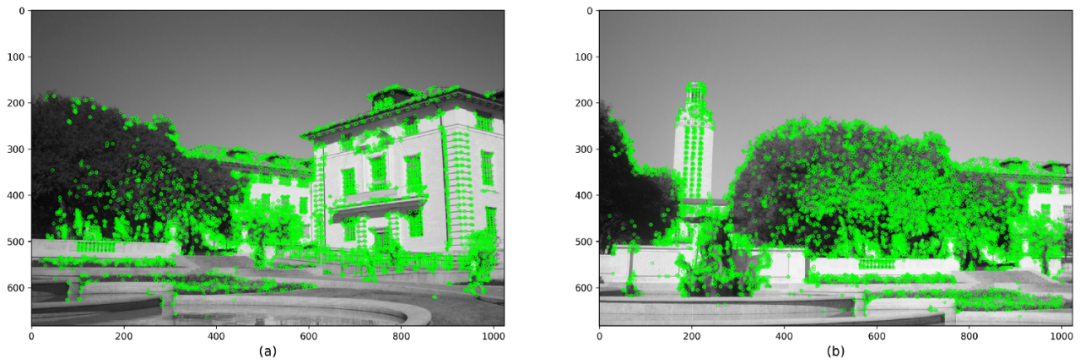
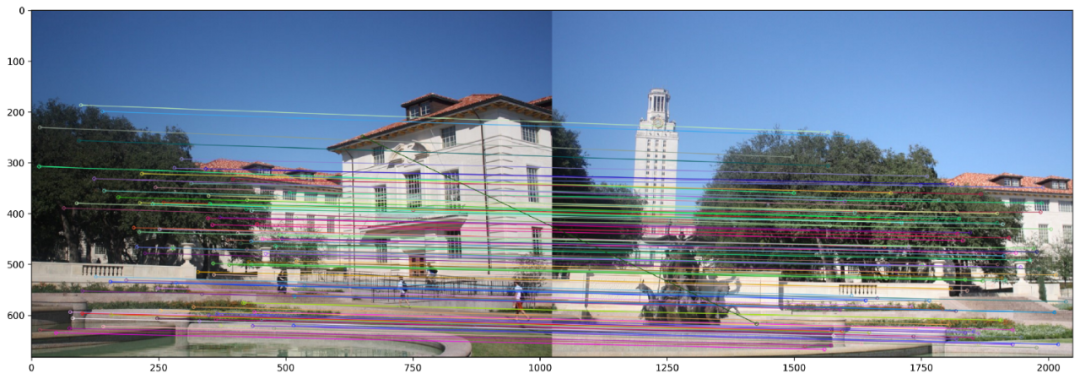
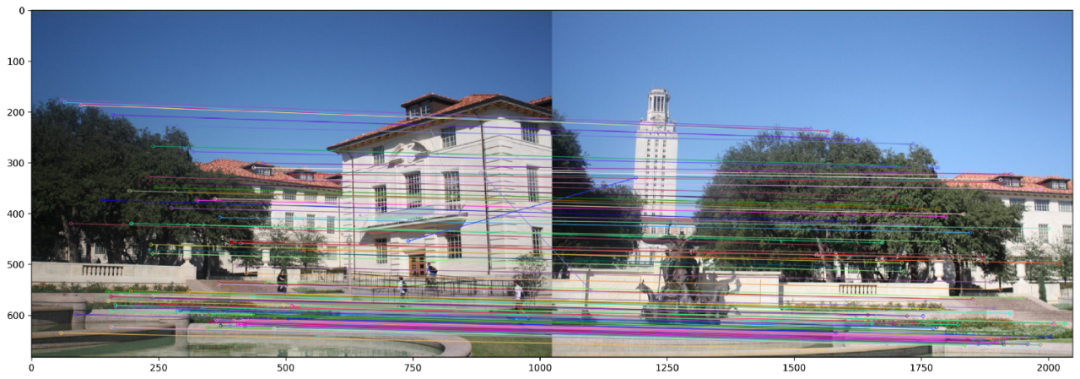
本质上,比率测试与BruteForce Matcher的交叉检查选项具有相同的作用。两者都确保一对检测到的特征确实足够接近以至于被认为是相似的。下面2个图显示了BF和KNN Matcher在SIFT特征上的匹配结果。我们选择仅显示100个匹配点以清晰显示。
![]()
使用KNN和SIFT的定量测试进行功能匹配
![]()
在SIFT特征上使用暴力匹配器进行特征匹配
需要注意的是,即使做了多种筛选来保证匹配的正确性,也无法完全保证特征点完全正确匹配。尽管如此,Matcher算法仍将为我们提供两幅图像中最佳(更相似)的特征集。接下来,我们利用这些点来计算将两个图像的匹配点拼接在一起的变换矩阵。
这种变换称为单应矩阵。简而言之,单应性是一个3x3矩阵,可用于许多应用中,例如相机姿态估计,透视校正和图像拼接。它将点从一个平面(图像)映射到另一平面。
估计单应性
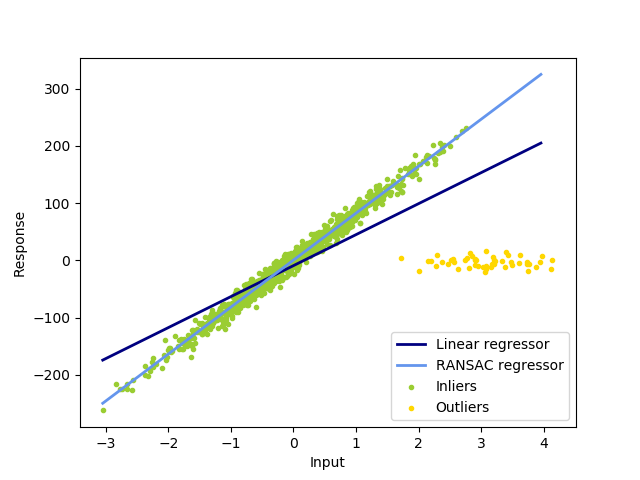
随机采样一致性(RANSAC)是用于拟合线性模型的迭代算法。与其他线性回归器不同,RANSAC被设计为对异常值具有鲁棒性。
像线性回归这样的模型使用最小二乘估计将最佳模型拟合到数据。但是,普通最小二乘法对异常值非常敏感。如果异常值数量很大,则可能会失败。RANSAC通过仅使用数据中的一组数据估计参数来解决此问题。下图显示了线性回归和RANSAC之间的比较。需要注意数据集包含相当多的离群值。
![]()
我们可以看到线性回归模型很容易受到异常值的影响。那是因为它试图减少平均误差。因此,它倾向于支持使所有数据点到模型本身的总距离最小的模型。包括异常值。相反,RANSAC仅将模型拟合为被识别为点的点的子集。
这个特性对我们的用例非常重要。在这里,我们将使用RANSAC来估计单应矩阵。事实证明,单应矩阵对我们传递给它的数据质量非常敏感。因此,重要的是要有一种算法(RANSAC),该算法可以从不属于数据分布的点中筛选出明显属于数据分布的点。
估计了单应矩阵后,我们需要将其中一张图像变换到一个公共平面上。在这里,我们将对其中一张图像应用透视变换。透视变换可以组合一个或多个操作,例如旋转,缩放,平移或剪切。我们可以使用OpenCV warpPerspective()函数。它以图像和单应矩阵作为输入。
width = trainImg.shape[1] + queryImg.shape[1]height = trainImg.shape[0] + queryImg.shape[0]
result = cv2.warpPerspective(trainImg, H, (width, height))result[0:queryImg.shape[0], 0:queryImg.shape[1]] = queryImg
plt.figure(figsize=(20,10))plt.imshow(result)
plt.axis('off')plt.show()
生成的全景图像如下所示。如我们所见,结果中包含了两个图像中的内容。另外,我们可以看到一些与照明条件和图像边界边缘效应有关的问题。理想情况下,我们可以执行一些处理技术来标准化亮度,例如直方图匹配,这会使结果看起来更真实和自然一些。
![]()
![]()
![]()
![]()
![]()
![]()
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
![]()
![]()