在大数据生态中有很多文件格式,像 Parquet,ORC,Avro 等等,都是针对嵌套数据设计的文件格式。这些文件格式普遍具有预先定义的schema,数据以行式写入,按属性组织,列式存储。但是这些文件格式一般不能很好地满足时间序列数据的管理需求。比如,在一些时间序列数据的场景中,一般各个序列是独立写入的,时间戳并不对齐;查询结果也需要按照时间戳排序。TsFile(Time series File)就是我们为时序数据场景设计的文件格式。今天主要介绍用法,主要针对 0.10 版本。
使用场景
文件格式由于比较轻量级,适合在边缘端当做一个数据压缩包使用,这个边缘端可以是设备内部,也可以是工控机、工厂层级。设备上生成的数据可以随时持久化到文件中进行存储。这里说的设备可能一台风机,上边会有多个测点,比如风速传感器、温度传感器等。每个传感器采集的数据就是一个时间序列。联想的IoT平台自2017年就开始使用TsFile存储时序数据。
因此,TsFile 的目标场景是管理一个或多个设备的时序数据。
设备-测点模型
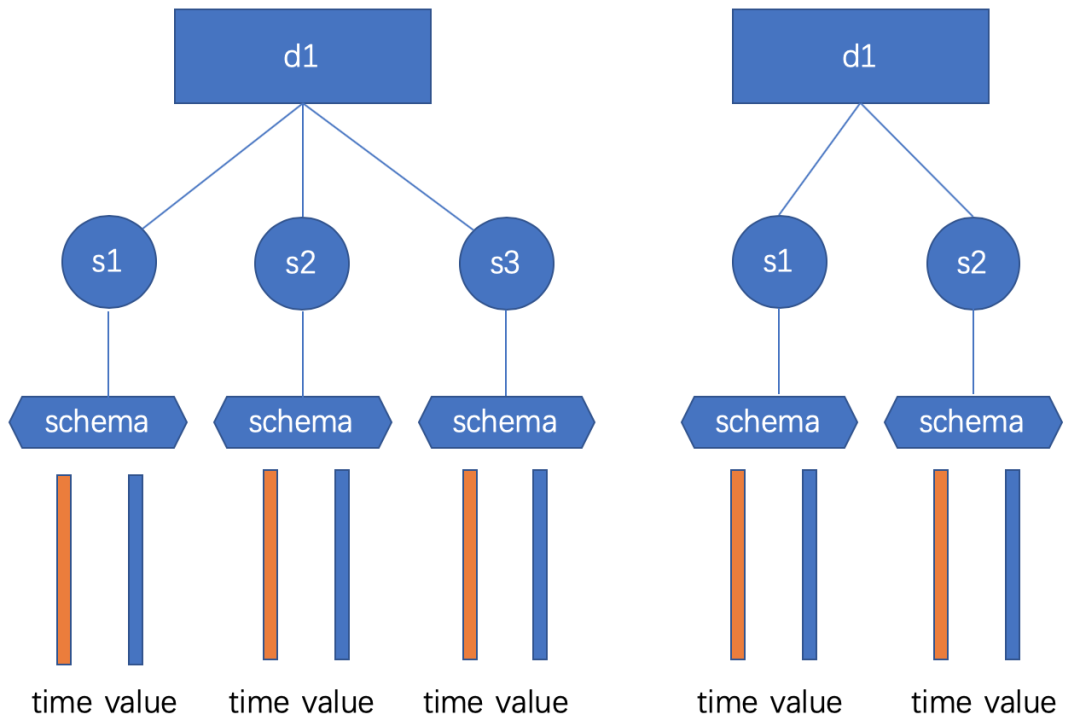
设备(DeviceId):类似表的概念。
测点(MeasurementId):一个设备可以有多个测点,类似表中的列的概念。
时间序列路径(Path):可以通过设备和测点定义 Path(设备Id,测点Id)。
测点描述信息(MeasurementSchema):每个时间序列都对应一个描述信息,包括数据类型、编码方式、压缩方式。
每个时间序列都有两列:时间列、值列。
最近喜欢画图,来画一张,基本就是这样的,不同设备可以有不同的测点。
![]()
注册元数据
使用 TsFile,第一步就是注册元数据。
注册时间序列:Path+MeasurementSchema
可以通过这种方式把每个时间序列都注册进去。
注册时间序列需要提供一个 Path 和一个 MeasurementSchema
String path = "test.tsfile";
在 0.10 以前,所有设备都共享一个点表,同名 Measurement 的 schema 也需要一样(这就是IoTDB里一个存储组下同名测点类型需要一样的限制的来源)。在 0.10 以后,每个时间序列做到了真正的独立,互不干扰。
按模板注册设备:设备模板+设备
上面这样一条一条注册比较麻烦,因此提供了一个设备模板的功能。每个模板定义了一组 MeasurementSchema,比如有10个测点,当一个设备关联到了这个模板上,就自动注册出了 10 个序列。
首先生成设备模板,然后注册模板。
Map<String, MeasurementSchema> template = new HashMap<>();
接下来注册设备,按模板名关联到模板上:
tsFileWriter.registerDevice("device_1", "template_1");
这样,我就注册了 2 个设备,每个设备都有 2 个测点。
注册一个模板,实时写入数据
这个是高级简化版。当我们只注册了一个设备模板时,可以不注册设备,直接写入数据。写入流程中如果发现这个设备写入的数据没有注册,会直接到模板里找同名的 MeasurementSchema 进行注册。这也是继承了 0.9 以前版本的优良传统(0.9以前的版本,TsFile 只能注册一个模板,然后就可以写数据了)。
写数据
TsFile 的数据写入有一个限制,每列都需要按照时间递增写入,否则不保证正确性。
按设备写入一行数据:TSRecord
一个 TSRecord 是一个设备,一个时间戳,多个测点的值。类似一个表的一行数据。
按设备写入一批数据:Tablet
哈哈,又看到了 Tablet,对,这个结构是贯穿 TsFile 和 IoTDB Session 的一个结构。表示一个设备,多个时间戳的多个测点的值,类似一个子表。这个子表不能有空值。
同样,这种写入接口速度快,可以达到每秒千万点写入速度。
读数据
查询的接口接收一批路径,一个表达式(可以进行时间过滤和值过滤),其实就对应了 select 和 where 两个子句。
在查询时候,TsFile 的默认表结构是宽表,time, d1.m1, d1.m2, d2.m1, d2.m2。这个结构默认是把给定的查询 Path 按 Time 做对齐,并且进行条件过滤的。
资料
示例代码:
https://github.com/apache/incubator-iotdb/blob/master/example/tsfile/
文档:
http://iotdb.apache.org/zh/UserGuide/V0.10.x/Client/Programming%20-%20TsFile%20API.html
总结
今天介绍了时间序列文件格式 TsFile 的数据模型,元数据注册,写入和读取过程。就到这啦。大家来点 Star 吧!
https://github.com/apache/incubator-iotdb/tree/master
点赞!关注!转发!
![]()
本文分享自微信公众号 - IoTDB漫游指南(Apache-IoTDB)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。