
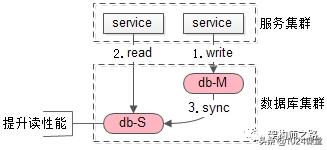
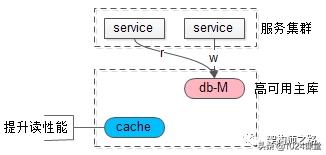
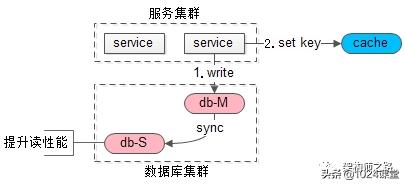
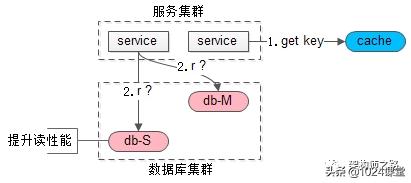

吐血总结了各个中间件是如何实现持久化的
文转载自微信公众号「Java3y」,作者Java3y。转载本文请联系Java3y公众号。 \到目前为止,三歪也已经接触到了不少的中间件了,比如说「Elasticsearch」「Redis」「HDFS」「Kafka」「HBase」等等。 可以发现的是,它们的持久化机制都差不得太多。今天想来总结一下,一方面想来回顾一下这些组件,一方面给还没入门过这些中间件的同学总结一下持久化的”套路“,后面再去学习的时候就会轻松很多。 这些中间件我的GitHub目录都是在的: https://github.com/ZhongFuCheng3y/3y https://gitee.com/zhongfucheng/Java3y 持久化 下面我们就直接来分别回顾一下各个中间件/组件的持久化机制,最后再总结就好了(三歪相信大家应该也能从回顾中看出些端倪) 为什么要持久化?原因也很简单:数据需要存储下来,不希望出了问题导致数据丢失 Elasticsearch Elasticsearch是一个全文搜索引擎,对模糊搜索非常擅长。 Elasticsearch在写数据的时候,会先写到内存缓存区,然后写到translog缓存...