OSCHINA APP v4.9.8 发布
OSCHINA APP v4.9.8 版本发布了。此版本修复了一些 bug。 新版更新日志: 升级了 QQSDK,适配 QQAndroid 10 纯图分享 修复了问答评论转发动弹失效的 bug 修复分享图片二维码失效的 bug 修复网络异常状态下动弹详情闪退的 bug 删除了博客打赏 修复主页内存被回收,tab 状态显示异常的 bug 安卓下载:→戳我戳我戳我← 扫码下载↓↓↓
本系列文章主要介绍HTAP数据库BaikalDB的技术实现细节。
作者介绍:罗小兵,百度商业平台研发部高级研发工程师,主要负责BaikalDB事务能力,全局二级索引等方向的研发工作。
欢迎关注 Star github.com/baidu/BaikalDB 国内加速镜像库gitee
BaikalDB是一个分布式可扩展的存储系统,兼容MySQL协议,整个系统的架构如下图所示:
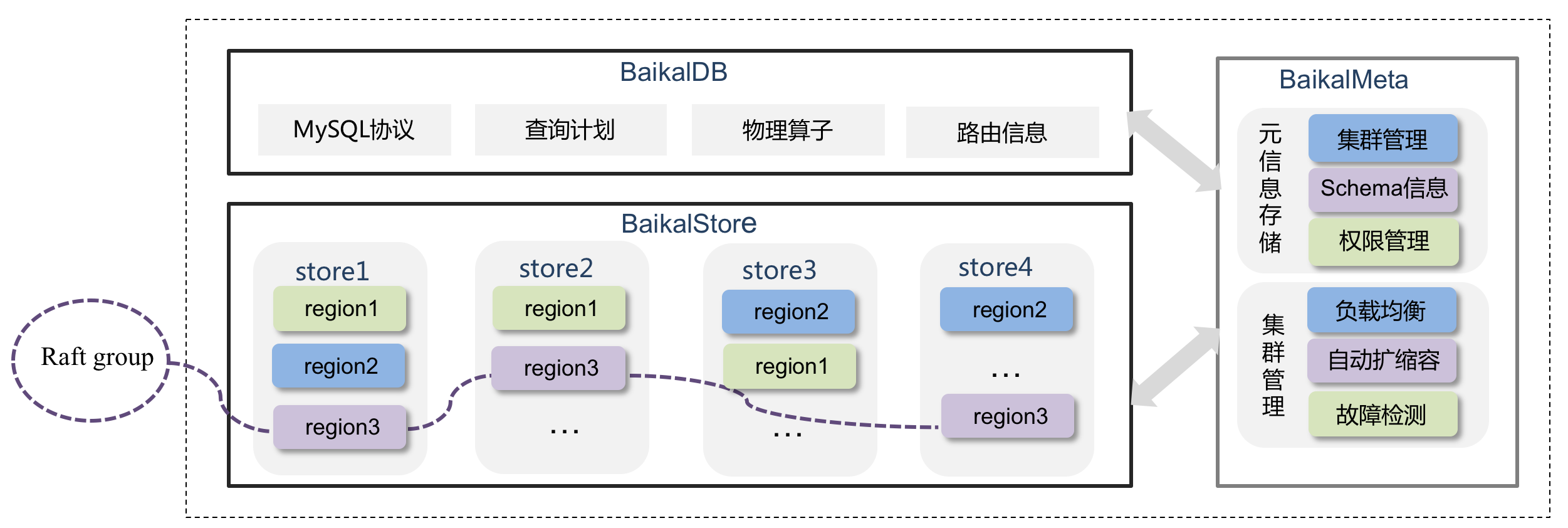
BaikalDB将数据按照range进行切分,每个分区称为region,连续的region组成了数据的整个区间。不同的region位于不同的BaikalStore实例,在不同的机器上,那么当一个SQL语句涉及多个region的更新时,如何保证所有的更新,要么全部成功,要么全部失败呢,这就需要分布式事务。讲到事务,我们先回顾一下事务的ACID特性:
分布式事务就是在分布式环境下实现和传统数据库事务一样的 ACID 功能,目前BaikalDB实现了分布式事务的功能,支持的事务相关的SQL语句包括:
BaikalDB通过两阶段提交协议(2PC),借助RocksDB的Pessimistic事务和Savepoint机制实现分布式事务。下面逐步介绍BaikalDB的分布式事务实现,当然,分布式事务非常复杂,BaikalDB的分布式事务还在不断的迭代开发。
二阶段提交协议(Two-phase Commit,即2PC)是常用的分布式事务原子提交的解决办法,它有一个协调者(coordinator)和多个参与者(participant),可以保证在分布式事务中,要么所有参与者要么都提交事务,要么都取消事务,交互流程如图所示:
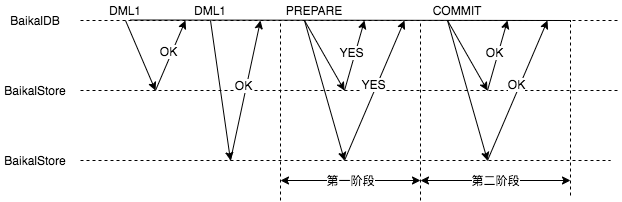
协调者的提交过程分两个步骤分别与参与者交互:
BaikalDB的分布式事务通过2PC+RocksDB的单机事务实现悲观事务。
一次事务执行通常包括BEGIN语句,一个或多个DML语句,COMMIT语句或ROLLBACK语句,BaikalDB为每个语句都分配了一个seq_id,并且seq_id单调连续递增。
seq_id=1对应BEGIN语句,会在BaikalDB缓存,和第一条DML语句一起发送给BaikalStore,然后BEGIN语句会在BaikalStore创建一个RocksDB的Pessimistic事务,接着开始执行之后的DML语句,同时BaikalStore会记录当前执行过的DML语句的seq_id,用于事务幂等处理,COMMIT语句实际上分成了PREPARE + COMMIT,先发PREPARE到各个region,都返回成功,再发COMMIT。
下表介绍了与事务相关的数据信息:
| 数据 | 描述 |
|---|---|
| 事务ID(txn_id) | 全局唯一都事务ID,由两部分组成,BaikalDB全局唯一的实例ID(下文中的server_instance_id,占用3 bytes)和BaikalDB实例内部ID(5 bytes,实例内部全局唯一且递增) |
| DML语句ID(seq_id) | 当前命令在事务内部的序列号,在事务内由1开始连续递增 |
| BaikalDB实例ID(server_instance_id) | BaikalDB全局唯一的实例ID(占用3 bytes,由BaikalMeta统一分配) |
| 待回滚的DML语句ID(need_rollback_seq) | 实现多语句局部回滚 |
| 事务所有DML语句集合(cache_plans) | 缓存了事务中的所有语句的执行计划,用于在事务执行过程中发生Region分裂或RAFT切主时进行重试 |
BaikalDB与BaikalStore事务交互的message为:
message TransactionInfo {
required uint64 txn_id = 1; // 由baikaldb生成的全局事务id
required int32 seq_id = 2; // 当前语句的seq_id
optional int32 start_seq_id = 3; // the start_seq_id of the command in this request (include cached)
optional bool optimize_1pc = 4; // 单region 1pc优化
repeated int32 need_rollback_seq = 5; //因为在某些region上执行失败,需要全局回滚seq_id
repeated CachePlan cache_plans = 6; //缓存的query的执行计划
optional bool autocommit = 7;
};
下面举例说明多语句事务整个两阶段提交示意图:
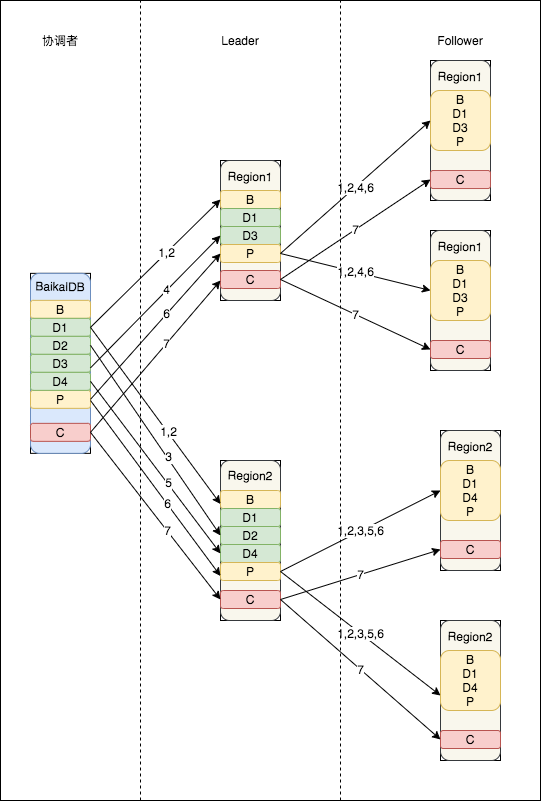
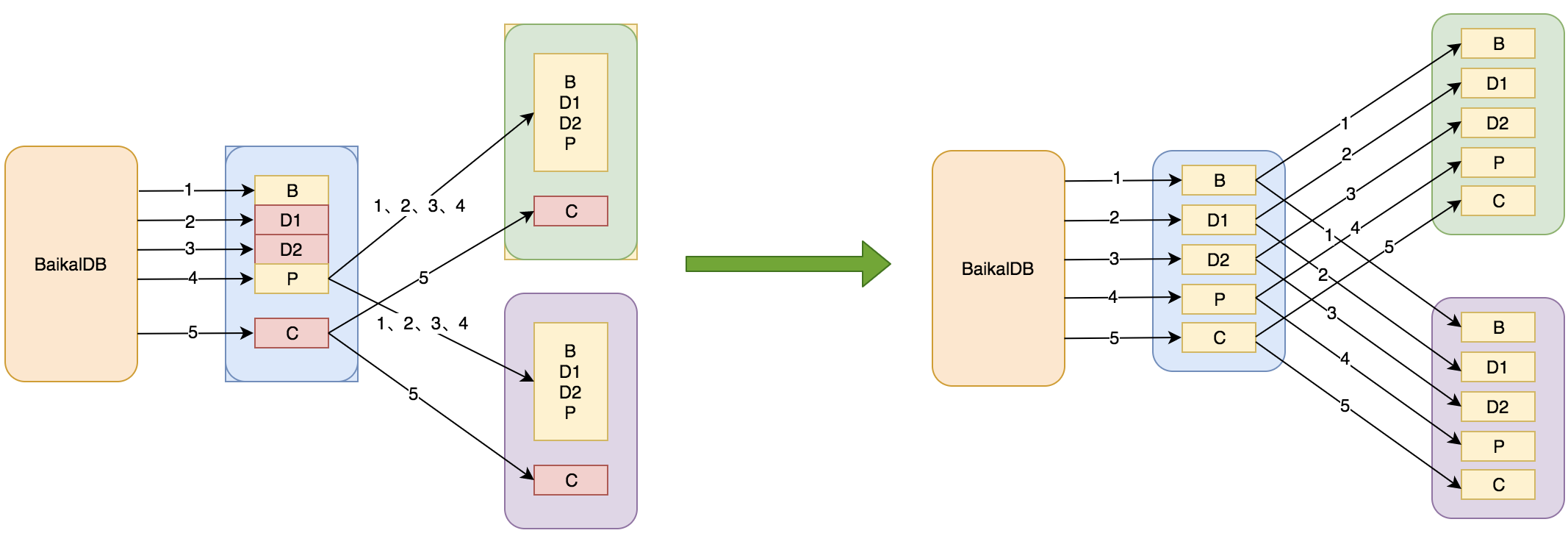
整个多语句事务语句执行的序列为BEGIN,D1,D2,D3,D4,P,C。
对于多语句事务,某些DML失败不影响整个事务的提交,当其中某一条DML语句涉及多个region时,可能一些region执行成功,一些region执行失败,当有region执行失败时需要回滚整条DML已经操作过的region,不然多region之间数据会不一致,BaikalDB利用了RocksDB的Savepoint机制来保证数据一致性。
具体实现:
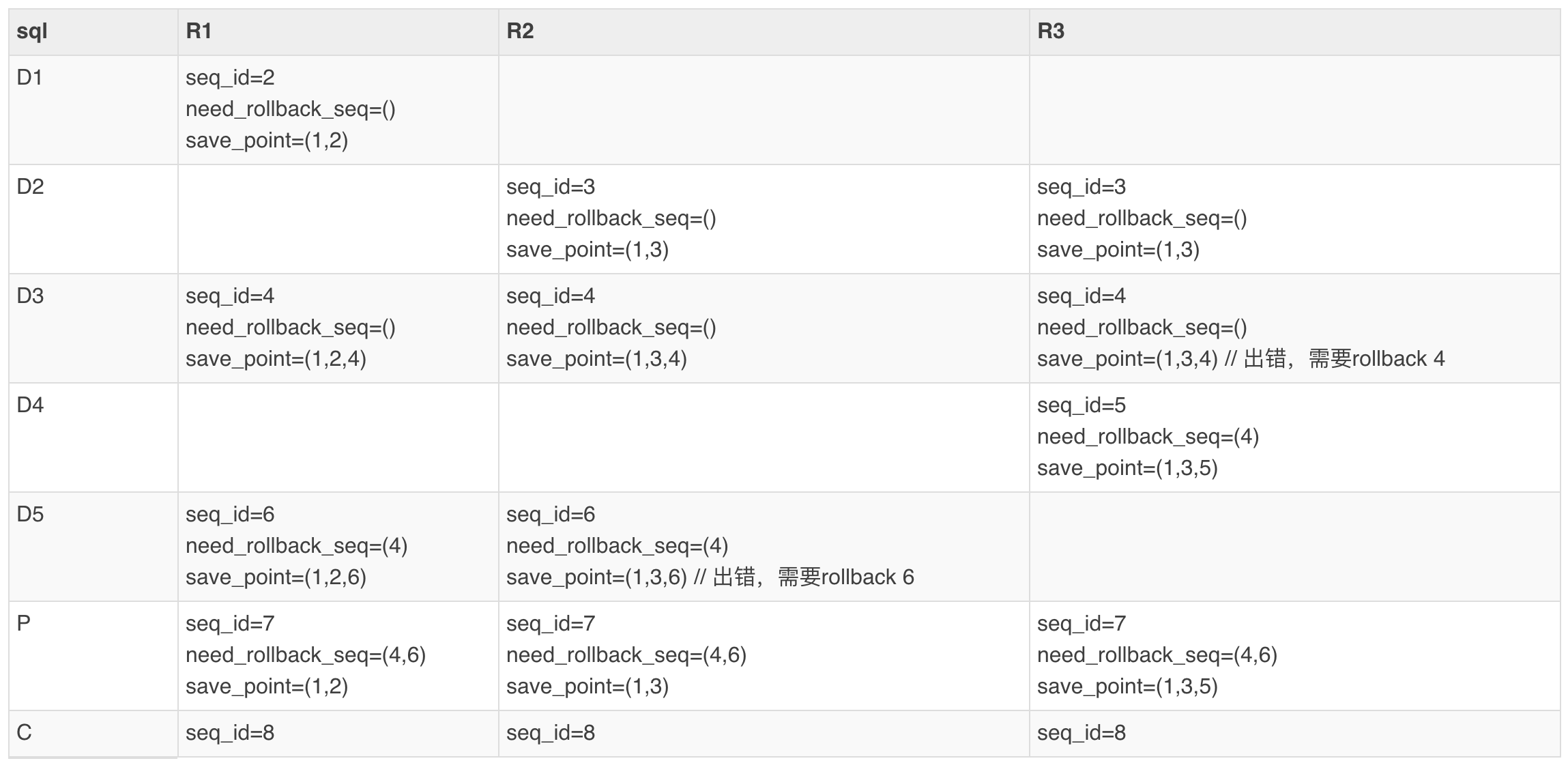
通过上面的步骤来实现局部语句的回滚,下面举例说明整个流程,假设多语句事务:
| sql | seq_id | 涉及的region | 执行结果 |
|---|---|---|---|
| B | 1 | R1,R2,R3 | |
| D1 | 2 | R1 | 成功 |
| D2 | 3 | R2,R3 | 成功 |
| D3 | 4 | R1,R2,R3 | R3失败,整条语句需要回滚 |
| D4 | 5 | R3 | 成功 |
| D5 | 6 | R1,R2 | R2失败,整条语句需要回滚 |
| P | 7 | R1,R2,R3 | 成功 |
| C | 8 | R1,R2,R3 | 成功 |
整个_save_point_seq的变化如下表所示:
两阶段提交协议的缺点是在整个交互过程中,所有节点都处于阻塞状态,RocksDB的Pessimistic事务在未提交之前key都处于锁定状态。
当协调者发生故障后,参与者会一直阻塞下去,更严重的是在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求,导致数据不一致。
本节将介绍BiakalDB如何处理阻塞、协调者单点以及数据不一致的问题。
BaikalDB充当着两阶段提交的协调者角色,如果事务执行过程中BaikalDB宕机可能会对整个系统之后的操作产生影响,参与者将处于不确定状态,如图所示,不同参与者状态不一致了。
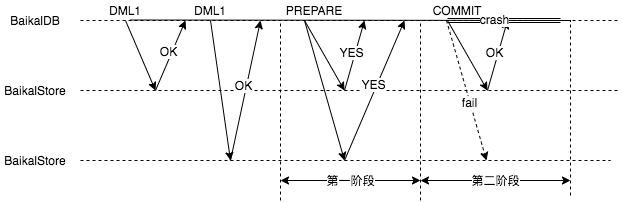
下面对不同阶段BaikalDB宕机可能产生的影响总结如下:
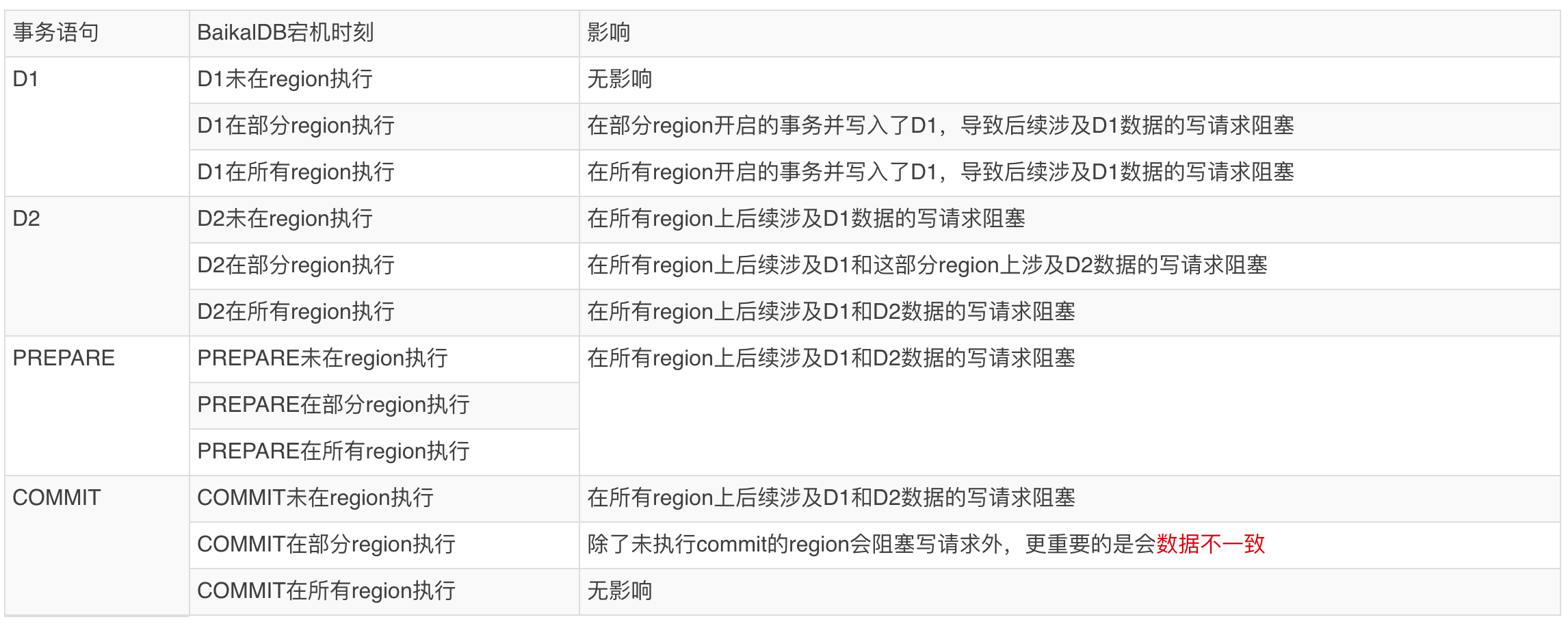
BaikalDB宕机可能导致事务残留,残留事务除了阻塞后续写请求外,如上表所示最坏的情况可能会导致数据不一致,这里要解决的问题有两个:
这里BaikalDB参考Percolator事务模型的机制,随机选取第一条DML指令的某一个region为primary region(sync point),在执行COMMIT/ROLLBACK的时候首先向primary region发送请求,保证primary region执行成功,再向其他region发送COMMIT/ROLLBACK,让primary region来充当事务协调者的角色,具体流程:
| 指令 | 序号seq_id | 涉及region_id |
|---|---|---|
| BEGIN | 1 | 1,2,3 |
| D1 | 2 | 1 |
| D2 | 3 | 2 |
| D3 | 4 | 1,2,3 |
| D4 | 5 | 3 |
| PREPARE | 6 | 1,2,3 |
| COMMIT | 7 | 1,2,3 |
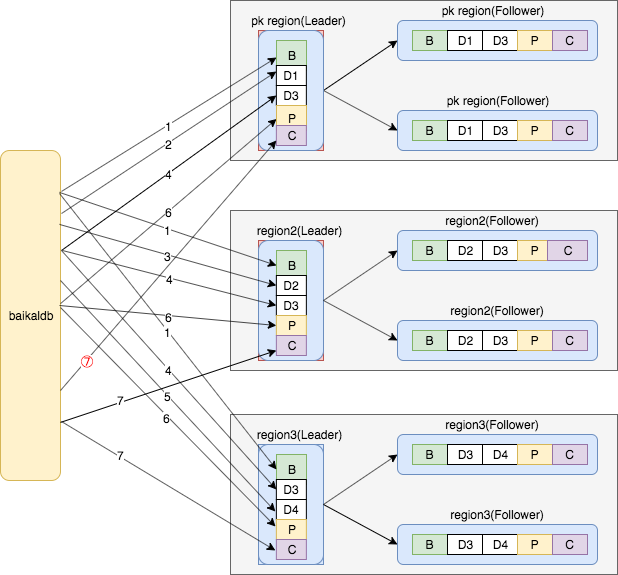
说明:
primary region事务执行完commit/rollback后,second region如果一定时间阈值未收到commit/rollback则通过反查primary region来判断事务是commit还是rollback,这里primary region事务的commit/rollback状态需要记录,我们只对rollback在RocksDB中记录信息,second region反查时首先查看事务是否还存在,如果存在则不做操作,如果不存在再读取RocksDB判断是否有事务的rollback记录,如果有就执行rollback,如果没有就执行commit,这样保证了整个事务commit/rollback的一致性。 而对于残留的事务,primary region超过一定时间阈值会主动rollback,其他的region则通过反查的方式最终保证事务被及时清除。 通过这样的方式解决事务的阻塞、协调者单点以及数据不一致的问题。
BaikalStore作为存储层,也是2PC的参与者,需要保证高可用。BaikalStore用 region 组织,三个 Store 的 三个region形成一个 Raft group 实现三副本实现高可用,Raft库使用的braft。BaikalStore要考虑在PREPARE/COMMIT前后宕机如何恢复,为此我们需要记录相关的元数据信息,再利用Raft的日志(把Raft日志作为redo log)来恢复事务状态,相关元信息包括:
| 元信息记录 | 说明 |
|---|---|
| write_meta_before_prepared | 在执行RocksDB的prepare之前记录prepare时Raft的log_index+txn_id |
| write_pre_commit | 在执行RocksDB的commit/rollback之前记录Raft的log_index+txn_id |
| write_meta_after_commit | 在执行RocksDB的commit/rollback之后记录Raft的log_index,同时删除write_pre_commit和write_meta_before_prepared记录的Raft的log_index+txn_id |
BaikalStore可能得宕机时刻如下图所示,下面说明在不同时刻宕机重启事务的恢复流程。
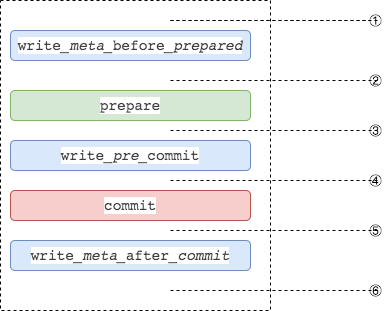
当Raft发生Leadership Transfer时,如果此时事务已经执行了Prepare命令,说明整个事务已经通过Raft复制给follower,无需特殊处理。否则需要将Old Leader上的事务回滚,并在收到BaikalDB发送的下一条事务命令时,在New Leader上利用BaikalDB的重试机制补发缺失的命令,从头开始执行事务。
事务功能上线运行的过程中,我们发现了很多可以优化的地方,本节简单介绍两点。
如前所述,事务执行流程为,先在leader执行,并将指令缓存在leader,待prepare时通过Raft复制将所以指令复制给follower。因为leader已经在Raft外部执行完成,在日志应用(on_apply)时leader不再执行,而follower从begin到prepare所有指令全部在on_apply中执行,根据Raft语义,on_apply为串行执行,所以导致follower执行缓慢效率低。优化为leader执行一条指令成功后立即通过raft复制给follower执行,提高follower的并发度。
实现要点:
只读事务在执行commit时按照当前的实现,PREPARE和CPOMMIT会两次raft日志,但这是没有必要的,只需要在Leader上进行判断,对只读事务,直接执行prepare和commit即可,更进一步,对只读事务将prepare和commit转化为rollback处理,RocksDB事务执行rollback性能更好。
本文从实现原理、宕机恢复等方面介绍了BaikalDB分布式事务的实现,支持单语句事务(autocommit=1模式下的DML形成单语句事务)和使用显式控制命令的多语句事务。 binlog,MVCC,子查询等功能还正在不断完善中,如果你有兴趣,欢迎加入github.com/baidu/BaikalDB。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273