OceanBase于2020年3月在阿里云上完成了商业化,在公有云上正式对外开放。同步上线的还有相关的生态产品,包括集群管控(OCP:OceanBase Cloud Platform),诊断(OTA:OceanBase Tunning Advisor),迁移服务(OMS:OceanBase Migration Service)及开发者中心(ODC:OceanBase Developer Center)。
一、公共云OceanBase服务端部署
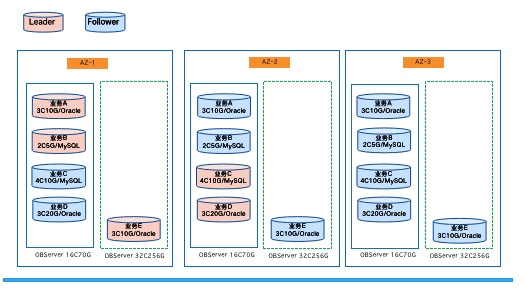
蚂蚁金服自研分布式关系数据库OceanBase是一款纯原生的分布式关系数据库,在代码层面完全可控。公共云OceanBase产品(图1-1)是基于三份副本3AZ部署,通过paxos协议保证了多节点间的数据一致性,单点故障甚至单AZ故障,也可以保障业务连续性,RPO=0,RTO<30s,做到机房级高可用,未来还将推出三地五中心的产品形态,具备城市级高可用切换能力。同时,OceanBase的资源管理具有非常高的灵活性。它支持多租户部署,在OceanBase集群里面,我们可以按需分配实例,并且可以进行在线资源扩容或者缩容。
从安全性和可用性来讲,OceanBase是非常适合金融业务场景的。因为监管需求,金融业务场景(像银行业务等)不能上公有云。但是这并不影响类金融业务,像保险、基金等。
![1b0fb1d077710e0f09feeb80017be39a7d3acc40.png]()
图1-1
二、OceanBase架构原理
与大多数分布式系统不同的地方在于,OceanBase这个系统没有单独的总控服务器或者总控进程。分布式系统一般包含一个单独的总控进程,用来做全局管理、负载均衡,等等。OceanBase没有单独的总控进程,它的总控是一个服务,叫做RootService,集成在ObServer里面。OceanBase会从所有的工作机中动态地选出一台ObServer执行总控服务,另外,当总控服务所在的ObServer出现故障时,系统会自动选举一台新的ObServer提供总控服务。这种方式的好处在于简化部署,虽然实现很复杂,但是大大降低了使用成本。
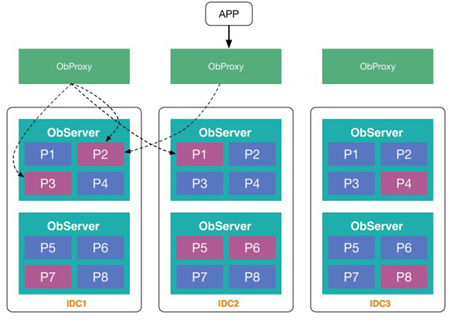
OceanBase通过分区能力做到无限水平扩展(图1-2)。OceanBase跟传统数据库分区不一样的地方,在于传统数据库所有的分区只能在一台服务器,而OceanBase每个分区可以分布到不同的服务器,每个分区都有三副本。从数据模型的角度看,OceanBase可以被认为是传统的数据库分区表在多机的实现。它可以把不同的用户生成的数据全部融合到统一的表里面。无论这些分区在多台服务器上是如何分布的,整个系统对用户呈现的都是一张表,后台实现对用户完全透明。OceanBase在用户入口使用了OBProxy,它是一个访问代理,它会根据用户请求的数据将请求转发到合适的服务器。ObProxy的最大的亮点在于性能突出,它可以在非常一般的普通服务器上达到每秒百万级的处理能力。
![e9cfe487035d464ae332e817717a855cf391f4dd.jpeg]()
图1-2
如图1-2,多个分区分布在多台服务器上。由于多个分区跨ObServer,内部通过两阶段提交实现分布式事务。当然,两阶段提交协议性能较差,OceanBase内部做了很多优化。它提出了分区组的概念,会把多个经常一起访问,或者说访问模式比较类似的不同表的分区放到一个分区组里面。OB后台会将同一个分区组尽可能调度到一台服务器上,避免分布式事务。同时优化了两阶段提交协议的内部实现。两阶段提交协议涉及多台服务器,协议中包含协调者、参与者这两种角色,参与者维护了每台服务器的局部状态,协调者维护了分布式事务的全局状态。常见的做法是对协调者记日志来持久化分布式事务的全局状态,而OceanBase的做法是,如果出现故障,通过查询所有参与者的状态来恢复分布式事务。这种方式节省了协调者日志,而且只要所有的参与者都预提交成功,整个事务就成功了,不需要等协调者写日志就可以应答客户端。
三、OceanBase存储架构
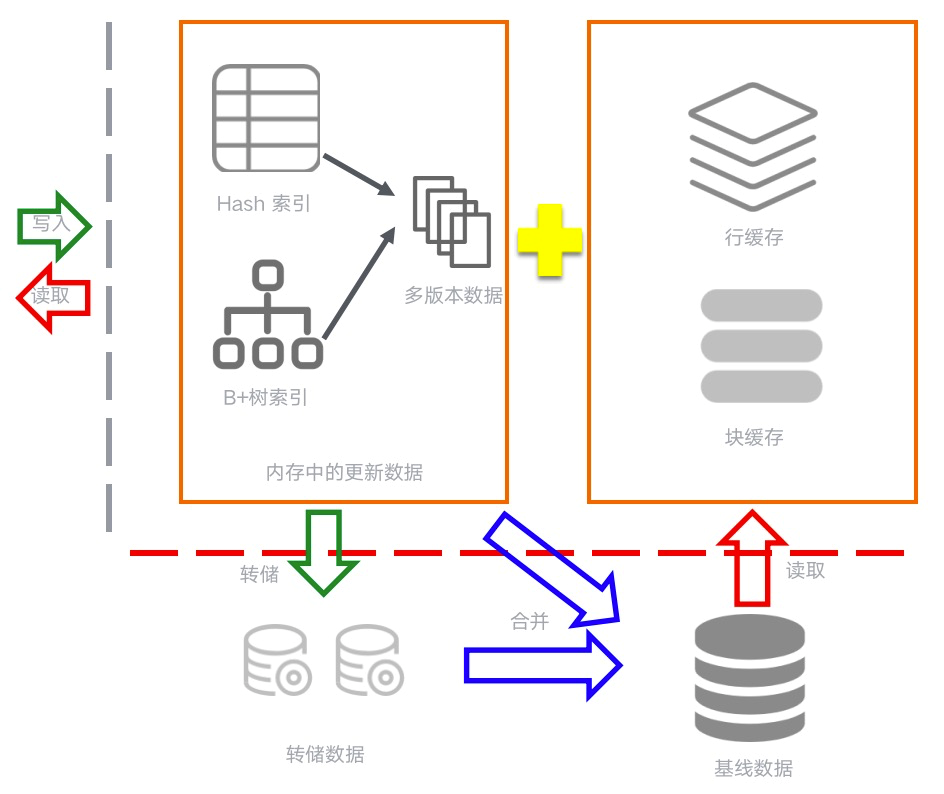
OceanBase是一个shared noting的架构,每一个OBServer都有独立的存储引擎,将数据保存在本地,这样可以满足容灾场景下的数据连续服务。OceanBase采用LSM-Tree的架构来设计Cache和数据存储,数据首先被写入内存中的MemTable当中,这样最高频和最活跃的数据都在内存访问,极大的提升了热数据的访问效率。当MemTable的写入到达一个阈值的时候,MemTable中的数据会做一次合并,将数据转到磁盘的SSTable中。在很多基于LSM Tree的存储系统中,为了解决写入的性能问题,通常会将SSTable分为多层,当一层的SSTable个数或者大小达到某个阈值时,合并入下一层SSTable。
![46df4a128570be7e592603db4dd1bf41adf004b9.png]()
图1-3
在OceanBase内部,也会有很多种不同类型的Cache,有类似于Oracle和MySQL的buffer。cache用于缓存sstable数据的块缓存,还有用于缓存数据行的行缓存、日志缓存、位置缓存等等。基线数据缓存到内存中提升查询性能。对于不同租户,每个租户都有自己独立的缓存,可以配置对应租户内存使用的上下限,做到租户隔离或者抢占超卖,适用于不同需求的场景。
在存储成本上,OceanBase采用了多种数据压缩算法,例如lz4、zstd等。OceanBase会对数据集做两层瘦身,第一层是encoding,会使用字典、RLE等算法对数据做瘦身,第二层是通用压缩,使用lz4等压缩算法对encoding之后的数据再做一次瘦身。在zstd算法下,相较传统MySQL Innodb的压缩,可以做到相同数据集只是用MySQL的1/3的存储,帮助用户极大的节省存储成本。更重要的是,传统数据库定长页的设计压缩不可避免的会造成存储的空洞,压缩效率会受影响,而OB这样的LSM-tree架构的存储系统,压缩对数据写入性能是0影响的。
四、OceanBase SQL引擎
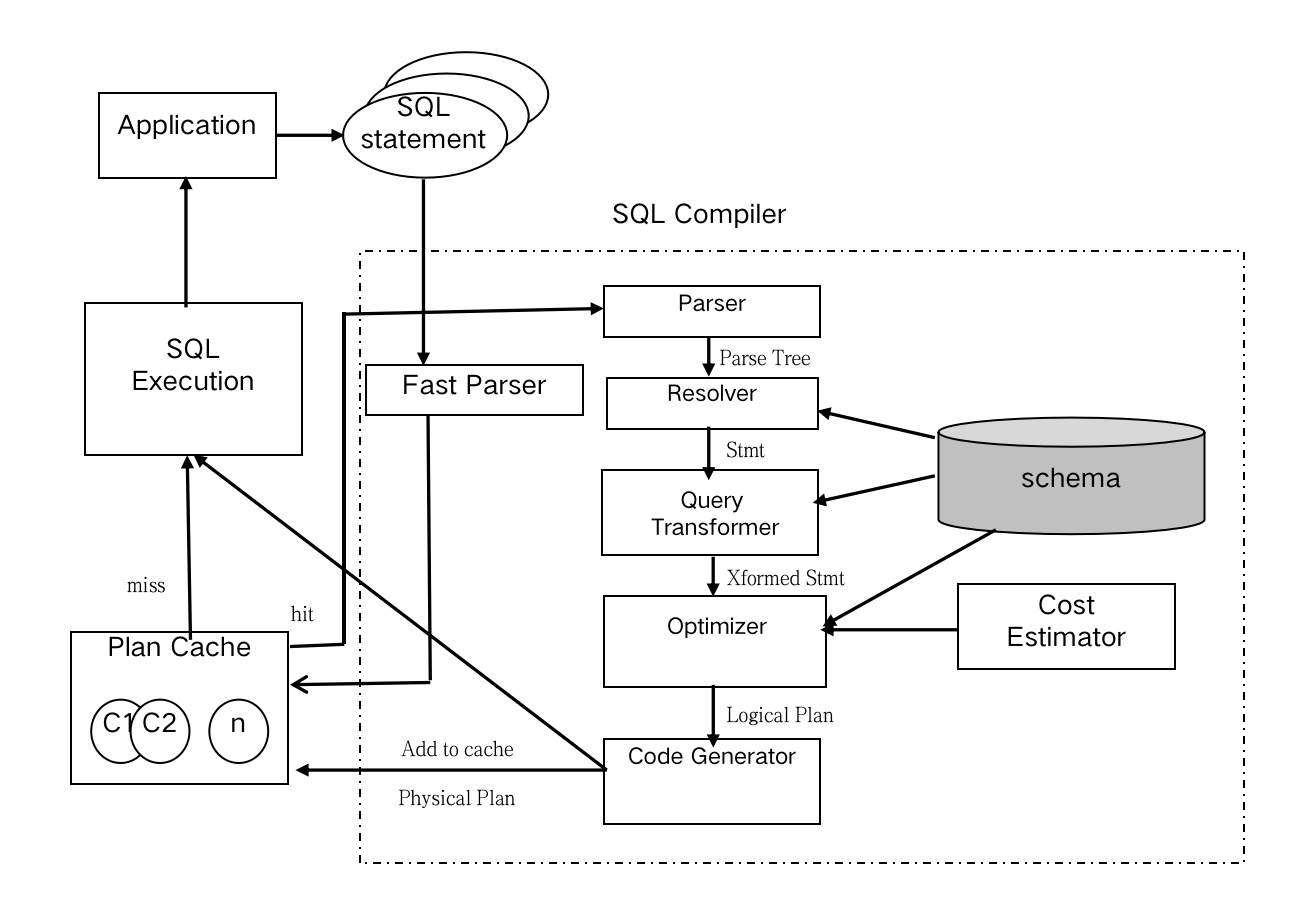
OceanBase的租户支持Oracle和MySQL两种SQL兼容性,首先相较于传统MySQL,OB除了硬解析以外,与Oracle一样支持软解析,同时解析器还支持SQL参数化以及绑定变量,如图1-4所示,解析器将解析后的SQL模板以及执行计划放在plan cache中,已经存在plan cache中的SQL就可以省去每一次硬解析带来的开销,提升了SQL运行效率。
![dbebe03c0400337cc97897441b5c3561a949bdce.png]()
图1-4
基于LSM-Tree的存储架构,OB设计了一套独特的代价模型,引入统计信息,拥有了基于代码模型的优化器,这意味着OB可以根据统计信息,计算每条SQL的最优访问路径,给出最优的执行计划。同时OB也可以根据用户的需求,在线动态绑定固化执行计划,针对应急、效率的场景可以很好的提供便捷性。在执行器方面,OB不仅仅支持Nest Loop的Join方式,同时也支持了Hash Join、Merge Join,针对大表join提高效率。还支持并发执行、分布式SQL等等。
五、OceanBase的AACID特性
OceanBase是一个分布式的关系型数据库,符合ACID原则。在传统ACID的基础上,OceanBase特别强调多了一个A,可用性。基于Paxos协议的多副本日志复制,可以在单点故障的情况下提供无数据丢失的业务连续性。在一致性上,OB采用MVCC的多版本一致读,当数据块被更新时,OB会新开启一个数据块并带上数据版本于事务id,只有事务内的SQL可以访问到,未提交的数据不会被其他会话访问当。隔离性上,OB支持Oracle的提交读和串行化两种事务隔离级别,对Oracle做到了很好的兼容。在持久性上,和大多数传统数据库一样的日志先行,事务提交的时候先保证redo日志的写成功后才写数据,出现异常情况时不会存在数据二义性。
在数据安全上,OB也做了多种保护措施,最大程度的保障数据安全。比如回收站机制,在租户级别设置回收站的开关,当回收站打开的状态下,drop table、truncate的情况下数据不会被立马删除,而是进入了回收站,在回收站保留有效期内,都可以通过flashback的命令将表恢复原状,极大程度上避免了误操作带来的一些风险。
针对delete、update这种数据修改类的操作,OB支持基于位点的Flashback Query来将数据恢复到某一个时间点,这样针对业务或者运维过程中的错误SQL执行,具备数据找回能力。同时在Oracle租户下,还支持as of timestam/scn这种查询。
2019年10月,OceanBase斩获TPC-C性能测试榜首。创造了tpmc6088万的世界记录,是前任榜首Oracle的2倍。同年十一月份,在支付宝的双十一大促中又创造了6100万笔/秒的支付峰值,再次打破世界记录。经过多次极端业务的考验,OceanBase证明,在性能、可靠性、可用性上,分布式数据库是可以和集中式数据库媲美的。传统的商业数据库,如oracle、SQL server、DB2都依赖高端的硬件设备(小机,存储,还有光纤网络),但是OceanBase只需要普通的PC服务器,SSD盘、万兆网络就行。而且它还具有高存储压缩率。OceanBase上云后,目前除了数据库本身是按规格收费、迁移服务按小时收费外,其它管理平台(OCP、ODC、OTA)是免费的。通过OCP可以方便地管理集群、租户、数据库。用户,监控租户和节点的性能。通过ODC可以方便地管理和维护数据库对象(表/视图/函数/存储过程等)。使用其SQLConsole可以便捷地操作数据库。通过OTA,可以及时发现当前业务库存在问题的SQL,提供优化建议,绑定执行计划。使用这些平台可以使运维操作白屏化,降低了运维难度。
未来,OceanBase将会根据用户需求提供更多实用、高效的特性,同时周边生态产品的功能也会越来越完善,敬请期待。
免费看直播并有好礼相送:https://yq.aliyun.com/live/2301
100%自研数据库OceanBase正式对外开放,欢迎前来体验: https://www.aliyun.com/database/oceanbasept