本文来自 PerfMa社区,欢迎关注公众号 ;链接: https://club.perfma.com/article/150614
概述
广义的堆外内存
说到堆外内存,那大家肯定想到堆内内存,这也是我们大家接触最多的,我们在jvm参数里通常设置-Xmx来指定我们的堆的最大值,不过这还不是我们理解的Java堆,-Xmx的值是新生代和老生代的和的最大值,我们在jvm参数里通常还会加一个参数-XX:MaxPermSize来指定持久代的最大值,那么我们认识的Java堆的最大值其实是-Xmx和-XX:MaxPermSize的总和,在分代算法下,新生代,老生代和持久代是连续的虚拟地址,因为它们是一起分配的,那么剩下的都可以认为是堆外内存(广义的)了,这些包括了jvm本身在运行过程中分配的内存,codecache,jni里分配的内存,DirectByteBuffer分配的内存等等
狭义的堆外内存
而作为java开发者,我们常说的堆外内存溢出了,其实是狭义的堆外内存,这个主要是指java.nio.DirectByteBuffer在创建的时候分配内存,我们这篇文章里也主要是讲狭义的堆外内存,因为它和我们平时碰到的问题比较密切
JDK/JVM里DirectByteBuffer的实现
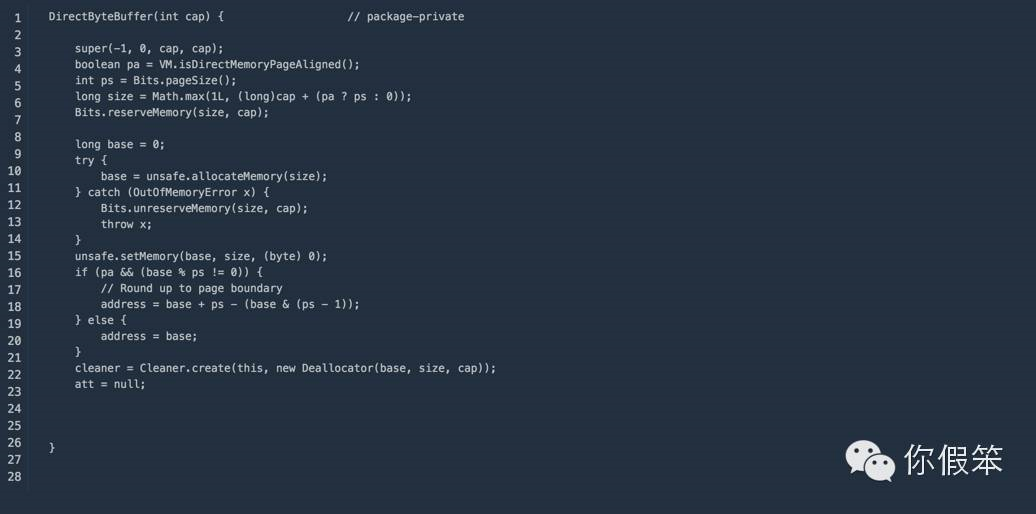
DirectByteBuffer通常用在通信过程中做缓冲池,在mina,netty等nio框架中屡见不鲜,先来看看JDK里的实现:
![image.png]()
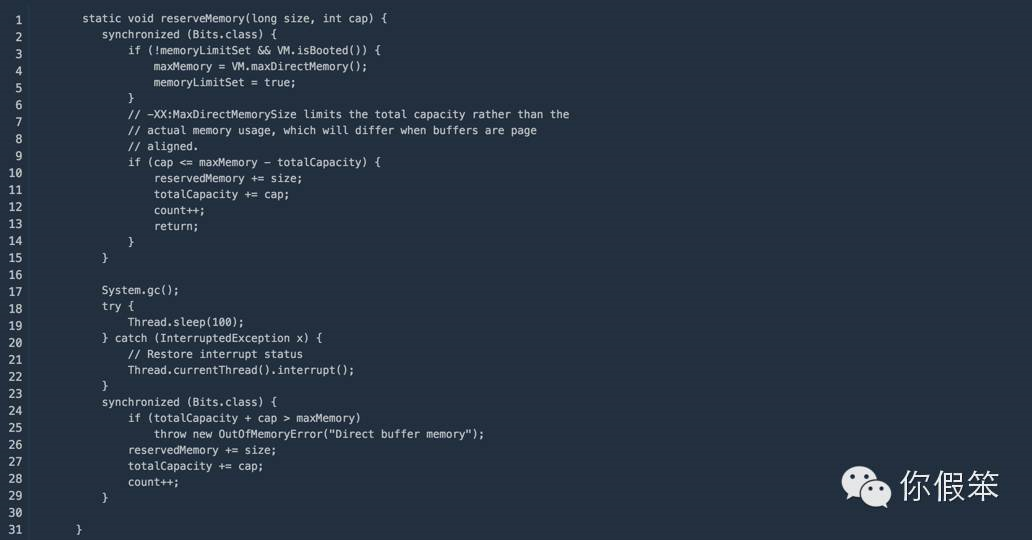
通过上面的构造函数我们知道,真正的内存分配是使用的Bits.reserveMemory方法
![image.png]()
通过上面的代码我们知道可以通过-XX:MaxDirectMemorySize来指定最大的堆外内存,那么我们首先引入两个问题
- 堆外内存默认是多大
- 为什么要主动调用System.gc()
堆外内存默认是多大
如果我们没有通过-XX:MaxDirectMemorySize来指定最大的堆外内存,那么默认的最大堆外内存是多少呢,我们还是通过代码来分析 上面的代码里我们看到调用了sun.misc.VM.maxDirectMemory()
![image.png]()
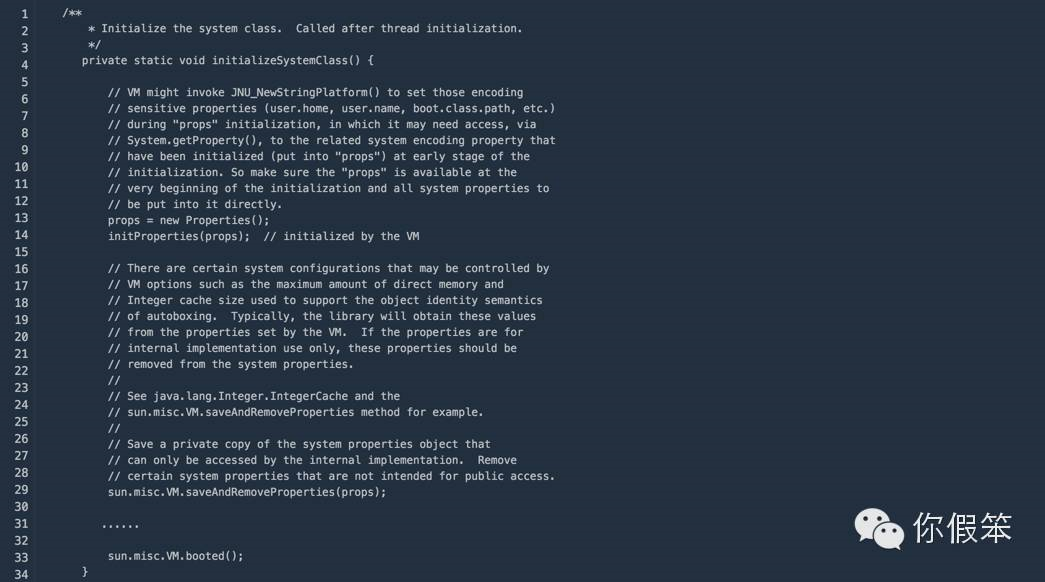
看到上面的代码之后是不是误以为默认的最大值是64M?其实不是的,说到这个值得从java.lang.System这个类的初始化说起
![image.png]()
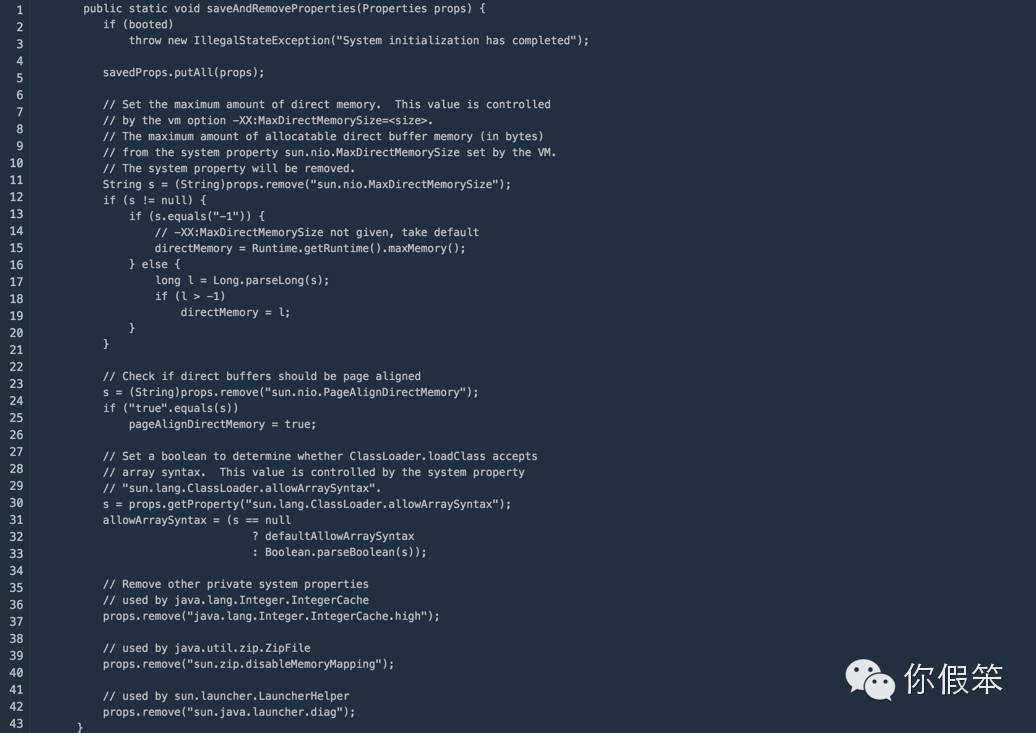
上面这个方法在jvm启动的时候对System这个类做初始化的时候执行的,因此执行时间非常早,我们看到里面调用了sun.misc.VM.saveAndRemoveProperties(props):
![image.png]()
如果我们通过-Dsun.nio.MaxDirectMemorySize指定了这个属性,只要它不等于-1,那效果和加了-XX:MaxDirectMemorySize一样的,如果两个参数都没指定,那么最大堆外内存的值来自于directMemory = Runtime.getRuntime().maxMemory(),这是一个native方法
![image.png]()
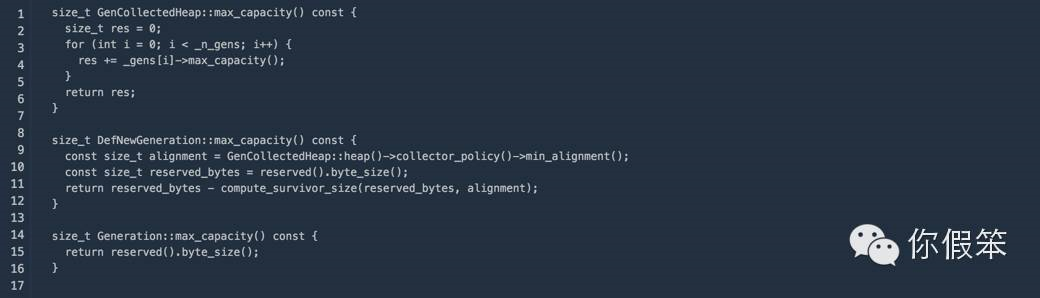
其中在我们使用CMS GC的情况下的实现如下,其实是新生代的最大值-一个survivor的大小+老生代的最大值,也就是我们设置的-Xmx的值里除去一个survivor的大小就是默认的堆外内存的大小了
![image.png]()
为什么要主动调用System.gc
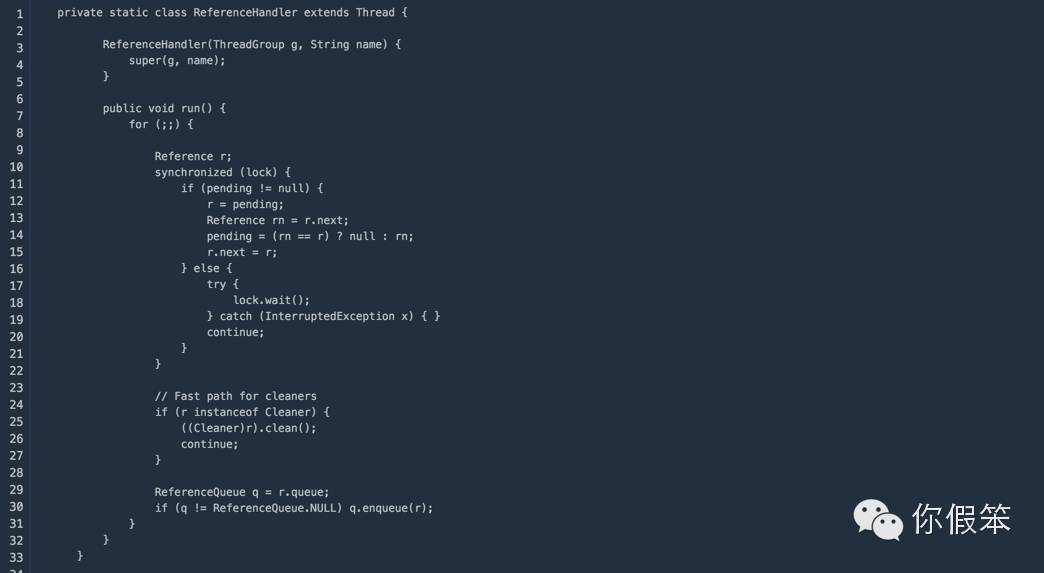
既然要调用System.gc,那肯定是想通过触发一次gc操作来回收堆外内存,不过我想先说的是堆外内存不会对gc造成什么影响(这里的System.gc除外),但是堆外内存的回收其实依赖于我们的gc机制,首先我们要知道在java层面和我们在堆外分配的这块内存关联的只有与之关联的DirectByteBuffer对象了,它记录了这块内存的基地址以及大小,那么既然和gc也有关,那就是gc能通过操作DirectByteBuffer对象来间接操作对应的堆外内存了。DirectByteBuffer对象在创建的时候关联了一个PhantomReference,说到PhantomReference它其实主要是用来跟踪对象何时被回收的,它不能影响gc决策,但是gc过程中如果发现某个对象除了只有PhantomReference引用它之外,并没有其他的地方引用它了,那将会把这个引用放到java.lang.ref.Reference.pending队列里,在gc完毕的时候通知ReferenceHandler这个守护线程去执行一些后置处理,而DirectByteBuffer关联的PhantomReference是PhantomReference的一个子类,在最终的处理里会通过Unsafe的free接口来释放DirectByteBuffer对应的堆外内存块 JDK里ReferenceHandler的实现:
![image.png]()
可见如果pending为空的时候,会通过lock.wait()一直等在那里,其中唤醒的动作是在jvm里做的,当gc完成之后会调用如下的方法VM_GC_Operation::doit_epilogue(),在方法末尾会调用lock的notify操作,至于pending队列什么时候将引用放进去的,其实是在gc的引用处理逻辑中放进去的,针对引用的处理后面可以专门写篇文章来介绍
![image.png]()
对于System.gc的实现,之前写了一篇文章来重点介绍,JVM源码分析之SystemGC完全解读,它会对新生代的老生代都会进行内存回收,这样会比较彻底地回收DirectByteBuffer对象以及他们关联的堆外内存,我们dump内存发现DirectByteBuffer对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为『冰山对象』,我们做ygc的时候会将新生代里的不可达的DirectByteBuffer对象及其堆外内存回收了,但是无法对old里的DirectByteBuffer对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题,如果有大量的DirectByteBuffer对象移到了old,但是又一直没有做cms gc或者full gc,而只进行ygc,那么我们的物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为heap明明剩余的内存还很多(前提是我们禁用了System.gc)。
为什么要使用堆外内存
DirectByteBuffer在创建的时候会通过Unsafe的native方法来直接使用malloc分配一块内存,这块内存是heap之外的,那么自然也不会对gc造成什么影响(System.gc除外),因为gc耗时的操作主要是操作heap之内的对象,对这块内存的操作也是直接通过Unsafe的native方法来操作的,相当于DirectByteBuffer仅仅是一个壳,还有我们通信过程中如果数据是在Heap里的,最终也还是会copy一份到堆外,然后再进行发送,所以为什么不直接使用堆外内存呢。对于需要频繁操作的内存,并且仅仅是临时存在一会的,都建议使用堆外内存,并且做成缓冲池,不断循环利用这块内存。
为什么不能大面积使用堆外内存
如果我们大面积使用堆外内存并且没有限制,那迟早会导致内存溢出,毕竟程序是跑在一台资源受限的机器上,因为这块内存的回收不是你直接能控制的,当然你可以通过别的一些途径,比如反射,直接使用Unsafe接口等,但是这些务必给你带来了一些烦恼,Java与生俱来的优势被你完全抛弃了—开发不需要关注内存的回收,由gc算法自动去实现。另外上面的gc机制与堆外内存的关系也说了,如果一直触发不了cms gc或者full gc,那么后果可能很严重。
推荐阅读
JVM菜鸟进阶高手之路十一(eden survivor分配问题)
Javassist实现JDK动态代理
![]()