前言
今天应该是推荐算法的最后一篇了,因子分解机deepFM。此处跳过了FM和FFM,因为我马上要去干别的了,所以直接用deepFM收尾吧。 先po两篇论文
看完这两篇论文,基本就能理解FM和DeepFM了。为了节省大家的时间我简述一下一些基本思想。
FM因子分解机
在FM出现以前大多使用SVM来做CTR预估,当然还有其他的比如SVD++,PITF,FPMC等,但是这些模型对稀疏矩阵显得捉襟见肘,而且参数规模很大。 那FM解决了什么问题:
- 更适合做稀疏矩阵的参数计算
- 减少了需要训练的参数规模,而且特征和参数数量是线性关系
- FM可以使用任何真实数据进行计算
其实FM出现主要解决了特征之间的交叉特征关系,此处省略了稀疏矩阵导致的w参数失效的模型直接说最终模型:
![]()
这里通过一个向量v的交叉来解决了稀疏矩阵导致的导致参数失效的问题。 那他参数的规模为什么小呢,接下来就是推导后面二次项部分:
![]()
从这里可以看出参数的复杂度是线性的O(kn)。
Keras对FM建模
这里是单纯的FM模型代码,这代码是借鉴别人的,我发现有一个问题就是,他最后repeat了二次项,这块我不是太明白,贴出来大家有兴趣可以一起讨论。
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1"
import keras.backend as K
from keras import activations
from keras.engine.topology import Layer, InputSpec
class FMLayer(Layer):
def __init__(self, output_dim,
factor_order,
activation=None,
**kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(FMLayer, self).__init__(**kwargs)
self.output_dim = output_dim
self.factor_order = factor_order
self.activation = activations.get(activation)
self.input_spec = InputSpec(ndim=2)
def build(self, input_shape):
assert len(input_shape) == 2
input_dim = input_shape[1]
self.input_spec = InputSpec(dtype=K.floatx(), shape=(None, input_dim))
self.w = self.add_weight(name='one',
shape=(input_dim, self.output_dim),
initializer='glorot_uniform',
trainable=True)
self.v = self.add_weight(name='two',
shape=(input_dim, self.factor_order),
initializer='glorot_uniform',
trainable=True)
self.b = self.add_weight(name='bias',
shape=(self.output_dim,),
initializer='zeros',
trainable=True)
super(FMLayer, self).build(input_shape)
def call(self, inputs, **kwargs):
X_square = K.square(inputs)
xv = K.square(K.dot(inputs, self.v))
xw = K.dot(inputs, self.w)
p = 0.5 * K.sum(xv - K.dot(X_square, K.square(self.v)), 1)
rp = K.repeat_elements(K.expand_dims(p, 1), self.output_dim, axis=1)
f = xw + rp + self.b
output = K.reshape(f, (-1, self.output_dim))
if self.activation is not None:
output = self.activation(output)
return output
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) == 2
return input_shape[0], self.output_dim
inp = Input(shape=(np.shape(x_train)[1],))
x = FMLayer(200, 100)(inp)
x = Dense(2, activation='sigmoid')(x)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=32,
epochs=10,
validation_data=(x_test, y_test))
运行结果
Train on 2998 samples, validate on 750 samples
Epoch 1/10
2998/2998 [==============================] - 2s 791us/step - loss: 0.0580 - accuracy: 0.9872 - val_loss: 0.7466 - val_accuracy: 0.8127
Epoch 2/10
2998/2998 [==============================] - 2s 683us/step - loss: 0.0650 - accuracy: 0.9893 - val_loss: 0.7845 - val_accuracy: 0.8067
Epoch 3/10
2998/2998 [==============================] - 2s 674us/step - loss: 0.0803 - accuracy: 0.9915 - val_loss: 0.8730 - val_accuracy: 0.7960
Epoch 4/10
2998/2998 [==============================] - 2s 681us/step - loss: 0.0362 - accuracy: 0.9943 - val_loss: 0.8771 - val_accuracy: 0.8013
Epoch 5/10
2998/2998 [==============================] - 2s 683us/step - loss: 0.0212 - accuracy: 0.9953 - val_loss: 0.9035 - val_accuracy: 0.8007
Epoch 6/10
2998/2998 [==============================] - 2s 721us/step - loss: 0.0188 - accuracy: 0.9965 - val_loss: 0.9295 - val_accuracy: 0.7993
Epoch 7/10
2998/2998 [==============================] - 2s 719us/step - loss: 0.0168 - accuracy: 0.9972 - val_loss: 0.9597 - val_accuracy: 0.8007
Epoch 8/10
2998/2998 [==============================] - 2s 693us/step - loss: 0.0150 - accuracy: 0.9973 - val_loss: 0.9851 - val_accuracy: 0.7993
Epoch 9/10
2998/2998 [==============================] - 2s 677us/step - loss: 0.0137 - accuracy: 0.9972 - val_loss: 1.0114 - val_accuracy: 0.7987
Epoch 10/10
2998/2998 [==============================] - 2s 684us/step - loss: 0.0126 - accuracy: 0.9977 - val_loss: 1.0361 - val_accuracy: 0.8000
FFM算法
上面FM算法也可以看出来只是有一组特征,但是现实生活中可能会有多组特征,例如论文中举例:
![]()
此处包含了用户,电影,用户打分的其他电影,时间信息等,所以光是一组特征的交叉还不够,可能涉及到不同组特征的交叉。所以FFM应运而生。此处不详细介绍,直接说deepFM。
DeepFM算法
DeepFM一样我就不详细介绍了,不明白的自己看上面论文,我直说重点。
DeepFM的优点
- 结合了FM和DNN,结合了高阶特征建模DNN和低阶特征建模FM
- DeepFM低阶部分和高阶部分共享了相同的特征,让计算更有效率
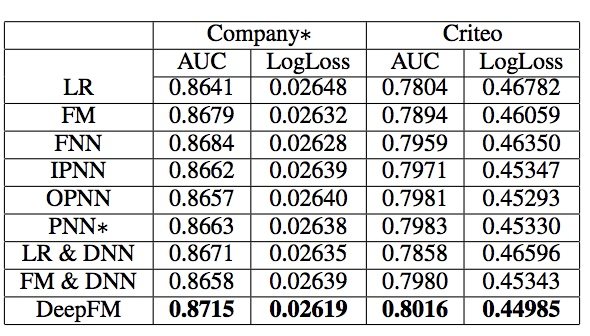
- DeepFM在CTR预测中效果最好
![]()
DeepFM网络结构
FM部分网络结构
![]()
FM部分就是把一次项和二次项结合到一起就好
# 一次项
fm_w_1 = Activation('linear')(K.dot(inputs, self.fm_w))
# 二次项
dot_latent = {}
dot_cat = []
for i in range(1, self.num_fields):
print(self.num_fields)
dot_latent[i] = {}
for f in self.field_combinations[i]:
print(len(self.field_combinations))
dot_latent[i][f] = Dot(axes=-1, normalize=False)([latent[i], latent[f]])
dot_cat.append(dot_latent[i][f])
print(dot_cat)
fm_w_2 = Concatenate()(dot_cat)
# Merge 一次和二次项得到FM
fm_w = Concatenate()([fm_w_1, fm_w_2])
DNN部分网络结构
![]() DNN部分比较简单
DNN部分比较简单
# 加俩隐藏层
deep1 = Activation('relu')(K.bias_add(K.dot(ConcatLatent,self.h1_w),self.h1_b))
deep2 = Activation('relu')(K.bias_add(K.dot(deep1, self.h2_w), self.h2_b))
整体网络结构
![]() 这里先做Embeding,然后给DNN和FM提供数据,代码如下:
这里先做Embeding,然后给DNN和FM提供数据,代码如下:
# 不同fields组合
for i in range(1, self.num_fields + 1):
sparse[i] = Lambda(lambda x: x[:, self.id_start[i]:self.id_stop[i]],
output_shape=((self.len_field[i],)))(inputTensor)
latent[i] = Activation('linear')(K.bias_add(K.dot(sparse[i],self.embed_w[i]),self.embed_b[i]))
# merge 不同 field
ConcatLatent = Concatenate()(list(latent.values()))
DeepFM代码
整体代码如下:
from keras.layers import Dense, Concatenate, Lambda, Add, Dot, Activation
from keras.engine.topology import Layer
from keras import backend as K
class DeepFMLayer(Layer):
def __init__(self, embeddin_size, field_len_group=None, **kwargs):
self.output_dim = 1
self.embedding_size = 10
self.input_spec = InputSpec(ndim=2)
self.field_count = len(field_len_group)
self.num_fields = len(field_len_group)
self.field_lengths = field_len_group
self.embed_w = {}
self.embed_b = {}
self.h1 = 10
self.h2 = 10
def start_stop_indices(field_lengths, num_fields):
len_field = {}
id_start = {}
id_stop = {}
len_input = 0
for i in range(1, num_fields + 1):
len_field[i] = field_lengths[i - 1]
id_start[i] = len_input
len_input += len_field[i]
id_stop[i] = len_input
return len_field, len_input, id_start, id_stop
self.len_field, self.len_input, self.id_start, self.id_stop = \
start_stop_indices(self.field_lengths,self.num_fields)
def Field_Combos(num_fields):
field_list = list(range(1, num_fields))
combo = {}
combo_count = 0
for idx, field in enumerate(field_list):
sub_list = list(range(field + 1, num_fields + 1))
combo_count += len(sub_list)
combo[field] = sub_list
return combo, combo_count
self.field_combinations, self.combo_count = Field_Combos(self.num_fields)
print(field_len_group)
print(self.field_combinations)
print(self.num_fields)
super(DeepFMLayer, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 2
total_embed_size = 0
self.input_spec = InputSpec(dtype=K.floatx(), shape=(None, input_shape[1]))
for i in range(1, self.num_fields + 1):
input_dim = self.len_field[i]
_name = "embed_W" + str(i)
self.embed_w[i] = self.add_weight(shape=(input_dim, self.embedding_size), initializer='glorot_uniform', name=_name)
_name = "embed_b" + str(i)
self.embed_b[i] = self.add_weight(shape=(self.embedding_size,), initializer='zeros', name=_name)
total_embed_size += self.embedding_size
self.fm_w = self.add_weight(name='fm_w', shape=(input_shape[1], 1), initializer='glorot_uniform', trainable=True)
self.h1_w = self.add_weight(shape=(total_embed_size, self.h1), initializer='glorot_uniform', name='h1_w')
self.h1_b = self.add_weight(shape=(self.h1,), initializer='zeros', name='h1_b')
self.h2_w = self.add_weight(shape=(self.h1, self.h2), initializer='glorot_uniform', name='h2_W')
self.h2_b = self.add_weight(shape=(self.h2,), initializer='zeros', name='h2_b')
self.w = self.add_weight(name='w', shape=(self.h2, 1), initializer='glorot_uniform', trainable=True)
self.b = self.add_weight(name='b', shape=(1,), initializer='zeros', trainable=True)
super(DeepFMLayer, self).build(input_shape)
def call(self, inputs):
latent = {}
sparse = {}
# 不同fields组合
for i in range(1, self.num_fields + 1):
sparse[i] = Lambda(lambda x: x[:, self.id_start[i]:self.id_stop[i]],
output_shape=((self.len_field[i],)))(inputTensor)
latent[i] = Activation('linear')(K.bias_add(K.dot(sparse[i],self.embed_w[i]),self.embed_b[i]))
# merge 不同 field
ConcatLatent = Concatenate()(list(latent.values()))
# 加俩隐藏层
deep1 = Activation('relu')(K.bias_add(K.dot(ConcatLatent,self.h1_w),self.h1_b))
deep2 = Activation('relu')(K.bias_add(K.dot(deep1, self.h2_w), self.h2_b))
# 一次项
fm_w_1 = Activation('linear')(K.dot(inputs, self.fm_w))
# 二次项
dot_latent = {}
dot_cat = []
for i in range(1, self.num_fields):
print(self.num_fields)
dot_latent[i] = {}
for f in self.field_combinations[i]:
print(len(self.field_combinations))
dot_latent[i][f] = Dot(axes=-1, normalize=False)([latent[i], latent[f]])
dot_cat.append(dot_latent[i][f])
print(dot_cat)
fm_w_2 = Concatenate()(dot_cat)
# Merge 一次和二次项得到FM
fm_w = Concatenate()([fm_w_1, fm_w_2])
fm = Lambda(lambda x: K.sum(x, axis=1, keepdims=True))(fm_w)
deep_wx = Activation('linear')(K.bias_add(K.dot(deep2, self.w),self.b))
print('build finish')
return Add()([fm, deep_wx])
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
inputTensor = Input(shape=(np.shape(x_train)[1],))
deepFM_out = DeepFMLayer(10, {0:10, 1:10, 2:np.shape(x_train)[1]-20})(inputTensor)
out = Dense(2, activation="sigmoid", trainable=True)(deepFM_out)
model = Model(inputTensor, out)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=32,
epochs=10,
validation_data=(x_test, y_test))
运行结果:
Train on 2998 samples, validate on 750 samples
Epoch 1/10
2998/2998 [==============================] - 1s 425us/step - loss: 0.6403 - accuracy: 0.6344 - val_loss: 0.5578 - val_accuracy: 0.7533
Epoch 2/10
2998/2998 [==============================] - 1s 226us/step - loss: 0.4451 - accuracy: 0.8721 - val_loss: 0.4727 - val_accuracy: 0.8240
Epoch 3/10
2998/2998 [==============================] - 1s 215us/step - loss: 0.2469 - accuracy: 0.9445 - val_loss: 0.5188 - val_accuracy: 0.8360
Epoch 4/10
2998/2998 [==============================] - 1s 200us/step - loss: 0.1319 - accuracy: 0.9678 - val_loss: 0.6488 - val_accuracy: 0.8233
Epoch 5/10
2998/2998 [==============================] - 1s 211us/step - loss: 0.0693 - accuracy: 0.9843 - val_loss: 0.7755 - val_accuracy: 0.8247
Epoch 6/10
2998/2998 [==============================] - 1s 225us/step - loss: 0.0392 - accuracy: 0.9932 - val_loss: 0.9234 - val_accuracy: 0.8187
Epoch 7/10
2998/2998 [==============================] - 1s 204us/step - loss: 0.0224 - accuracy: 0.9967 - val_loss: 1.0437 - val_accuracy: 0.8200
Epoch 8/10
2998/2998 [==============================] - 1s 190us/step - loss: 0.0163 - accuracy: 0.9972 - val_loss: 1.1618 - val_accuracy: 0.8173
Epoch 9/10
2998/2998 [==============================] - 1s 190us/step - loss: 0.0106 - accuracy: 0.9980 - val_loss: 1.2746 - val_accuracy: 0.8147
Epoch 10/10
2998/2998 [==============================] - 1s 213us/step - loss: 0.0083 - accuracy: 0.9987 - val_loss: 1.3395 - val_accuracy: 0.8167
Model: "model_19"
结论
从上面结果上看其实纯FM和DeepFM的在我的数据集上结果差不多,甚至跟LR也没太大差别,可能是因为我的数据集比较小。有问题可以一起讨论,希望大家好好看看论文。以上都是我的一些拙见,还望抛砖引玉。




 DNN部分比较简单
DNN部分比较简单 这里先做Embeding,然后给DNN和FM提供数据,代码如下:
这里先做Embeding,然后给DNN和FM提供数据,代码如下: