上一章聊到时序数据是什么样,物联网行业中的时序数据的特点:存量数据大、新增数据多(采集频率高、设备量多)。详情请见:
时序数据库 Apache-IoTDB 源码解析之前言(一)
打一波广告,欢迎大家访问 IoTDB 仓库,求一波 Star 。
这一章主要想聊一聊:
- 物联网行业的基本系统架构,及使用数据库遇到的需求与挑战
IoTDB 的功能特点及系统架构
车联网
因为本人是在做车联网行业,所以对这个行业的信息了解更深入一些,能够拿到一些更具体的数字来说明这个行业的具体情况。在上一篇文中的数据是出于自己的理解,为了让大家容易明白而编造的数据,但实际情况要复杂的多。
1. 系统架构
1.1 系统简介
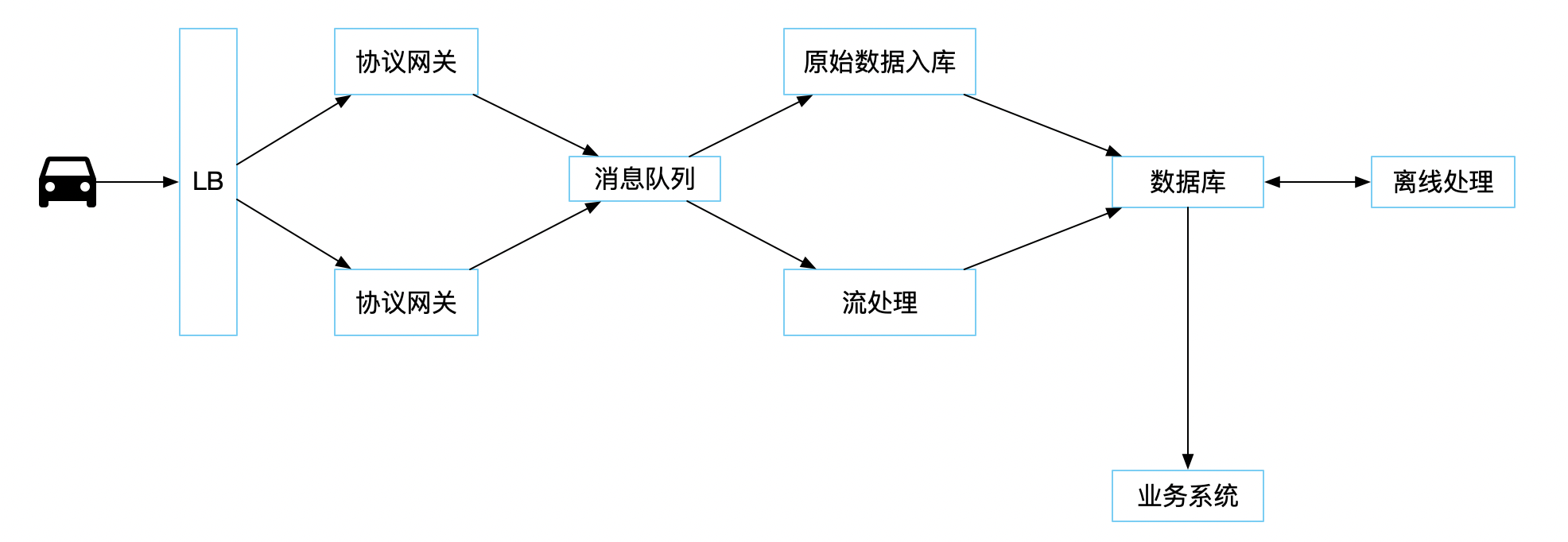
![车联网系统架构示意图]()
以上示意图可能非常简单,但我觉得足够表明一个整体架构。 当一台设备、一辆车连接到协议网关后,便开始了真正的收发数据。一般通信的方式都是基于 tcp,搞一段二进制协议,所以协议网关基本要做的工作就是完成对连接的管理、完成对数据的收发及编解码。
当数据完成编解码之后一般会发往消息队列当中,一般都是 Kafka 之中。用来解耦生产和消费两端,提供一层缓冲,无论消费服务是死是活还是速度慢,包治百病,甚至还能治未病。
数据发往消息队列的过程中,或之后花活儿就多起来了。但主要的我认为无非还是三种处理方式:
- 需要将原始数据保存入库,这里的原始数据包含二进制数据和解码后的二进制数据。
- 流处理或批处理数据,在数据落到硬盘之前将能够提前计算的数据全部预先计算出来,这样做的好处是将来查询的时候如果和预计算的模型匹配,那就能非常快的得到结果。
- 离线处理,这里的应用就太广泛了,一般来讲都是将耗时比较大的放置离线计算来做。但是这里要声明一点,离线计算依然是越快越好,不能因为他叫离线计算所以在设计或开发阶段就不关注时效。
1.2 数据质量
上一章提到了基本的数据质量,但实际工作中,往往质量会出现各种意想不到的数据,下面是工程中影响数据质量的几个比较大的问题:
- 数据丢失,不管是在采集,上报,数据流转环节,都可能会带来一定的数据丢失比例。
- 数据乱序,数据在打包、上报、流转等环节均可能出现乱序,尤其是在补传数据中。
- 数据重复,数据重复发送,尤其是在网络不好时。
- 数据本身不准确,这个最突出的地方就是在 GPS 数据中,经常出现飘点、噪点等等。
2. 数据库的挑战
2.1 数据项多
汽车里具有非常复杂的电路系统和传感器设备,我印象当中的粗略估算应该是有 120 项左右,并且这些数据项并不是车内数据的全部。随着自动驾驶的到来,汽车的传感器会越来越多,数据项就会更多。
如果按照传统的 Mysql 存储,那么由于行式存储,所以在取回数据时候就会非常影响效率,之后介绍到 IoTDB 的文件格式的时候再聊。
2.2 存量数据大
我们按照宝马汽车 2019 销售量估计,252 万辆,我们假定 4 年前就已经具备了联网模块那就是 1000 万辆汽车。按照每条数据 1K,每天采样上传 1 次,应该是 每天 9G 数据。但因为车不可能一直都点火开,所以要假设一个 30% 的在线率,那就是 3G 数据。
3 年大约就会存储 3TB 数据,可能你觉得 3T 数据对于时下最热的大数据来讲并不是一个非常庞大的数字,但如果整个数据里面不包含任何图片、音视频甚至都没有文字,全部是由整数、浮点数堆积起来的,那你可以试想一下这个数据库里面到底有多少数据,如果你一个不小心执行了 count(*) 你觉得会卡死不?
2.3 采集频率高
汽车不同于其他传感器的地方是,他是一个处在时刻运动当中的物体,如果需要做一些高阶的计算模型,比如说:碰撞检测、行驶轨迹纠偏等,那么相应的数据采集频率有可能要达到秒级。
当然我说完这句话,可能你感触并不是很深,但是结合前面说到的两点:120项数据、1000万辆车,将采集频率提高到 1 秒一采集,那么这个频率下,一天产生的数据大小就是 259T。这时候你找 DBA 说,哥们我们的需求要 1 天写入 259T 数据,我觉得反正我是没脸找人家,让产品去跟 DBA 聊吧。
2.4 大数据分析需求
现有时序数据库都无法支持大数据分析框架,都需要通过数据库的 Api 把数据从数据库往数据仓库导出后再存一份,数据量直接翻倍。 举个例子,我如果需要对 Mysql 中的数据进行 MapReduce 计算,那么只能是将数据通过 JDBC 接口导出到 Hbase 或 Hdfs 上,然后执行计算,可能你觉得这很正常,但按照上面提到的数据量,数据复制之后你公司里可能就需要每天支撑 500T 数据。
2.4 不同数据库遇到的问题
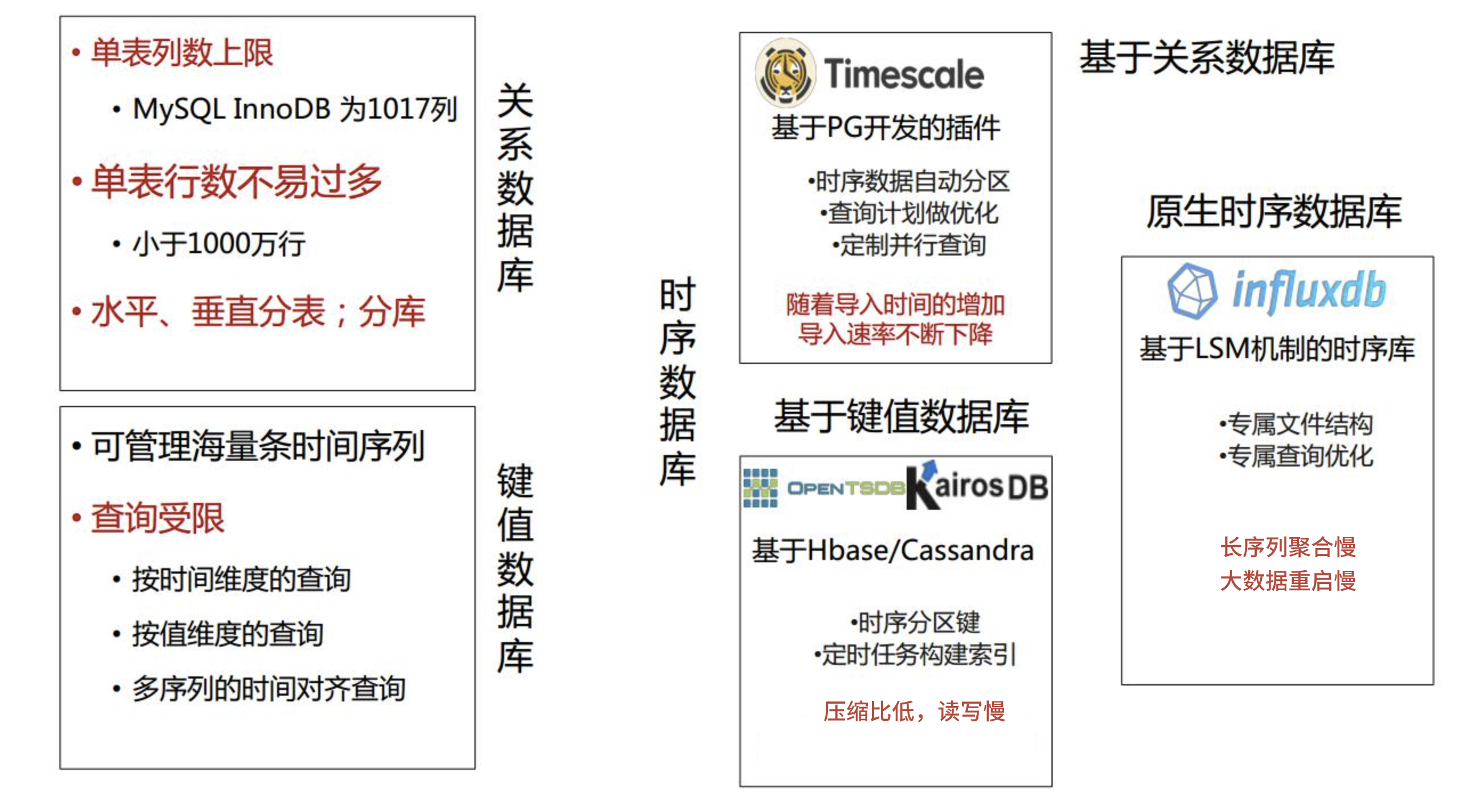
我们公司也采用了多种尝试,从开始的 MySql 到 MongoDB 再到 Hbase 等等,它们总存在这一点或多点的让你觉得就是不满足的地方,如下图:
![不同数据库对比图]()
IoTDB
到此为止,整体需求基本明确,作为一款物联网的时序数据库需要处理的问题:
- 高速写入
- 高效压缩
- 多维度查询,降采样、时序分割查询等
- 查询低延迟高效
- 提高数据质量,乱序、空值等
- 对接现有大数据生态
IoTDB 功能特点
![IoTDB功能特点]()
IoTDB 完成了上述问题中的几乎所有功能,而且可以灵活对接多生态,高性能优势等。那么 IoTDB 是如何完成这些优势项,如何做到?
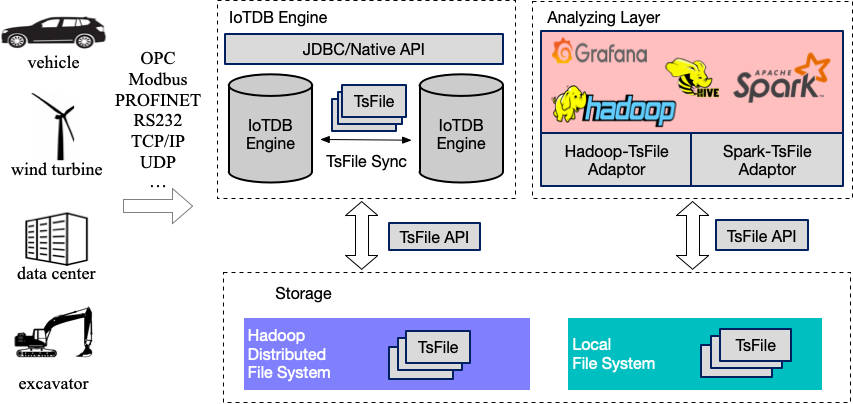
IoTDB 架构描述
![IoTDB架构图]()
对照上面的图,大致了解一下 IoTDB 的结构,逻辑上被分为 3 个大部分,其中:
- Engine 是完整的数据库进程,负责 sql 语句的解析,数据写入、查询、元数据管理等功能。
- Storage 是底层存储结构,类似于Mysql 的 idb 文件
- Analyzing Layer 是各种连接器,暂不涉及细节。
Engine 和 Storage 中主要包含:
- IoTDB Engine,也就是代码中的
Server 模块.
- Native API,他是高效写入的基石,代码中的
Session 模块
- JDBC,传统的 JDBC 连接调用方式,代码中的
JDBC 模块
- TsFile,这是整个数据库的一个特色所在,传统的数据库如果使用 Spark 做离线分析,或者 ETL 都需要通过数据库进程对外读取,而 IoTDB 可以直接迁移文件,省去了来回转换类型的开销。TsFile 提供了两种读写模式,一种基于 HDFS,一种基于本地文件。
聊到这里,我们基本介绍了行业内的特点,作为数据库需要解决的痛点,以及 IoTDB 在完成功能的同时所具有的自身的优势。同时还简单介绍了 IoTDB 的基础架构,朴实无华且枯燥。那么 TsFile 究竟是什么样的结构才能完成以上所介绍的高速写入、高压缩比、高速查询呢?Native API 又是什么?欢迎继续关注。。。