Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用
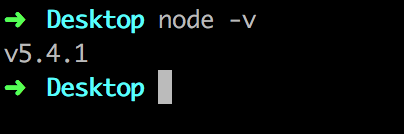
本地安装单机版本Flink 一般来说,线上都是集群模式,那么单机模式方便我们测试和学习。 环境要求 本地机器上需要有 Java 8 和 maven 环境,推荐在linux或者mac上开发Flink应用: 如果有 Java 8 环境,运行下面的命令会输出如下版本信息: 如果有 maven 环境,运行下面的命令会输出如下版本信息: 开发工具推荐使用 ItelliJ IDEA。 第一种方式 来这里https://flink.apache.org/ 看这里: 注意: An Apache Hadoop installation is not required to use Apache Flink. For users that use Flink without any Hadoop components, we recommend the release without bundled Hadoop libraries. 这是啥意思?这个意思就是说Flink可以不依赖Hadoop环境,如果说单机玩的话,下载一个only版本就行了。 第二种方式(不推荐) git clone https://github.com/apache/flink.git cd flink mvn clean package -DskipTests 然后进入编译好的Flink中去执行 bin/start-cluster.sh 其他乱七八糟的安装办法 比如 Mac用户可以用brew install apache-flink ,前提是安装过 brew这个mac下的工具. 启动Flink 我们先到Flink的目录下来:如下: $ flink-1.7.1 pwd /Users/wangzhiwu/Downloads/flink-1.7.1 执行命令: 接着就可以进入 web 页面(http://localhost:8081/) 查看 恭喜你,一个单机版的flink就跑起来了。 构建一个应用 当然了,我们可以用maven,一顿new,new出来一个过程,这里我们将使用 Flink Maven Archetype 来创建我们的项目结构和一些初始的默认依赖。在你的工作目录下,运行如下命令来创建项目: mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.7.2 \ -DgroupId=flink-project \ -DartifactId=flink-project \ -Dversion=0.1 \ -Dpackage=myflink \ -DinteractiveMode=false 这样一个工程就构建好了。 还有一个更加牛逼的办法,看这里: curl https://flink.apache.org/q/quickstart.sh | bash 直接在命令行执行上面的命令,结果如下图: 同样可以构建一个Flink工程,而且自带一些demo。 原理是什么?点一下它看看就明白了。https://flink.apache.org/q/quickstart.sh 编写一个入门级的WordCount // // Program // public static void main(String[] args) throws Exception { // set up the execution environment final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // get input data DataSet<String> text = env.fromElements( "To be, or not to be,--that is the question:--", "Whether 'tis nobler in the mind to suffer", "The slings and arrows of outrageous fortune", "Or to take arms against a sea of troubles," ); DataSet<Tuple2<String, Integer>> counts = // split up the lines in pairs (2-tuples) containing: (word,1) text.flatMap(new LineSplitter()) // group by the tuple field "0" and sum up tuple field "1" .groupBy(0) //(i,1) (am,1) (chinese,1) .sum(1); // execute and print result counts.print(); } // // User Functions // /** * Implements the string tokenizer that splits sentences into words as a user-defined * FlatMapFunction. The function takes a line (String) and splits it into * multiple pairs in the form of "(word,1)" (Tuple2<String, Integer>). */ public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // normalize and split the line String[] tokens = value.toLowerCase().split("\\W+"); // emit the pairs for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<String, Integer>(token, 1)); } } } } } 类似的例子,官方也有提供的,可以在这里下载:WordCount官方推荐 运行 本地右键运行: 提交到本地单机Flink上 进入工程目录,使用以下命令打包 mvn clean package -Dmaven.test.skip=true 然后,进入 flink 安装目录 bin 下执行以下命令提交程序: flink run -c org.myorg.laowang.WordCount /Users/wangzhiwu/WorkSpace/quickstart/target/quickstart-0.1.jar 分别制定main方法和jar包的地址。 在刚才的控制台中,可以看到: 我们刚才提交过的程序。 flink的log目录下有我们提交过的任务的日志: