学习docker on windows (1): 为什么要使用docker
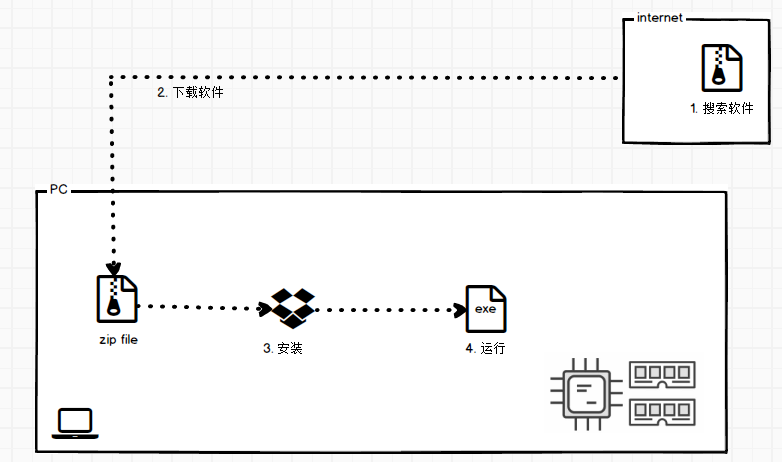
为什么要用Docker? 如果我们想使用某种pc软件, 那么在互联网上查找并安装软件的流程大致如下图: 那么这就有几个问题要弄清楚: 从哪里获得软件 App Store Linux的包管理 从某些网站直接下载 软件是否提供了相关信息和数据 例如流行度, 下载次数, 存在的bug, 上次的更新时间等等. 信任问题 下载软件的网站是否为官方网站 http 还是 https 代码 是否还可以下载 是否收费 第一个令人困扰的问题: 安装软件 软件是否支持我的操作系统/版本 是否支持我的设备的CPU架构 软件的格式 有些是从源码进行安装 有些是单独的exe文件 有的是exe+dlls 有时候是exe+dlls+依赖某些运行时 软件的安装方式 有自带的安装器 使用包管理工具安装 手动安装 软件的更新和卸载 自动更新? 软件的配置(对于新手来说可能这就是个噩梦) 从上面这些问题可以看出, 现在这个年代, 安装个软件真是个挺麻烦的事, 尤其是用于开发相关的软件, 有时候让人头疼. 第二个问题: 软件的运行 这方面可能会存在以下问题: 是否有详细的帮助文档 软件在哪运行 是否需要手动修改系统某些设置 是否需要设置环境变量PATH 如何开始, 如何结束 是否需要注册服务 如何注册服务 是否需要手动编写服务配置 是否需要许可 如何安装和运行软件的依赖项 如果没找到依赖项会怎么处理 循环的依赖项 安全性, 沙箱运行? 破坏性更新 系统更新是否对软件有破坏性影响 共享的库有更新 什么是容器 Docker不是虚拟机的替代者, docker不是虚拟化技术, 它更多是关于软件的运行. 什么是容器,它和虚拟机有什么区别? 首先介绍一下虚拟机: 虚拟机管理其把服务器的硬件资源(CPU,内存,硬盘,网络等)切割成多个虚拟的版本, 然后基于这些虚拟的硬件建立操作系统. 虚拟机建立的系统就像是正常的系统服务一样. 与虚拟机管理器不同, Docker或者其他的容器引擎切割的是操作系统的资源, 例如进程的命名空间, 网络栈, 存储栈等等: 每个容器都有PID为1的进程, 每个容器也都有自己的根文件系统(windows的C盘, linux的/). 所以docker可以称作是对针对操作系统的虚拟化操作, 它非常的轻量级. 可以举一些例子, 安装 sql server, mysql, mongodb, postgresql 等, 下载, 安装, 配置. 有的还是挺麻烦的. 下面看看使用docker会怎么样, 首先需要安装docker. 安装Docker Docker for windows 下载地址:https://store.docker.com/editions/community/docker-ce-desktop-windows 安装好docker后, 系统右下角托盘处会有docker的图标, 等到图标不再闪烁了, 说明docker已经启动成功了. 右键点击图标有Settings. 可以通过命令行看一下docker的状态: docker version 可以看到client是windows, server是linux(系统需要启用Hyper-V)虚拟机. 从Hyper-V管理器可以看到这个linux虚拟机: 使用Docker的例子: Postgresql 首先去https://hub.docker.com/这里查找需要使用的软件, 例如postgresql :https://hub.docker.com/_/postgres/ 从页面可以看到 postgres是docker官方认可的库. 页面的下方有使用说明等. 首先别忘了运行docker. 然后从docker hub下载postgres这个软件(应该叫image), 命令行执行: docker pull postgres 下载的过程有时候比较慢, 尤其是在国内 (如果速度实在太慢, 那么可以使用阿里云的容器镜像: https://dev.aliyun.com/search.html?spm=5176.1972343.0.1.340c5aaafU9rRJ): 等了一段时间之后, 下载完毕: 现在image已经下载了, 那么接下来就是需要通过某种方式运行这个image, 这就涉及到了container容器. 容器就像是一个已经安装好的软件, 它负责把这个image配置并安装好, 然后就可以运行这个安装好的postgresql了. 普通的软件安装好之后运行的是exe, 而这个运行的是容器, 容器里面是postgresql. 整个针对普通的软件安装的流程如下: docker run 命令 docker run 这个命令会一次性执行上面整个流程. 注: 所有的docker命令都是以docker开头, 也就是调用docker程序. docker run xxx表示让docker运行某个image. 然后客户端就会通过API调用告诉服务端(Daemon守护进程, 它实现了Docker Remote Api或者叫Docker Engine Api). Daemon首先看看本地有没有这个image, 然后没找到这个image, 然后daemon就会从docker hub 拉取下来这个image到本地, 然后使用这个image来创建新的container. 下面执行docker run postgres: 可以看到postgresql已经运行起来了. 其内容和单独安装的postgresql运行起来是一样的. 使用 docker ps 命令查看正在运行的容器: 然后按照官方文档的命令使用psql去连接postgresql: 可以看到, 进入到psql环境了. 这个postgres和传统方式安装的postgresql功能是一样的. 写个postgresql命令试试: docker exec 运行容器内的命令: 我电脑现在运行的是docker的linux容器, 所以可以使用这个命令运行一下linux的bash: 首先使用docker ps命令查看正在运行的容器, 然后使用docker exec -it 08 bash执行ID为08开头的容器内的bash命令. -it表示交互模式. 然后使用ps -e查看该容器内的linux的进程, 里面有bash, 刚才启动运行的psql, ps. 退出 在交互模式下使用exit命令进行退出: 停止运行容器则需要使用docker stop 容器ID这个命令: 以上这些就是使用docker的原因.......下面是我的关于ASP.NET Core Web API相关技术的公众号--草根专栏: