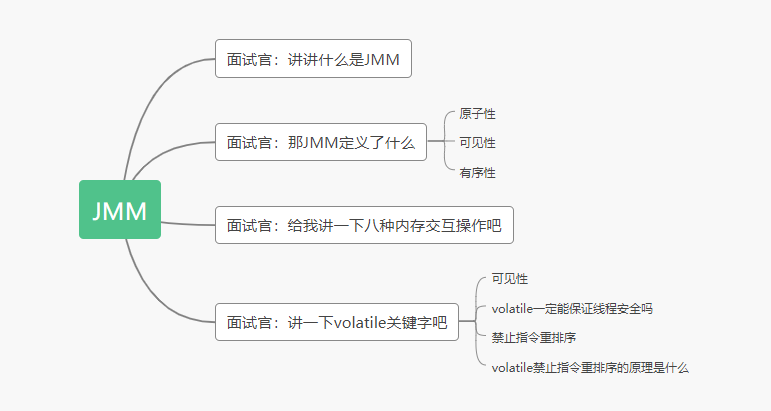
面试重点: 来说说Dubbo SPI 机制
SPI是什么 SPI是一种简称,全名叫 Service Provider Interface,Java本身提供了一套SPI机制,SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类,这样可以在运行时,动态为接口替换实现类,这也是很多框架组件实现扩展功能的一种手段。 而今天要说的Dubbo SPI机制和Java SPI还是有一点区别的,Dubbo 并未使用 Java 原生的 SPI 机制,而是对他进行了改进增强,进而可以很容易地对Dubbo进行功能上的扩展。 学东西得带着问题去学,我们先提几个问题,再接着看 1.什么是SPI(开头已经解释了) 2.Dubbo SPI和Java原生的有什么区别 3.两种实现应该如何写出来 Java SPI是如何实现的 先定义一个接口: publicinterfaceCar{voidstartUp();} 然后创建两个类,都实现这个Car接口 publicclassTruckimplementsCar{@OverridepublicvoidstartUp(){System.out.println("Thetruckstarted");}}publicclassTrainimplementsCar{@OverridepublicvoidstartUp(){System.out.println("Thetrainstarted");}} 然后在项目META-INF/services文件夹下创建一个名称为接口的全限定名,com.example.demo.spi.Car。 文件内容写上实现类的全限定名,如下: com.example.demo.spi.Traincom.example.demo.spi.Truck 最后写一个测试代码: publicclassJavaSPITest{@TestpublicvoidtestCar(){ServiceLoader<Car>serviceLoader=ServiceLoader.load(Car.class);serviceLoader.forEach(Car::startUp);}} 执行完的输出结果: ThetrainstartedThetruckstarted Dubbo SPI是如何实现的 Dubbo 使用的SPI并不是Java原生的,而是重新实现了一套,其主要逻辑都在ExtensionLoader类中,逻辑也不难,后面会稍带讲一下 看看使用,和Java的差不了太多,基于前面的例子来看下,接口类需要加上@SPI注解: @SPIpublicinterfaceCar{voidstartUp();} 实现类不需要改动 配置文件需要放在META-INF/dubbo下面,配置写法有些区别,直接看代码: train=com.example.demo.spi.Traintruck=com.example.demo.spi.Truck 最后就是测试类了,先看代码: publicclassJavaSPITest{@TestpublicvoidtestCar(){ExtensionLoader<Car>extensionLoader=ExtensionLoader.getExtensionLoader(Car.class);Carcar=extensionLoader.getExtension("train");car.startUp();}} 执行结果: Thetrainstarted Dubbo SPI中常用的注解 @SPI 标记为扩展接口 @Adaptive自适应拓展实现类标志 @Activate 自动激活条件的标记 总结一下两者区别: 使用上的区别Dubbo使用 ExtensionLoader而不是 ServiceLoader了,其主要逻辑都封装在这个类中 配置文件存放目录不一样,Java的在 META-INF/services,Dubbo在 META-INF/dubbo, META-INF/dubbo/internal Java SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,并且又用不上,会造成大量资源被浪费 Dubbo SPI 增加了对扩展点 IOC 和 AOP 的支持,一个扩展点可以直接 setter 注入其它扩展点 Java SPI加载过程失败,扩展点的名称是拿不到的。比如:JDK 标准的 ScriptEngine,getName() 获取脚本类型的名称,如果 RubyScriptEngine 因为所依赖的 jruby.jar 不存在,导致 RubyScriptEngine 类加载失败,这个失败原因是不会有任何提示的,当用户执行 ruby 脚本时,会报不支持 ruby,而不是真正失败的原因 前面的3个问题是不是已经能回答出来了?是不是非常简单 Dubbo SPI源码分析 Dubbo SPI使用上是通过ExtensionLoader的getExtensionLoader方法获取一个 ExtensionLoader 实例,然后再通过 ExtensionLoader 的 getExtension 方法获取拓展类对象。这其中,getExtensionLoader 方法用于从缓存中获取与拓展类对应的 ExtensionLoader,如果没有缓存,则创建一个新的实例,直接上代码: publicTgetExtension(Stringname){if(name==null||name.length()==0){thrownewIllegalArgumentException("Extensionname==null");}if("true".equals(name)){//获取默认的拓展实现类returngetDefaultExtension();}//用于持有目标对象Holder<Object>holder=cachedInstances.get(name);if(holder==null){cachedInstances.putIfAbsent(name,newHolder<Object>());holder=cachedInstances.get(name);}Objectinstance=holder.get();//DCLif(instance==null){synchronized(holder){instance=holder.get();if(instance==null){//创建扩展实例instance=createExtension(name);//设置实例到holder中holder.set(instance);}}}return(T)instance;} 上面这一段代码主要做的事情就是先检查缓存,缓存不存在创建扩展对象 接下来我们看看创建的过程: privateTcreateExtension(Stringname){//从配置文件中加载所有的扩展类,可得到“配置项名称”到“配置类”的映射关系表Class<?>clazz=getExtensionClasses().get(name);if(clazz==null){throwfindException(name);}try{Tinstance=(T)EXTENSION_INSTANCES.get(clazz);if(instance==null){//反射创建实例EXTENSION_INSTANCES.putIfAbsent(clazz,clazz.newInstance());instance=(T)EXTENSION_INSTANCES.get(clazz);}//向实例中注入依赖injectExtension(instance);Set<Class<?>>wrapperClasses=cachedWrapperClasses;if(wrapperClasses!=null&&!wrapperClasses.isEmpty()){//循环创建Wrapper实例for(Class<?>wrapperClass:wrapperClasses){//将当前 instance 作为参数传给 Wrapper 的构造方法,并通过反射创建 Wrapper 实例。//然后向Wrapper实例中注入依赖,最后将Wrapper实例再次赋值给instance变量instance=injectExtension((T)wrapperClass.getConstructor(type).newInstance(instance));}}returninstance;}catch(Throwablet){thrownewIllegalStateException("Extensioninstance(name:"+name+",class:"+type+")couldn'tbeinstantiated:"+t.getMessage(),t);}} 这段代码看着繁琐,其实也不难,一共只做了4件事情: 1.通过getExtensionClasses获取所有配置扩展类 2.反射创建对象 3.给扩展类注入依赖 4.将扩展类对象包裹在对应的Wrapper对象里面 我们在通过名称获取扩展类之前,首先需要根据配置文件解析出扩展类名称到扩展类的映射关系表,之后再根据扩展项名称从映射关系表中取出相应的拓展类即可。相关过程的代码如下: privateMap<String,Class<?>>getExtensionClasses(){//从缓存中获取已加载的拓展类Map<String,Class<?>>classes=cachedClasses.get();//DCLif(classes==null){synchronized(cachedClasses){classes=cachedClasses.get();if(classes==null){//加载扩展类classes=loadExtensionClasses();cachedClasses.set(classes);}}}returnclasses;} 这里也是先检查缓存,若缓存没有,则通过一次双重锁检查缓存,判空。此时如果 classes 仍为 null,则通过 loadExtensionClasses 加载拓展类。下面是 loadExtensionClasses 方法的代码 privateMap<String,Class<?>>loadExtensionClasses(){//获取SPI注解,这里的type变量是在调用getExtensionLoader方法时传入的finalSPIdefaultAnnotation=type.getAnnotation(SPI.class);if(defaultAnnotation!=null){Stringvalue=defaultAnnotation.value();if((value=value.trim()).length()>0){//对SPI注解内容进行切分String[]names=NAME_SEPARATOR.split(value);//检测SPI注解内容是否合法,不合法则抛出异常if(names.length>1){thrownewIllegalStateException("morethan1defaultextensionnameonextension...");}//设置默认名称,参考getDefaultExtension方法if(names.length==1){cachedDefaultName=names[0];}}}Map<String,Class<?>>extensionClasses=newHashMap<String,Class<?>>();//加载指定文件夹下的配置文件loadDirectory(extensionClasses,DUBBO_INTERNAL_DIRECTORY);loadDirectory(extensionClasses,DUBBO_DIRECTORY);loadDirectory(extensionClasses,SERVICES_DIRECTORY);returnextensionClasses;} loadExtensionClasses 方法总共做了两件事情,一是对 SPI 注解进行解析,二是调用 loadDirectory 方法加载指定文件夹配置文件。SPI 注解解析过程比较简单,无需多说。下面我们来看一下 loadDirectory 做了哪些事情 privatevoidloadDirectory(Map<String,Class<?>>extensionClasses,Stringdir){//fileName=文件夹路径+type全限定名StringfileName=dir+type.getName();try{Enumeration<java.net.URL>urls;ClassLoaderclassLoader=findClassLoader();//根据文件名加载所有的同名文件if(classLoader!=null){urls=classLoader.getResources(fileName);}else{urls=ClassLoader.getSystemResources(fileName);}if(urls!=null){while(urls.hasMoreElements()){java.net.URLresourceURL=urls.nextElement();//加载资源loadResource(extensionClasses,classLoader,resourceURL);}}}catch(Throwablet){logger.error("Exceptionoccurredwhenloadingextensionclass(interface:"+type+",descriptionfile:"+fileName+").",t);}} loadDirectory 方法先通过 classLoader 获取所有资源链接,然后再通过 loadResource 方法加载资源。我们继续跟下去,看一下 loadResource 方法的实现 privatevoidloadResource(Map<String,Class<?>>extensionClasses,ClassLoaderclassLoader,java.net.URLresourceURL){try{BufferedReaderreader=newBufferedReader(newInputStreamReader(resourceURL.openStream(),"utf-8"));try{Stringline;//按行读取配置内容while((line=reader.readLine())!=null){//定位#字符finalintci=line.indexOf('#');if(ci>=0){//截取#之前的字符串,#之后的内容为注释,需要忽略line=line.substring(0,ci);}line=line.trim();if(line.length()>0){try{Stringname=null;inti=line.indexOf('=');if(i>0){//以等于号=为界,截取键与值name=line.substring(0,i).trim();line=line.substring(i+1).trim();}if(line.length()>0){//加载类,并通过loadClass方法对类进行缓存loadClass(extensionClasses,resourceURL,Class.forName(line,true,classLoader),name);}}catch(Throwablet){IllegalStateExceptione=newIllegalStateException("Failedtoloadextensionclass...");}}}}finally{reader.close();}}catch(Throwablet){logger.error("Exceptionwhenloadextensionclass...");}} loadResource 方法用于读取和解析配置文件,并通过反射加载类,最后调用 loadClass 方法进行其他操作。loadClass 方法用于主要用于操作缓存,该方法的逻辑如下: privatevoidloadClass(Map<String,Class<?>>extensionClasses,java.net.URLresourceURL,Class<?>clazz,Stringname)throwsNoSuchMethodException{if(!type.isAssignableFrom(clazz)){thrownewIllegalStateException("...");}//检测目标类上是否有Adaptive注解if(clazz.isAnnotationPresent(Adaptive.class)){if(cachedAdaptiveClass==null){//设置cachedAdaptiveClass缓存cachedAdaptiveClass=clazz;}elseif(!cachedAdaptiveClass.equals(clazz)){thrownewIllegalStateException("...");}//检测clazz是否是Wrapper类型}elseif(isWrapperClass(clazz)){Set<Class<?>>wrappers=cachedWrapperClasses;if(wrappers==null){cachedWrapperClasses=newConcurrentHashSet<Class<?>>();wrappers=cachedWrapperClasses;}//存储clazz到cachedWrapperClasses缓存中wrappers.add(clazz);//程序进入此分支,表明clazz是一个普通的拓展类}else{//检测clazz是否有默认的构造方法,如果没有,则抛出异常clazz.getConstructor();if(name==null||name.length()==0){//如果name为空,则尝试从Extension注解中获取name,或使用小写的类名作为namename=findAnnotationName(clazz);if(name.length()==0){thrownewIllegalStateException("...");}}//切分nameString[]names=NAME_SEPARATOR.split(name);if(names!=null&&names.length>0){Activateactivate=clazz.getAnnotation(Activate.class);if(activate!=null){//如果类上有Activate注解,则使用names数组的第一个元素作为键,//存储name到Activate注解对象的映射关系cachedActivates.put(names[0],activate);}for(Stringn:names){if(!cachedNames.containsKey(clazz)){//存储Class到名称的映射关系cachedNames.put(clazz,n);}Class<?>c=extensionClasses.get(n);if(c==null){//存储名称到Class的映射关系extensionClasses.put(n,clazz);}elseif(c!=clazz){thrownewIllegalStateException("...");}}}}} 综上,loadClass方法操作了不同的缓存,比如cachedAdaptiveClass、cachedWrapperClasses和cachedNames等等 到这里基本上关于缓存类加载的过程就分析完了,其他逻辑不难,认真地读下来加上Debug一下都能看懂的。 总结 从设计思想上来看的话,SPI是对迪米特法则和开闭原则的一种实现。 开闭原则:对修改关闭对扩展开放。这个原则在众多开源框架中都非常常见,Spring的IOC容器也是大量使用。 迪米特法则:也叫最小知识原则,可以解释为,不该直接依赖关系的类之间,不要依赖;有依赖关系的类之间,尽量只依赖必要的接口。 那Dubbo的SPI为什么不直接使用Spring的呢,这一点从众多开源框架中也许都能窥探一点端倪出来,因为本身作为开源框架是要融入其他框架或者一起运行的,不能作为依赖被依赖对象存在。 再者对于Dubbo来说,直接用Spring IOC AOP的话有一些架构臃肿,完全没必要,所以自己实现一套轻量级反而是最优解 往期推荐 还在为大数据平台搭建而烦恼吗?一柄神器送给你 还在为 Arthas 命令头疼? 来看看这个插件吧! Spring Cloud认证授权系列(一)基础概念 基础坑!新版Mac Big Sur 干翻了我的Nacos 讲真!这些攻击手段你知道吗 本文分享自微信公众号 - 架构技术专栏(jiagoujishu)。如有侵权,请联系 support@oschina.cn 删除。本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。