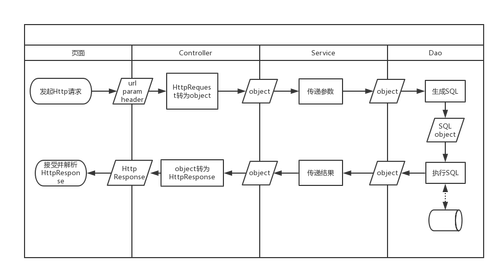
多套方案来提高python web框架的并发处理能力
Python常见部署方法有 : 1 2 3 fcgi :用spawn-fcgi或者框架自带的工具对各个project分别生成监听进程,然后和http 服务互动 wsgi :利用http服务的mod_wsgi模块来跑各个project(Web应用程序或框架简单而通用的Web服务器 之间的接口)。 uWSGI 是一款像php-cgi一样监听同一端口,进行统一管理和负载平衡的工具,uWSGI,既不用wsgi协议也不用fcgi协议,而是自创了一个uwsgi的协议,据说该协议大约是fcgi协议的 10 倍那么快。 1 其实 WSGI 是分成 server 和 framework (即 application) 两部分 (当然还有 middleware)。严格说 WSGI 只是一个协议, 规范 server 和 framework 之间连接的接口。 WSGI server 把服务器功能以 WSGI 接口暴露出来。比如 mod_wsgi 是一种 server, 把 apache 的功能以 WSGI 接口的形式提供出来。 1 2 3 4 5 WSGI framework 就是我们经常提到的 Django 这种框架。不过需要注意的是, 很少有单纯的 WSGI framework , 基于 WSGI 的框架往往都自带 WSGI server。比如 Django、CherryPy 都自带 WSGI server 主要是测试用途, 发布时则使用生产环境的 WSGI server。而有些 WSGI 下的框架比如 pylons、bfg 等, 自己不实现 WSGI server。使用 paste 作为 WSGI server。 Paste 是流行的 WSGI server, 带有很多中间件。还有 flup 也是一个提供中间件的库。 搞清除 WSGI server 和 application, 中间件自然就清楚了。除了 session、cache 之类的应用, 前段时间看到一个 bfg 下的中间件专门用于给网站换肤的 (skin) 。中间件可以想到的用法还很多。 这里再补充一下, 像 django 这样的框架如何以 fastcgi 的方式跑在 apache 上的。这要用到 flup.fcgi 或者 fastcgi.py (eurasia 中也设计了一个 fastcgi.py 的实现) 这些工具, 它们就是把 fastcgi 协议转换成 WSGI 接口 (把 fastcgi 变成一个 WSGI server) 供框架接入。整个架构是这样的: django -> fcgi2wsgiserver -> mod_fcgi -> apache 。 虽然我不是 WSGI 的粉丝, 但是不可否认 WSGI 对 python web 的意义重大。有意自己设计 web 框架, 又不想做 socket 层和 http 报文解析的同学, 可以从 WSGI 开始设计自己的框架。在 python 圈子里有个共识, 自己随手搞个 web 框架跟喝口水一样自然, 非常方便。或许每个 python 玩家都会经历一个倒腾框架的 uWSGI的主要特点如下: 超快的性能。 低内存占用(实测为apache2的mod_wsgi的一半左右)。 多app管理。 详尽的日志功能(可以用来分析app性能和瓶颈)。 高度可定制(内存大小限制,服务一定次数后重启等)。 uwsgi的官方文档: http://projects.unbit.it/uwsgi/wiki/Doc nginx.conf 1 2 3 4 location / { include uwsgi_params uwsgi_pass 127.0 . 0.1 : 9090 } 启动app 1 uwsgi -s : 9090 -w myapp uwsgi的调优参数~ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 uwsgi的参数 以上是单个project的最简单化部署,uwsgi还是有很多令人称赞的功能的,例如: 并发 4 个线程: uwsgi -s : 9090 -w myapp -p 4 主控制线程+ 4 个线程: uwsgi -s : 9090 -w myapp -M -p 4 执行超过 30 秒的client直接放弃: uwsgi -s : 9090 -w myapp -M -p 4 -t 30 限制内存空间128M: uwsgi -s : 9090 -w myapp -M -p 4 -t 30 --limit- as 128 服务超过 10000 个req自动respawn: uwsgi -s : 9090 -w myapp -M -p 4 -t 30 --limit- as 128 -R 10000 后台运行等: uwsgi -s : 9090 -w myapp -M -p 4 -t 30 --limit- as 128 -R 10000 -d uwsgi.log 为了让多个站点共享一个uwsgi服务,必须把uwsgi运行成虚拟站点:去掉“-w myapp”加上”–vhost”: uwsgi -s :9090 -M -p 4 -t 30 --limit-as 128 -R 10000 -d uwsgi.log --vhost 然后必须配置virtualenv,virtualenv是Python的一个很有用的虚拟环境工具,这样安装: 最后配置nginx,注意每个站点必须单独占用一个server,同一server不同location定向到不同的应用不知为何总是失败,估计也 算是一个bug。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 server { listen 80 ; server_name app1.mydomain.com; location / { include uwsgi_params; uwsgi_pass 127.0 . 0.1 : 9090 ; uwsgi_param UWSGI_PYHOME / var /www/myenv; uwsgi_param UWSGI_SCRIPT myapp1; uwsgi_param UWSGI_CHDIR / var /www/myappdir1; } } server { listen 80 ; server_name app2.mydomain.com; location / { include uwsgi_params; uwsgi_pass 127.0 . 0.1 : 9090 ; uwsgi_param UWSGI_PYHOME / var /www/myenv; uwsgi_param UWSGI_SCRIPT myapp2; uwsgi_param UWSGI_CHDIR / var /www/myappdir2; } } 这样,重启nginx服务,两个站点就可以共用一个uwsgi服务了。 再来搞下 fastcgi的方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 location / { fastcgi_param REQUEST_METHOD $request_method; fastcgi_param QUERY_STRING $query_string; fastcgi_param CONTENT_TYPE $content_type; fastcgi_param CONTENT_LENGTH $content_length; fastcgi_param GATEWAY_INTERFACE CGI/ 1.1 ; fastcgi_param SERVER_SOFTWARE nginx/$nginx_version; fastcgi_param REMOTE_ADDR $remote_addr; fastcgi_param REMOTE_PORT $remote_port; fastcgi_param SERVER_ADDR $server_addr; fastcgi_param SERVER_PORT $server_port; fastcgi_param SERVER_NAME $server_name; fastcgi_param SERVER_PROTOCOL $server_protocol; fastcgi_param SCRIPT_FILENAME $fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_script_name; fastcgi_pass 127.0 . 0.1 : 9002 ; } 1 2 3 4 5 6 location / static / { root /path/to/www; if (-f $request_filename) { rewrite ^/ static /(.*)$ / static /$ 1 break ; } } 启动一个fastcgi的进程 1 spawn-fcgi -d /path/to/www -f /path/to/www/index.py -a 127.0 . 0.1 -p 9002 用web.py写的一个小demo测试 1 2 3 4 5 6 7 8 9 10 11 #!/usr/bin/env python # -*- coding: utf- 8 -*- import web urls = ( "/.*" , "hello" ) app = web.application(urls, globals()) class hello: def GET(self): return 'Hello, world!' if __name__ == "__main__" : web.wsgi.runwsgi = lambda func, addr=None: web.wsgi.runfcgi(func, addr) app.run() 启动nginx 1 nginx 这样就ok了~ 下面开始介绍下 我一般用的方法: 前端nginx用负责负载分发: 部署的时候采用了单IP多端口方式,服务器有4个核心,决定开4个端口对应,分别是8885~8888,修改 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 upstream backend { server 127.0 . 0.1 : 8888 ; server 127.0 . 0.1 : 8887 ; server 127.0 . 0.1 : 8886 ; server 127.0 . 0.1 : 8885 ; } server{ listen 80 ; server_name message.test.com; keepalive_timeout 65 ; # proxy_read_timeout 2000 ; # sendfile on; tcp_nopush on; tcp_nodelay on; location / { proxy_pass_header Server; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Scheme $scheme; proxy_pass http: //backend; } } 然后运行四个python程序,端口为咱们配置好的端口 我这里用tornado写了一个执行系统程序的例子: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 import subprocess import tornado.ioloop import time import fcntl import functools import os class GenericSubprocess (object): def __init__ ( self, timeout=- 1 , **popen_args ): self.args = dict() self.args[ "stdout" ] = subprocess.PIPE self.args[ "stderr" ] = subprocess.PIPE self.args[ "close_fds" ] = True self.args.update(popen_args) self.ioloop = None self.expiration = None self.pipe = None self.timeout = timeout self.streams = [] self.has_timed_out = False def start(self): "" "Spawn the task. Throws RuntimeError if the task was already started. "" " if not self.pipe is None: raise RuntimeError( "Cannot start task twice" ) self.ioloop = tornado.ioloop.IOLoop.instance() if self.timeout > 0 : self.expiration = self.ioloop.add_timeout( time.time() + self.timeout, self.on_timeout ) self.pipe = subprocess.Popen(**self.args) self.streams = [ (self.pipe.stdout.fileno(), []), (self.pipe.stderr.fileno(), []) ] for fd, d in self.streams: flags = fcntl.fcntl(fd, fcntl.F_GETFL)| os.O_NDELAY fcntl.fcntl( fd, fcntl.F_SETFL, flags) self.ioloop.add_handler( fd, self.stat, self.ioloop.READ|self.ioloop.ERROR) def on_timeout(self): self.has_timed_out = True self.cancel() def cancel (self ) : "" "Cancel task execution Sends SIGKILL to the child process. "" " try : self.pipe.kill() except: pass def stat( self, *args ): '' 'Check process completion and consume pending I/O data' '' self.pipe.poll() if not self.pipe.returncode is None: '' 'cleanup handlers and timeouts' '' if not self.expiration is None: self.ioloop.remove_timeout(self.expiration) for fd, dest in self.streams: self.ioloop.remove_handler(fd) '' 'schedulle callback (first try to read all pending data)' '' self.ioloop.add_callback(self.on_finish) for fd, dest in self.streams: while True: try : data = os.read(fd, 4096 ) if len(data) == 0 : break dest.extend([data]) except: break @property def stdout(self): return self.get_output( 0 ) @property def stderr(self): return self.get_output( 1 ) @property def status(self): return self.pipe.returncode def get_output(self, index ): return "" .join(self.streams[index][ 1 ]) def on_finish(self): raise NotImplemented() class Subprocess (GenericSubprocess): "" "Create new instance Arguments: callback: method to be called after completion. This method should take 3 arguments: statuscode( int ), stdout(str), stderr(str), has_timed_out(boolean) timeout: wall time allocated for the process to complete. After this expires Task.cancel is called. A negative timeout value means no limit is set The task is not started until start is called. The process will then be spawned using subprocess.Popen(**popen_args). The stdout and stderr are always set to subprocess.PIPE. "" " def __init__ ( self, callback, *args, **kwargs): "" "Create new instance Arguments: callback: method to be called after completion. This method should take 3 arguments: statuscode( int ), stdout(str), stderr(str), has_timed_out(boolean) timeout: wall time allocated for the process to complete. After this expires Task.cancel is called. A negative timeout value means no limit is set The task is not started until start is called. The process will then be spawned using subprocess.Popen(**popen_args). The stdout and stderr are always set to subprocess.PIPE. "" " self.callback = callback self.done_callback = False GenericSubprocess.__init__(self, *args, **kwargs) def on_finish(self): if not self.done_callback: self.done_callback = True '' 'prevent calling callback twice' '' self.ioloop.add_callback(functools.partial(self.callback, self.status, self.stdout, self.stderr, self.has_timed_out)) if __name__ == "__main__" : ioloop = tornado.ioloop.IOLoop.instance() def print_timeout( status, stdout, stderr, has_timed_out) : assert(status!= 0 ) assert(has_timed_out) print "OK status:" , repr(status), "stdout:" , repr(stdout), "stderr:" , repr(stderr), "timeout:" , repr(has_timed_out) def print_ok( status, stdout, stderr, has_timed_out) : assert(status== 0 ) assert(not has_timed_out) print "OK status:" , repr(status), "stdout:" , repr(stdout), "stderr:" , repr(stderr), "timeout:" , repr(has_timed_out) def print_error( status, stdout, stderr, has_timed_out): assert(status!= 0 ) assert(not has_timed_out) print "OK status:" , repr(status), "stdout:" , repr(stdout), "stderr:" , repr(stderr), "timeout:" , repr(has_timed_out) def stop_test(): ioloop.stop() t1 = Subprocess( print_timeout, timeout= 3 , args=[ "sleep" , "5" ] ) t2 = Subprocess( print_ok, timeout= 3 , args=[ "sleep" , "1" ] ) t3 = Subprocess( print_ok, timeout= 3 , args=[ "sleepdsdasdas" , "1" ] ) t4 = Subprocess( print_error, timeout= 3 , args=[ "cat" , "/etc/sdfsdfsdfsdfsdfsdfsdf" ] ) t1.start() t2.start() try : t3.start() assert( false ) except: print "OK" t4.start() ioloop.add_timeout(time.time() + 10 , stop_test) ioloop.start() 本文转自 rfyiamcool 51CTO博客,原文链接:http://blog.51cto.com/rfyiamcool/1227629,如需转载请自行联系原作者