记录一次docker集群中搭建mongodb副本集
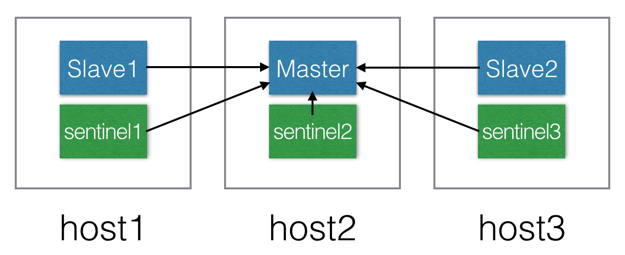
1.创建三个装有mongo的docker容器,这里使用docker-compose,配置如下 mongo: image: mongo command: mongod -f /etc/mongo.conf volumes: - ${DATA_PATH_HOST}/mongo:/data/db - ${CONF_PATH}/mongo/mongo_yaml.conf:/etc/mongo.conf - ${CONF_PATH}/mongo/access.key:/etc/access.key expose: - 27017 ports: - 27017:27017 networks: - backend mongo2: image: mongo command: mongod -f /etc/mongo.conf volumes: - ${DATA_PATH_HOST}/mongo2:/data/db - ${CONF_PATH}/mongo/mongo_yaml.conf:/etc/mongo.conf - ${CONF_PATH}/mongo/access.key:/etc/access.key expose: - 27017 ports: - 27018:27017 networks: - backend mongo3: image: mongo command: mongod -f /etc/mongo.conf volumes: - ${DATA_PATH_HOST}/mongo3:/data/db - ${CONF_PATH}/mongo/mongo_yaml.conf:/etc/mongo.conf - ${CONF_PATH}/mongo/access.key:/etc/access.key expose: - 27017 ports: - 27019:27017 networks: - backend 其中mongo.conf 为yaml格式的mongodb配置文件,内容如下 processManagement: fork: false net: bindIp: 127.0.0.1 port: 27017 storage: dbPath: /data/db systemLog: #destination: file #path: log/mongo27017.log logAppend: true storage: journal: enabled: true replication: oplogSizeMB: 500 replSetName: "r1" secondaryIndexPrefetch: "all" 执行docker-compose up -d mongo mongo2 mongo3 创建三个mongo容器 并指定副本集 r1 2. 登入任意一台机器的MongoDB执行:因为是全新的副本集所以可以任意进入一台执行;要是有一台有数据,则需要在有数据上执行;要多台有数据则不能初始化。我个人是mongo中有数据但是mongo2和mong3是空的数据库,所以我登录mongo1进行副本集初始化。 执行命令 docker-compose exec mongo bash 进入容器 执行命令 mongo 在容器内部连接mongo 执行一下命令初始化副本集 > use admin switched to db admin > config = { "_id": "r1", "members": [{ "_id": 0, "host": "mongo:27017", "priority": 1 }, { "_id": 1, "host": "mongo2:27017", "priority": 1 }, { "_id": 2, "host": "mongo3:27017", "priority": 1 }] } { "_id" : "r1", "members" : [ { "_id" : 0, "host" : "mongo:27017", "priority" : 1 }, { "_id" : 1, "host" : "mongo2:27017", "priority" : 1 }, { "_id" : 2, "host" : "mongo3:27017", "priority" : 1 } ] } > rs.initiate(config) { "ok" : 1, "operationTime" : Timestamp(1539830924, 1), "$clusterTime" : { "clusterTime" : Timestamp(1539830924, 1), "signature" : { "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="), "keyId" : NumberLong(0) } } } 副本集初始化完成,可以使用命令rs.status()查看当前副本集状态,至此mongodb副本集设置完成 3.加入鉴权机制,如果服务端需要开启auth认证,则在启动时通过keyFile三个节点之间的通信授权 使用命令生成keyFile文件 openssl rand -base64 745 > /docker/conf/mongo/mongo-keyfile ch 如果服务器启动时加入了参数--keyFile = /docker/conf/mongo/mongo-keyfile 则mongo服务端启动时会自动开启auth,故应先创建账号。 创建了账号 root pass auth库为admin (步骤省略) 停止所有节点,重新启动mongo服务,并加上 --keyFile参数 发现报错 mongo3_1 | 2018-10-24T06:13:06.323+0000 I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none' mongo3_1 | 2018-10-24T06:13:06.331+0000 I ACCESS [main] permissions on /etc/access.key are too open mongo2_1 | 2018-10-24T06:13:06.591+0000 I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none' mongo2_1 | 2018-10-24T06:13:06.605+0000 I ACCESS [main] permissions on /etc/access.key are too open mongo_1 | 2018-10-24T06:13:06.609+0000 I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none' mongo_1 | 2018-10-24T06:13:06.614+0000 I ACCESS [main] permissions on /etc/access.key are too open 这是因为keyfile权限问题,执行命令将keyfile权限设置为600 chmod 600 /docker/conf/mongo/access.key 再次启动,成功。 进入某一容器执行副本集链接操作,系统提示已成功连接到副本集