HUE配置
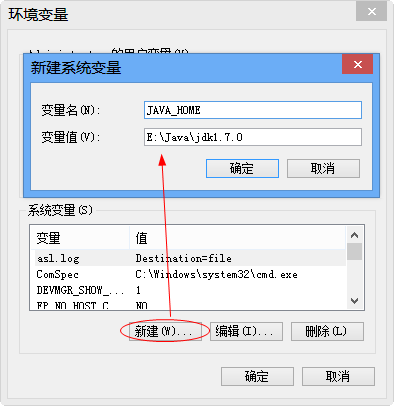
Where is my hue.ini? CDHpackage: /etc/hue/conf/hue.ini A tarballrelease: /usr/share/desktop/conf/hue.ini Developmentversion: desktop/conf/pseudo-distributed.ini Cloudera Manager: CMgeneratesall the hue.ini for you, so no hassle/var/run/cloudera-scm-agent/process/`ls -alrt /var/run/cloudera-scm-agent/process | grep HUE | tail -1 | awk ‘{print $9}’`/hue.ini [beeswax] # Host where HiveServer2 is running. hive_server_host=localhost To point to another server, just replaced the host value by ‘hiveserver.ent.com’: [beeswax] # Host where HiveServer2 is running. hive_server_host=hiveserver.ent.com Note:Any line starting with a # is considered as a comment so is not used. Note:The list of mis-configured services are listed on the/about/admin_wizardpage. Note:After each change in the ini file, Hue should be restarted to pick it up. Note:In some cases, as explained inhow to configure Hadoop for Hue documentation, the API of these services needs to be turned on and Hue set as proxy user. Here are the main sections that you will need to update in order to have each service accessible in Hue: HDFS This is required forlisting or creating files. Replace localhost by the real address of the NameNode (usually http://localhost:50070). Enter this in hdfs-site.xmlto enable WebHDFS in the NameNode and DataNodes: << code="">property> << code="">name>dfs.webhdfs.enabledname> << code="">value>truevalue> property> Configure Hue as a proxy user for all other users and groups, meaning it may submit a request on behalf of any other user. Add tocore-site.xml: << code="">property> << code="">name>hadoop.proxyuser.hue.hostsname> << code="">value>*value> property> << code="">property> << code="">name>hadoop.proxyuser.hue.groupsname> << code="">value>*value> property> Then, if the Namenode is on another host than Hue, don’t forget to update in the hue.ini: [hadoop] `hdfs_clusters` [`default`] # Enter the filesystem uri fs_defaultfs=hdfs://localhost:8020 # Use WebHdfs/HttpFs as the communication mechanism. # Domain should be the NameNode or HttpFs host. webhdfs_url=http://localhost:50070/webhdfs/v1 YARN The Resource Manager is often on http://localhost:8088 by default. The ProxyServer and Job History servers also needs to be specified. Then Job Browser will let youlist and kill running applicationsand get their logs. [hadoop] `yarn_clusters` [`default`] # Enter the host on which you are running the ResourceManager resourcemanager_host=localhost # Whether to submit jobs to this cluster submit_to=True # URL of the ResourceManager API resourcemanager_api_url=http://localhost:8088 # URL of the ProxyServer API proxy_api_url=http://localhost:8088 # URL of the HistoryServer API history_server_api_url=http://localhost:19888 Hive Here we need a running HiveServer2 in order tosend SQL queries. [beeswax] # Host where HiveServer2 is running. hive_server_host=localhost Note:If HiveServer2 is on another machine and you are using security or customized HiveServer2 configuration, you will need to copy the hive-site.xml on the Hue machine too: [beeswax] # Host where HiveServer2 is running. hive_server_host=localhost # Hive configuration directory, where hive-site.xml is located hive_conf_dir=/etc/hive/conf Solr Search We just need to specify the address of a Solr Cloud (or non Cloud Solr), theninteractive dashboardscapabilities are unleashed! [search] # URL of the Solr Server solr_url=http://localhost:8983/solr/ Oozie An Oozie server should be up and running beforesubmitting or monitoring workflows. [liboozie] # The URL where the Oozie service runs on. oozie_url=http://localhost:11000/oozie HBase The HBase app works with a HBase Thrift Server version 1. It lets youbrowse, query and edit HBase tables. [hbase] # Comma-separated list of HBase Thrift server 1 for clusters in the format of '(name|host:port)'. hbase_clusters=(Cluster|localhost:9090) 本文转自 yntmdr 51CTO博客,原文链接:http://blog.51cto.com/yntmdr/1743223,如需转载请自行联系原作者