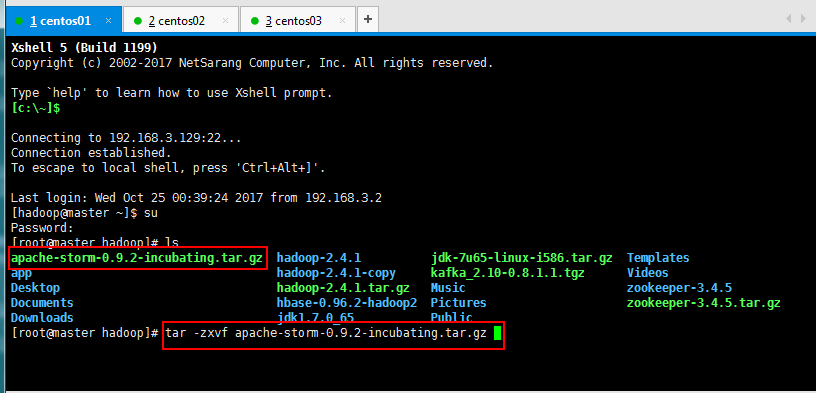
一脸懵逼学习MapReduce的原理和编程(Map局部处理,Reduce汇总)和MapReduce几种运行方式
1:MapReduce的概述: (1):MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题. (2):MapReduce由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。 (3):这两个函数的形参是key、value对,表示函数的输入信息。 2:MapReduce执行步骤: (1): map任务处理 (a):读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。 (b):写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。 (2)reduce任务处理 (a)在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。 (b)写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。 (c)把reduce的输出保存到文件中。 例子:实现WordCountApp3:map、reduce键值对格式: 4:MapReduce流程: (1)代码编写 (2)作业配置 (3)提交作业 (4)初始化作业 (5)分配任务 (6)执行任务 (7)更新任务和状态 (8)完成作业 5:MapReduce介绍及wordcount和wordcount的编写和提交集群运行的案例: WcMap类进行单词的局部处理: 1 package com.mapreduce; 2 3 4 import java.io.IOException; 5 6 import org.apache.commons.lang.StringUtils; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Mapper; 10 11 /*** 12 * 13 * @author Administrator 14 * 1:4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的值 15 * KEYOUT是输入的key的类型,VALUEOUT是输入的value的值 16 * 2:map和reduce的数据输入和输出都是以key-value的形式封装的。 17 * 3:默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value 18 * 4:key-value数据是在网络中进行传递,节点和节点之间互相传递,在网络之间传输就需要序列化,但是jdk自己的序列化很冗余 19 * 所以使用hadoop自己封装的数据类型,而不要使用jdk自己封装的数据类型; 20 * Long--->LongWritable 21 * String--->Text 22 */ 23 public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{ 24 25 //重写map这个方法 26 //mapreduce框架每读一行数据就调用一次该方法 27 @Override 28 protected void map(LongWritable key, Text value, Context context) 29 throws IOException, InterruptedException { 30 //具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value 31 //key是这一行数据的起始偏移量,value是这一行的文本内容 32 33 //1:切分单词,首先拿到单词value的值,转化为String类型的 34 String str = value.toString(); 35 //2:切分单词,空格隔开,返回切分开的单词 36 String[] words = StringUtils.split(str," "); 37 //3:遍历这个单词数组,输出为key-value的格式,将单词发送给reduce 38 for(String word : words){ 39 //输出的key是Text类型的,value是LongWritable类型的 40 context.write(new Text(word), new LongWritable(1)); 41 } 42 43 44 } 45 } WcReduce进行单词的计数处理: 1 package com.mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Reducer; 8 9 /*** 10 * 11 * @author Administrator 12 * 1:reduce的四个参数,第一个key-value是map的输出作为reduce的输入,第二个key-value是输出单词和次数,所以 13 * 是Text,LongWritable的格式; 14 */ 15 public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ 16 17 //继承Reducer之后重写reduce方法 18 //第一个参数是key,第二个参数是集合。 19 //框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法 20 //<hello,{1,1,1,1,1,1.....}> 21 @Override 22 protected void reduce(Text key, Iterable<LongWritable> values,Context context) 23 throws IOException, InterruptedException { 24 //将values进行累加操作,进行计数 25 long count = 0; 26 //遍历value的list,进行累加求和 27 for(LongWritable value : values){ 28 29 count += value.get(); 30 } 31 32 //输出这一个单词的统计结果 33 //输出放到hdfs的某一个目录上面,输入也是在hdfs的某一个目录 34 context.write(key, new LongWritable(count)); 35 } 36 37 38 } WcRunner用来描述一个特定的作业 1 package com.mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 14 /*** 15 * 1:用来描述一个特定的作业 16 * 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce 17 * 2:还可以指定该作业要处理的数据所在的路径 18 * 还可以指定改作业输出的结果放到哪个路径 19 * @author Administrator 20 * 21 */ 22 public class WcRunner { 23 24 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 25 //创建配置文件 26 Configuration conf = new Configuration(); 27 //获取一个作业 28 Job job = Job.getInstance(conf); 29 30 //设置整个job所用的那些类在哪个jar包 31 job.setJarByClass(WcRunner.class); 32 33 //本job使用的mapper和reducer的类 34 job.setMapperClass(WcMap.class); 35 job.setReducerClass(WcReduce.class); 36 37 //指定reduce的输出数据key-value类型 38 job.setOutputKeyClass(Text.class); 39 job.setOutputValueClass(LongWritable.class); 40 41 42 //指定mapper的输出数据key-value类型 43 job.setMapOutputKeyClass(Text.class); 44 job.setMapOutputValueClass(LongWritable.class); 45 46 //指定要处理的输入数据存放路径 47 FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000/wc/srcdata")); 48 49 //指定处理结果的输出数据存放路径 50 FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wc/output")); 51 52 //将job提交给集群运行 53 job.waitForCompletion(true); 54 } 55 56 } 书写好上面的三个类以后打成jar包上传到虚拟机上面进行运行: 然后启动你的hadoop集群:start-dfs.sh和start-yarn.sh启动集群;然后将jar分发到节点上面进行运行; 之前先造一些数据,如下所示: 内容自己随便搞吧: 然后上传到hadoop集群上面,首选创建目录,存放测试数据,将数据上传到创建的目录即可;但是输出目录不需要手动创建,会自动创建,自己创建会报错: 然后将jar分发到节点上面进行运行;命令格式如hadoop jar 自己的jar包 主类的路径 正常性运行完过后可以查看一下运行的效果: 6:MapReduce的本地模式运行如下所示(本地运行需要修改输入数据存放路径和输出数据存放路径): 1 package com.mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.Path; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Job; 10 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 11 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 12 13 14 /*** 15 * 1:用来描述一个特定的作业 16 * 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce 17 * 2:还可以指定该作业要处理的数据所在的路径 18 * 还可以指定改作业输出的结果放到哪个路径 19 * @author Administrator 20 * 21 */ 22 public class WcRunner { 23 24 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 25 //创建配置文件 26 Configuration conf = new Configuration(); 27 //获取一个作业 28 Job job = Job.getInstance(conf); 29 30 //设置整个job所用的那些类在哪个jar包 31 job.setJarByClass(WcRunner.class); 32 33 //本job使用的mapper和reducer的类 34 job.setMapperClass(WcMap.class); 35 job.setReducerClass(WcReduce.class); 36 37 //指定reduce的输出数据key-value类型 38 job.setOutputKeyClass(Text.class); 39 job.setOutputValueClass(LongWritable.class); 40 41 42 //指定mapper的输出数据key-value类型 43 job.setMapOutputKeyClass(Text.class); 44 job.setMapOutputValueClass(LongWritable.class); 45 46 //指定要处理的输入数据存放路径 47 //FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000/wc/srcdata/")); 48 FileInputFormat.setInputPaths(job, new Path("d:/wc/srcdata/")); 49 50 51 //指定处理结果的输出数据存放路径 52 //FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wc/output/")); 53 FileOutputFormat.setOutputPath(job, new Path("d:/wc/output/")); 54 55 56 //将job提交给集群运行 57 job.waitForCompletion(true); 58 } 59 60 } 然后去自己定义的盘里面创建文件夹即可: 然后直接运行出现下面的错误: log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.Exception in thread "main" java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses. at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:120) at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:82) at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:75) at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1255) at org.apache.hadoop.mapreduce.Job$9.run(Job.java:1251) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556) at org.apache.hadoop.mapreduce.Job.connect(Job.java:1250) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1279) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) at com.mapreduce.WcRunner.main(WcRunner.java:57) 解决办法: 缺少Jar包:hadoop-mapreduce-client-common-2.2.0.jar 好吧,最后还是没有实现在本地运行此运行,先在这里记一下吧。下面这个错搞不定,先做下笔记吧; log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).log4j:WARN Please initialize the log4j system properly.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.Exception in thread "main" java.lang.IllegalArgumentException: Pathname /c:/wc/output from hdfs://master:9000/c:/wc/output is not a valid DFS filename. at org.apache.hadoop.hdfs.DistributedFileSystem.getPathName(DistributedFileSystem.java:194) at org.apache.hadoop.hdfs.DistributedFileSystem.access$000(DistributedFileSystem.java:102) at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124) at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398) at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:145) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:343) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) at com.mapreduce.WcRunner.main(WcRunner.java:57) 7:MapReduce程序的几种提交运行模式: 本地模型运行1:在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行 ----输入输出数据可以放在本地路径下(c:/wc/srcdata/) ----输入输出数据也可以放在hdfs中(hdfs://master:9000/wc/srcdata)2:在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行 ----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/) ----输入输出数据也可以放在hdfs中(hdfs://master:9000/wc/srcdata) 集群模式运行1:将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner2:在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施: ----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml ----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set("mapreduce.job.jar","wc.jar"); 3:在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改 ----要在windows中存放一份hadoop的安装包(解压好的) ----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件 ----再要配置系统环境变量 HADOOP_HOME 和 PATH ----修改YarnRunner这个类的源码