Android 事件处理(—)(附源码)
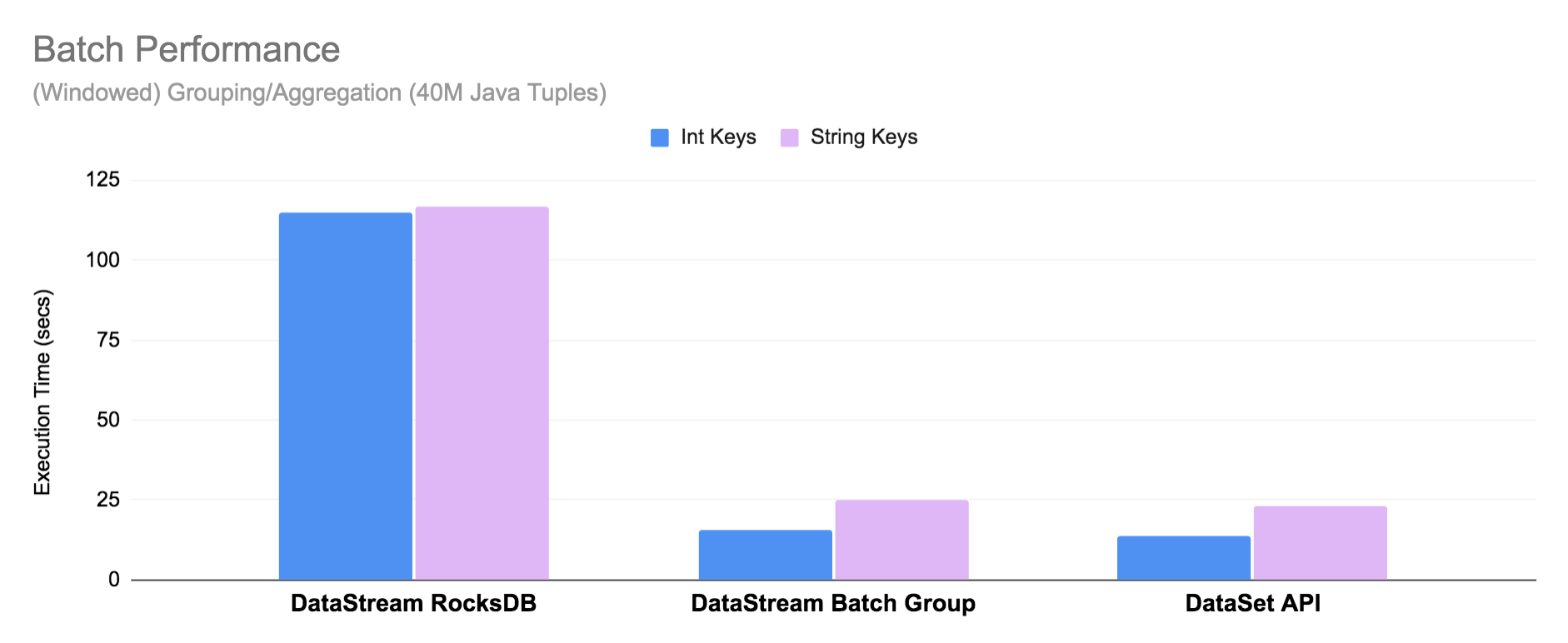
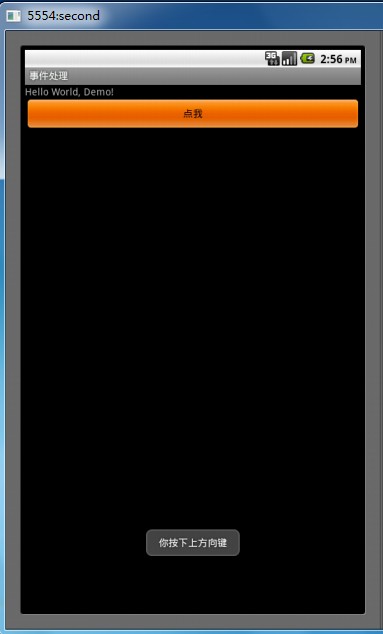
(一)事件使我们在于UI交互式发生的,我们点击一个按键时,可能就已经除非好几个事件,例如我们点击数字键“0”,他会涉及到按下事件,和一个弹起(松开)事件,在我们android中还可能涉及到触摸屏事件,所以在android系统中,事件是作为常用的功能之一; 在android下,事件的发生是在监听器下进行,android系统可以响应按键事件和触摸屏事件,事件说明如下: lonClick(View v)一个普通的点击按钮事件 lboolean onKeyMultiple(int keyCode,int repeatCount,KeyEvent event)用于在多个事件连续时发生,用于按键重复,必须重载@Override实现 lboolean onKeyDown(int keyCode,KeyEvent event)用于在按键进行按下时发生 lboolean onKeyUp(int keyCode,KeyEvent event)用于在按键进行释放时发生 lonTouchEvent(MotionEvent event)触摸屏事件,当在触摸屏上有动作时发生 lboolean onKeyLongPress(int keyCode, KeyEvent event)当你长时间按时发生(疑问?) (二)首先我们建立一个android项目,当项目建立好之后,直接在默认的main.xml文件中拖放一个button按钮,其他的不需要在这里做什么了,然后就可以到命名好的.java文件中进行先关代码的书写; 1.对要使用的控件进行引用,当然你也可以用到的时候再在相关类控件添加引用 importandroid.app.Activity; importandroid.os.Bundle; importandroid.view.KeyEvent; importandroid.view.MotionEvent; importandroid.view.View; importandroid.widget.Button; importandroid.widget.Toast; 2.获得相关对象,设置控件监听器 Buttonbutton=(Button) findViewById(R.id.button1); //设置监听 button.setOnClickListener(newButton.OnClickListener() { @Override publicvoidonClick(View v) { //TODOAuto-generated method stub DisplayToast("事件触发成功"); } }); 请注意这里末尾使用的是分号“;这里就是获得button的实例,然后对他进行监听,当用户点击时就会发生onClick事件,这里还用到一个方法,就是显示一个短消息,在屏幕停留几秒钟就会自动消失,其方法如下: publicvoidDisplayToast(String str) { Toast.makeText(this, str, Toast.LENGTH_SHORT).show(); } 当然你也可以设置显示长点,即Toast.LENGTH_SHORT改为Toast.LENGTH_LONG 3.当按键按下是发生的事件 public boolean onKeyDown(intkeyCode,KeyEvent event) { switch(keyCode) { case KeyEvent.KEYCODE_0: DisplayToast("你按下数字键0"); break; case KeyEvent.KEYCODE_DPAD_CENTER: DisplayToast("你按下中间键"); break;sss case KeyEvent.KEYCODE_DPAD_DOWN: DisplayToast("你按下下方向键"); break; case KeyEvent.KEYCODE_DPAD_LEFT: DisplayToast("你按下左方向键"); break; case KeyEvent.KEYCODE_DPAD_RIGHT: DisplayToast("你按下右方向键"); break; case KeyEvent.KEYCODE_DPAD_UP: DisplayToast("你按下上方向键"); break; case KeyEvent.KEYCODE_ALT_LEFT: DisplayToast("你按下组合键alt+←"); break; } return super.onKeyDown(keyCode, event); } 这里所有的keyCode都囊括了,这只是几个比较典型的例子,效果如下: 4.当按键弹起时发生的事件,代码如下: publicbooleanonKeyUp(intkeyCode,KeyEvent event) { switch(keyCode) { caseKeyEvent.KEYCODE_0: DisplayToast("松开数字键0"); break; caseKeyEvent.KEYCODE_DPAD_CENTER: DisplayToast("松开中间键"); break; caseKeyEvent.KEYCODE_DPAD_DOWN: DisplayToast("松开下方向键"); break; caseKeyEvent.KEYCODE_DPAD_LEFT: DisplayToast("松开左方向键"); break; caseKeyEvent.KEYCODE_DPAD_RIGHT: DisplayToast("松开右方向键"); break; caseKeyEvent.KEYCODE_DPAD_UP: DisplayToast("松开上方向键"); break; caseKeyEvent.KEYCODE_ALT_LEFT: DisplayToast("松开组合键alt+←"); break; } returnsuper.onKeyUp(keyCode, event); } 效果与上图类似,只是文字不一样 5.触摸屏事件,当用手或者用笔在触摸屏上做动作是发生,相关代码如下: publicbooleanonTouchEvent(MotionEvent event) { intiAction=event.getAction(); if(iAction==MotionEvent.ACTION_MOVE) { DisplayToast("你在触摸屏上进行了滑动"); } else { returnfalse; } returnsuper.onTouchEvent(event); } 6.连续点击按键时发生的事件 Publicboolean onKeyMultiple(int keyCode,int repeatCount,KeyEvent event) { Return super.onKeyMultiple(keyCode, repeatCount, event); } 整体效果还不错,又向android迈进一步!!! 本文转自shenzhoulong 51CTO博客,原文链接:http://blog.51cto.com/shenzhoulong/510230,如需转载请自行联系原作者