Android基础知识
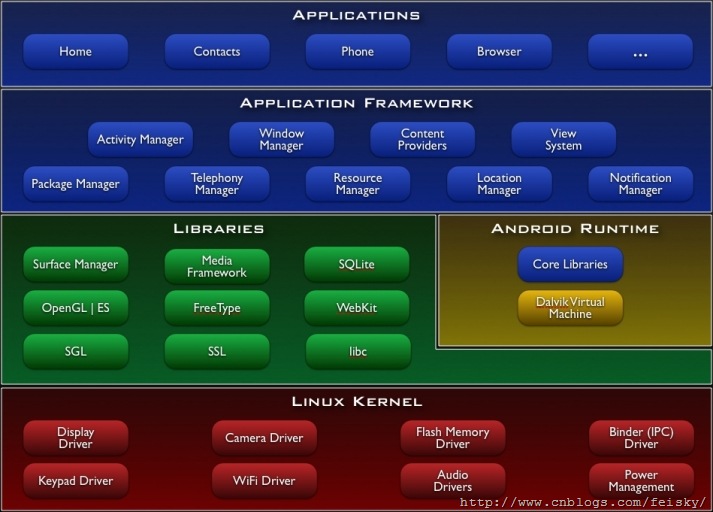
Android特性: Application frameworkenabling reuse and replacement of components Dalvik virtual machineoptimized for mobile devices Integrated browserbased on the open sourceWebKitengine Optimized graphicspowered by a custom 2D graphics library; 3D graphics based on the OpenGL ES 1.0 specification (hardware acceleration optional) SQLitefor structured data storage Media supportfor common audio, video, and still image formats (MPEG4, H.264, MP3, AAC, AMR, JPG, PNG, GIF) GSM Telephony(hardware dependent) Bluetooth, EDGE, 3G, and WiFi(hardware dependent) Camera, GPS, compass, and accelerometer(hardware dependent) Rich development environmentincluding a device emulator, tools for debugging, memory and performance profiling, and a plugin for the Eclipse IDE 框架: 应用程序部件: Activity Services Content Providers Broadcast receiver Manifest 文件 整个程序的功能清单,包括包的定义、版本声明,应用程序Activity、ICON、service、intent filter等的声明。 在Eclipse中可以通过Manifest Editor方便编辑(右键打开)。 <?xml version="1.0" encoding="utf-8"?> <manifest . . . > <application . . . > <activity android:name="com.example.project.FreneticActivity" android:icon="@drawable/small_pic.png" android:label="@string/freneticLabel" . . . > </activity> . . . </application> </manifest> Activities and Tasks 一个task就是用户感觉上的"应用程序",task 是一组相互关联的activity集合组成的栈(这些activity可能属于多个应用程序). 栈底就是应用程序启动时显示的第一个activity。栈顶activity就是用户在屏幕上看到的activity。当一个activity启动一个新的activity时,新的activity就会被压入栈中。当用户点击"back " 按钮时,位于栈顶的activity将会被弹出栈。我们举个例子,假设task中有两个activity,分别是 A 和 B,其中A是位于栈顶的activity,用户点击"back"后, A就被弹出栈, B 就成为了新的栈顶activity,然后 activity B 会显示在屏幕上。 通常来讲,task栈中的activity不会被改变排列顺序,只有出栈和入栈操作。 A task is a stack of activities, not a class or an element in the manifest file. So there's no way to set values for a task independently of its activities. Values for the task as a whole are set in the root activity. For example, the next section will talk about the "affinity of a task"; that value is read from the affinity set for the task's root activity. 一个task中的所有activity是作为一个整体来移动的--移到前台后者后台。就个例子,假设当前 task 栈中有ABCD4个activity,A是栈顶activity,也就是在屏幕上显示的activity,用户点击了"home"键,启动了一个新的应用程序,则 ABCD 4个activity都会被移动到后台。过了一会,用户又点击了"home"键,并重新选择了先前的程序,则 ABCD 都被移动到前台,A 仍然作为栈顶activity 被显示在屏幕上,然后用户点击了"back",A被弹出栈,B作为新的栈顶activity被显示在屏幕上。 前面所讲的都是task的默认行为,我们可以通过某些方法改变task 的默认行为。 不同的task里的activity是由affinity来区别的.默认情况下每个task里面的activities都有相同的affinity。但是可以通过<activity> 标签里taskAffinity属性来修改某个activity的affinity,此时需要设置FLAG_ACTIVITY_NEW_TASK标志,并且allowTaskReparenting 属性设置为true。关于这点的文档解释是:As described earlier, a new activity is, by default, launched into the task of the activity that calledstartActivity(). It's pushed onto the same stack as the caller. However, if the Intent object passed tostartActivity()contains theFLAG_ACTIVITY_NEW_TASKflag, the system looks for a different task to house the new activity. Often, as the name of the flag implies, it's a new task. However, it doesn't have to be. If there's already an existing task with the same affinity as the new activity, the activity is launched into that task. If not, it begins a new task. 注意:在使用FLAG_ACTIVITY_NEW_TASK属性(singleTask和singleInstance类似)时,无法回退到调用者。 activity在task中加载方式主要有四种: 1.standard(the default mode):一个intent发过来之后,都会产生一个新的activity来响应这个intent; 2.singleTop:保持stack顶端的那个activity.也就是说,如果一个intent是由stack顶端的activity处理的话,将不会新建一个新的activity来处理,而是由原来的那个activity处理; 3.singleTask:对于这个activity则会新建一个task.也就是说,对于这个activity,会分配一个新的affinity; 4.singleInstance:identical to "singleTask",并保证这个activity唯一. 既然对初始加载的过程有所规定,那么也就很自然地会有结束过程的一些方式: acitivity在退出的时候,必然会影响到task的stack,因此,android对acitivity的行为方式也做了规定. 1.alwaysRetainTaskState属性.保证stack不变.默认状态下,一个task长期不活动的话,会退化到root activity,也就是弹出stack,只保留底部的一个acitivity. 2.clearTaskOnLaunch属性.这个会在acitivity加载的时候清空task的stack. 3.finishOnTaskLaunch属性.某种程度上说这个属性保证了某项task是唯一的.因为当一个同类的task加载的时候,如果此属性为true,那么就会先退出之前的task,然后再加载这个task. 如果FLAG_ACTIVITY_CLEAR_TOP属性为真,则结束activity时,所有处于该activity堆栈之上的activity都会同时清除,FLAG_ACTIVITY_CLEAR_TOP is most often used in conjunction with FLAG_ACTIVITY_NEW_TASK. When used together, these flags are a way of locating an existing activity in another task and putting it in a position where it can respond to the intent. 本文转自feisky博客园博客,原文链接:http://www.cnblogs.com/feisky/archive/2009/12/30/1636377.html,如需转载请自行联系原作者