表驱动法,逻辑控制优化利器
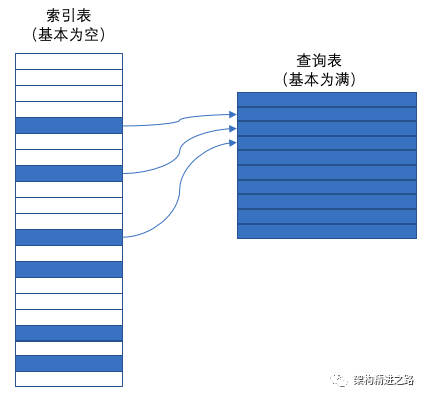
hello,大家好,我是张张,「架构精进之路」公号作者。 最近好多同学在开发过程中谈到设计表结构的一些idea,为了让大家少走一些弯路,今天就计划聊聊表驱动法吧~ 1、概念介绍 表驱动法 是一种编程模式,从表里查找信息而不使用逻辑语句(if/else) 事实上,凡是能通过逻辑语句来选择的事物,都可以通过查表来选择。 对简单的情况而言,使用逻辑语句更为容易和直白,但随着逻辑链的越来越复杂,查表法也就愈发显得更具有吸引力。 应用原则 适当的情况下,采用表驱动法,所生成的代码会比复杂的逻辑代码更简单,更容易修改,而且效率更高。 2、应用实践 2.1 直接访问 2.1.1 今天周几? 传统写法: String today = "周日";Switch( dayForMonth % 7 ){ case 0 : today = "周日"; case 1 : today = "周一"; case 2 : today = "周二"; case 3 : today = "周三"; case 4 : today = "周四"; case 5 : today = "周五"; default: today = "周六"; } 表驱动法: String [] weekday = new String[]{"周日","周一","周二","周三","周四","周五","周六"}; String today = weekday [ dayForMonth % 7 ]; 2.1.2 每个月多少天? 传统写法: if(1 == iMonth) { iDays = 31;} else if(2 == iMonth) { iDays = 28;} else if(3 == iMonth) { iDays = 31;} else if(4 == iMonth) { iDays = 30;} else if(5 == iMonth) { iDays = 31;} else if(6 == iMonth) { iDays = 30;} else if(7 == iMonth) { iDays = 31;} else if(8 == iMonth) { iDays = 31;} else if(9 == iMonth) { iDays = 30;} else if(10 == iMonth) { iDays = 31;} else if(11 == iMonth) { iDays = 30;} else if(12 == iMonth) { iDays = 31;} 表驱动法: 把逻辑写成 map 或是 list,一目了然,可以搞个2维数组还加上了闰年的逻辑。 const monthDays = [ [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31], [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]]function getMonthDays(month, year) { let isLeapYear = (year % 4 === 0) && (year % 100 !== 0 || year % 400 === 0) ? 1 : 0 return monthDays[isLeapYear][(month - 1)];}console.log(getMonthDays(2, 2000)) 2.2 索引访问 有时只用一个简单的数学运算还无法把 age 这样的数据转换成为表键值,这种情况可以通过索引访问的方法加以解决。 索引应用:先用一个基本类型的数据从一张索引表中查出一个键值,然后在用这一键值查出需要的主数据。 举例: 有100件商品,商店物品编号(范围 0000-9999) 创建两张表:索引表(0-9999),物品(查询)表(0-100) 索引访问有两个优点: 如果主查询表的每条记录都很大,那创建一个浪费了很多空间的数组所用的空间,要比建立主查询表所用的空间小得多。 操作索引中的记录比操作主查询表的的记录更方便,编写到表里面的数据比嵌入代码的数据更容易维护。 2.3 阶梯访问 这种访问方法不像索引结构那样直接,但是它要比索引访问方法节省空间。 阶梯结构的基本思想:表中的记录对于不同数据范围有效,而不是对不同的数据点有效。 举例: 一个等级评定的应用程序,其中“B”记录所对应的范围是 75.0%-90.0% >= 90.0% A <90.0% B <75.0% C <65.0% D <50.0% F 这种划分范围用在查询表中是不合适的,因为你不能用简单的数据转换函数来把表键值转换成 A-F 字母所代表的等级。用索引也不合适,因为这里用的是浮点数。 在应用阶梯方法的时候,必须谨慎的处理范围的端点。 Dim rangeLimit() As Double = {50.0, 65.0, 75.0, 90.0, 100.0}Dim grade() As String={"F", "D", "C", "B", "A"}maxGradeLevel = grade.Length - 1// assign a grad to a student based on the student's scoregradeLevel= 0 studentGrade = ”A" while( studentGrade = "A" and gradeLevel < maxGradeLevel ) if( studentScore < rangeLimit( gradeLevel ) ) then studentGrade = grade ( gradeLevel) end if gradeLevel = gradeLevel + 1 wend 与其他表驱动法相比,这种方法的优点在于它很适合处理那些无规则的数据。 在使用阶梯访问时需要注意的一些细节: 1)留心边界端点 注意边界:< 与 <=,确认循环能够在找出最高一级区间后恰当地终止。 2)考虑用二分查找取代顺序查找 如果列表很大,可以把它替换成一个准二分查找法,从头查找是很耗费性能的 3)考虑用索引访问来取代阶梯访问 阶梯访问中的查找操作可能会比较耗时,如果执行速度很重要,那可以考虑用索引访问来取代阶梯查找,即以牺牲存储空间来换取速度。 2.4 构造查询键值 如上述例子,我们希望能够将数据作为键值直接访问表,这样既简单又快速。 但是问题或者数据通常并不是这样友好,那就需要引出 构造查询键值 的方法。 费率与年龄、性别、婚姻及交费年数等不同情况而变动。 1)复制信息从而能够直接使用键值 age补齐:50 岁以上的年龄都复制一份 50 岁的费率。 这样优点在于表自身结构非常简单那,访问表的逻辑也很简单; 缺点在于复制生成的冗余信息会浪费空间,也即是利用空间换效率。 2)转换键值以使其能够直接使用 费率表查询时,用一个函数将 age 转换为另一个数值。 在此例子中,该函数必须把所有介于 0-5 直接的年龄转换成一个键值,例如 5,同时把所有超过 50 的年龄都转换成另一个键值,例如 50。 这样在检索前可以用 min()和 max()函数来做这一转换。 例如,你可以用下述表达式:max(min(50, age), 17) 来生成一个介于 17-50 之间的表键值。 3)把键值转换提取城独立子程序 如果你必须要构造一些数据来让它们像表键值一样使用,那就把数据到键值的转换操作提取成独立的子程序。这样可避免在不同位置执行了不同的转换,也使得转换操作修改起来更加容易。 任务是个方法,不再是数值了,这里我们可以利用 Dart 这样的支持高阶函数的语言特性,把方法当做一个对象存储在表中。 var data = <String, Map>{ "A": { "name": "AA", "action": (name) => print(name + "/AA"), }, "B": { "name": "BB", "action": (name) => print(name + "/BB"), }, }; var action = data["A"]["action"]; action("kk"); 3、总结 1)如何从表中查数据? List item 直接访问 索引访问 阶梯访问 2)在表里存些什么? 数据 动作(action)-描述该动作的代码/该动作的子程序的引用。 表驱动法提供了一种复杂的逻辑和继承结构的替换方案。如果你发现自己对某个应用程序的逻辑或者继承关系感到困惑,那是否可以通过一个查询表来加以简化。 使用表的关键决策是决定如何去访问表,可以采取直接访问、索引访问或阶梯访问 使用表的另一项关键决策是决定如何去把什么内容放入表中 需要保存浮点数和范围数时,使用阶梯访问的形式。 Thanks for reading! 关注公众号,免费领学习资料 如果您觉得还不错,欢迎关注和转发~ 本文分享自微信公众号 - 架构精进之路(jiagou_jingjin)。如有侵权,请联系 support@oschina.cn 删除。本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。