Java并发编程之ThreadGroup
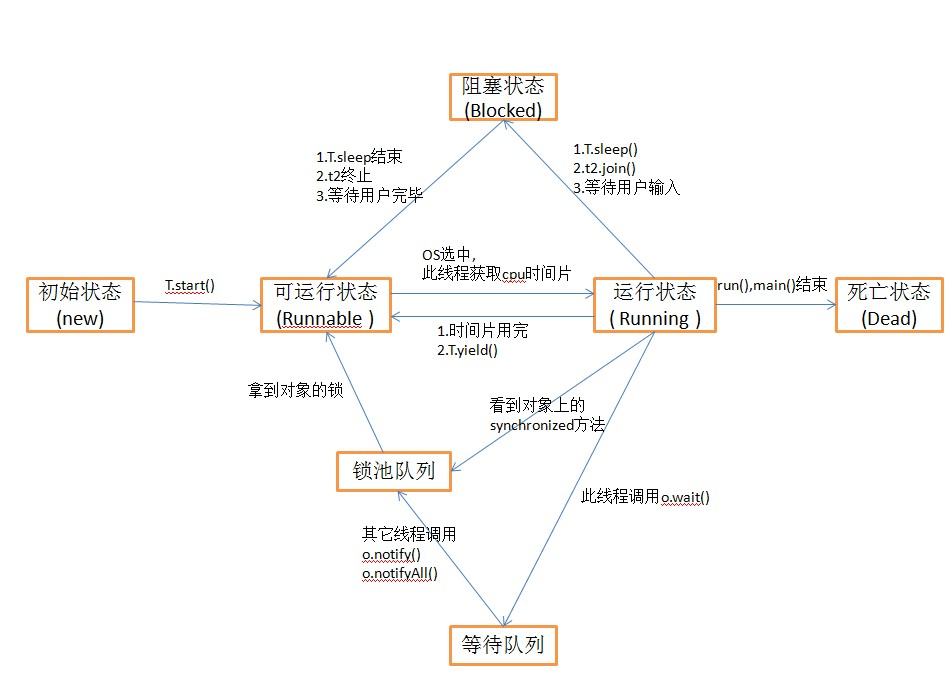
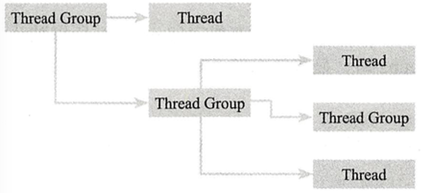
ThreadGroup是Java提供的一种对线程进行分组管理的手段,可以对所有线程以组为单位进行操作,如设置优先级、守护线程等。 线程组也有父子的概念,如下图: 线程组的创建 1 public class ThreadGroupCreator { 2 3 public static void main(String[] args) { 4 //获取当前线程的group 5 ThreadGroup currentGroup = Thread.currentThread().getThreadGroup(); 6 //在当前线程执行流中新建一个Group1 7 ThreadGroup group1 = new ThreadGroup("Group1"); 8 //Group1的父线程,就是main线程所在Group 9 System.out.println(group1.getParent() == currentGroup); 10 //定义Group2, 指定group1为其父线程 11 ThreadGroup group2 = new ThreadGroup(group1, "Group2"); 12 System.out.println(group2.getParent() == group1); 13 } 14 } 线程组的基本操作 注意:后添加进线程组的线程,其优先级不能大于线程组的优先级 1 public class ThreadGroupBasic { 2 3 public static void main(String[] args) throws InterruptedException { 4 5 ThreadGroup group = new ThreadGroup("group1"); 6 Thread thread = new Thread(group, () -> { 7 while(true) { 8 try { 9 TimeUnit.SECONDS.sleep(1); 10 } catch (InterruptedException e) { 11 e.printStackTrace(); 12 } 13 } 14 }, "thread"); 15 thread.setDaemon(true); 16 thread.start(); 17 18 TimeUnit.MILLISECONDS.sleep(1); 19 20 ThreadGroup mainGroup = Thread.currentThread().getThreadGroup(); 21 //递归获取mainGroup中活跃线程的估计值 22 System.out.println("activeCount = " + mainGroup.activeCount()); 23 //递归获mainGroup中的活跃子group 24 System.out.println("activeGroupCount = " + mainGroup.activeGroupCount()); 25 //获取group的优先级, 默认为10 26 System.out.println("getMaxPriority = " + mainGroup.getMaxPriority()); 27 //获取group的名字 28 System.out.println("getName = " + mainGroup.getName()); 29 //获取group的父group, 如不存在则返回null 30 System.out.println("getParent = " + mainGroup.getParent()); 31 //活跃线程信息全部输出到控制台 32 mainGroup.list(); 33 System.out.println("----------------------------"); 34 //判断当前group是不是给定group的父线程, 如果两者一样,也会返回true 35 System.out.println("parentOf = " + mainGroup.parentOf(group)); 36 System.out.println("parentOf = " + mainGroup.parentOf(mainGroup)); 37 38 } 39 40 } 线程组的Interrupt 1 ublic class ThreadGroupInterrupt { 2 3 public static void main(String[] args) throws InterruptedException { 4 ThreadGroup group = new ThreadGroup("TestGroup"); 5 new Thread(group, () -> { 6 while(true) { 7 try { 8 TimeUnit.MILLISECONDS.sleep(2); 9 } catch (InterruptedException e) { 10 //received interrupt signal and clear quickly 11 System.out.println(Thread.currentThread().isInterrupted()); 12 break; 13 } 14 } 15 System.out.println("t1 will exit"); 16 }, "t1").start(); 17 new Thread(group, () -> { 18 while(true) { 19 try { 20 TimeUnit.MILLISECONDS.sleep(2); 21 } catch (InterruptedException e) { 22 //received interrupt signal and clear quickly 23 System.out.println(Thread.currentThread().isInterrupted()); 24 break; 25 } 26 } 27 System.out.println("t2 will exit"); 28 }, "t2").start(); 29 //make sure all threads start 30 TimeUnit.MILLISECONDS.sleep(2); 31 32 group.interrupt(); 33 } 34 35 } 线程组的destroy 1 public class ThreadGroupDestroy { 2 3 public static void main(String[] args) { 4 ThreadGroup group = new ThreadGroup("TestGroup"); 5 ThreadGroup mainGroup = Thread.currentThread().getThreadGroup(); 6 //before destroy 7 System.out.println("group.isDestroyed=" + group.isDestroyed()); 8 mainGroup.list(); 9 10 group.destroy(); 11 //after destroy 12 System.out.println("group.isDestroyed=" + group.isDestroyed()); 13 mainGroup.list(); 14 } 15 16 } 线程组设置守护线程组 线程组设置为守护线程组,并不会影响其线程是否为守护线程,仅仅表示当它内部没有active的线程的时候,会自动destroy 1 public class ThreadGroupDaemon { 2 3 public static void main(String[] args) throws InterruptedException { 4 ThreadGroup group1 = new ThreadGroup("group1"); 5 new Thread(group1, () -> { 6 try { 7 TimeUnit.SECONDS.sleep(1); 8 } catch (InterruptedException e) { 9 e.printStackTrace(); 10 } 11 }, "group1-thread1").start(); 12 ThreadGroup group2 = new ThreadGroup("group2"); 13 new Thread(group2, () -> { 14 try { 15 TimeUnit.SECONDS.sleep(1); 16 } catch (InterruptedException e) { 17 e.printStackTrace(); 18 } 19 }, "group1-thread2").start(); 20 group2.setDaemon(true); 21 22 TimeUnit.SECONDS.sleep(3); 23 System.out.println(group1.isDestroyed()); 24 System.out.println(group2.isDestroyed()); 25 } 26 }