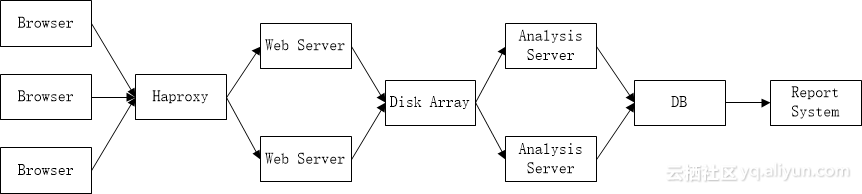
大数据信息挖掘中文分词是关键
在中文自然语言处理中,词是最小的能够独立活动的有意义的语言成分。汉语是以字为基本书写单位,词语之间没有明显的区分标记,因此进行中文自然语言处理通常是先将汉语文本中的字符串切分成合理的词语序列,然后再在此基础上进行其它分析处理。中文分词是中文信息处理的一个基础环节,已被广泛应用于中文文本处理、信息提取、文本挖掘等应用中。分词涉及许多方面的问题,主要包括: (1). 核心词表问题:许多分词算法都需要有一个核心的(通用、与领域无关的)词表。凡在该词表中的词,分词时就应该切分出来。但对于哪些词应当 收进核心词表,目前尚无一个标准; (2). 词的变形问题:汉语中的动词和形容词有些可以产生变形结构,如“打牌”、“开心”、“看见”、“相信”可能变形成“打打牌”、“开开心”、“看没看见”、“相不相信”等,对这些变形结构的切分往往缺少可操作而又合理的规范; (3). 词缀的问题:如语素“者”在现代汉语中单用是没有意义的,因此“作者”、“成功者”、“开发者”内部不能切开。 (4). 汉语自动分词规范须支持各种不同目标的应用,但不同目标的应用对词的要求是不同甚至是矛盾的。比如以词为单位的键盘输入系统为了提高输入速度,一些互现频率高的相互邻接的几个字也常作为输入单位,如“这是”、“每一”、“并不”、“不多”、“不在”、“就是”、“也就”等; NLPIR/ICTCLAS分词系统针对互联网内容处理的需要,融合了自然语言理解、网络搜索和文本挖掘的技术,可以支持中英文分词与词性标注,可视化系统可根据词性对不同的分词结果进行区分显示,一般虚词都是浅色,而名词、动词、形容词等实词为显著的颜色。系统还支持在线用户词典的输入,用户可以在右下方添加用户词及词性。 汉语词法分析能对汉语语言进行拆分处理,是中文信息处理必备的核心部件,采用条件随机场(Conditional Random Field,简称CRF)模型,分词准确率接近99%,具备准确率高、速度快、可适应性强等优势;特色功能包括:切分粒度可调整,融合20余部行业专有词典,支持用户自定义词典等。 词性标注能对汉语语言进行词性的自动标注,它能够真正理解中文,自动根据语言环境将词语诸如“建设”标注为“名词”或“动词”,采用条件随机场(Conditional Random Field,简称CRF)模型,一级词性标注准确率接近99%,具备准确率高、速度快、可适应性强等优势。 在信息处理中,分词是一项基本技术,因为中文的词汇是紧挨着的,不像英文有一个天然的空格符可以分隔开不同的单词。虽然把一串汉字划分成一个个词对于汉语使用者来说是很简单的事情,但对机器来说却很有挑战性,所以一直以来分词都是中文信息处理领域的重要的研究问题。