Java并发编程笔记之PriorityBlockingQueue源码分析
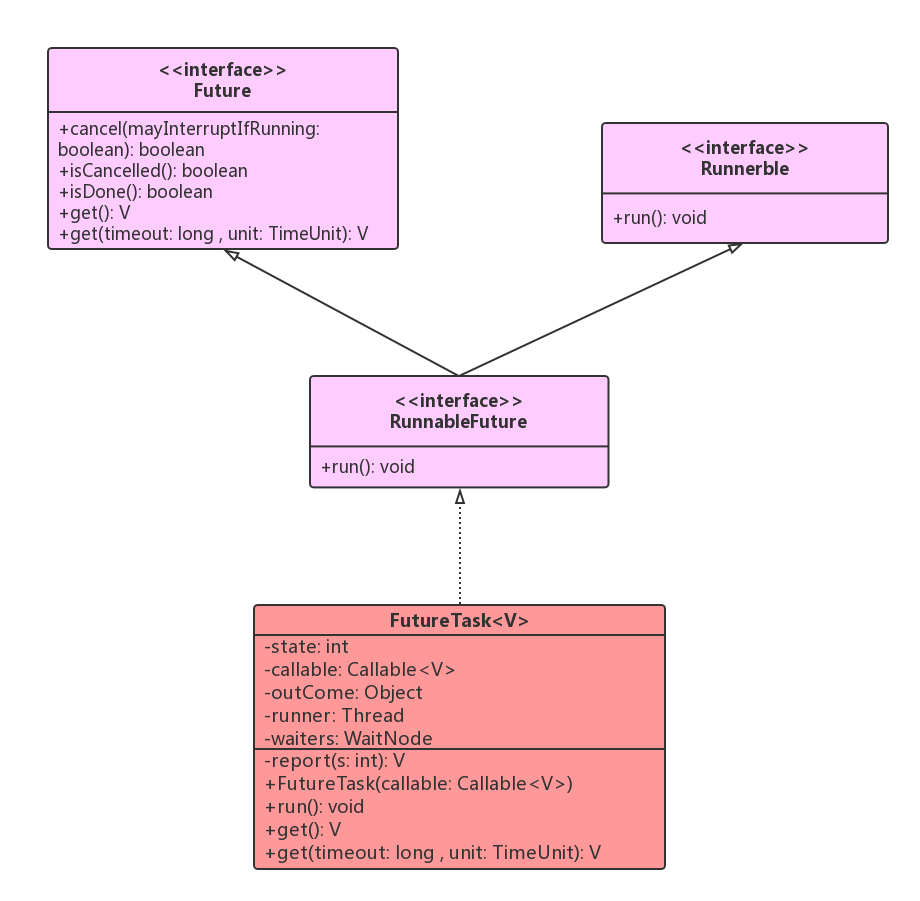
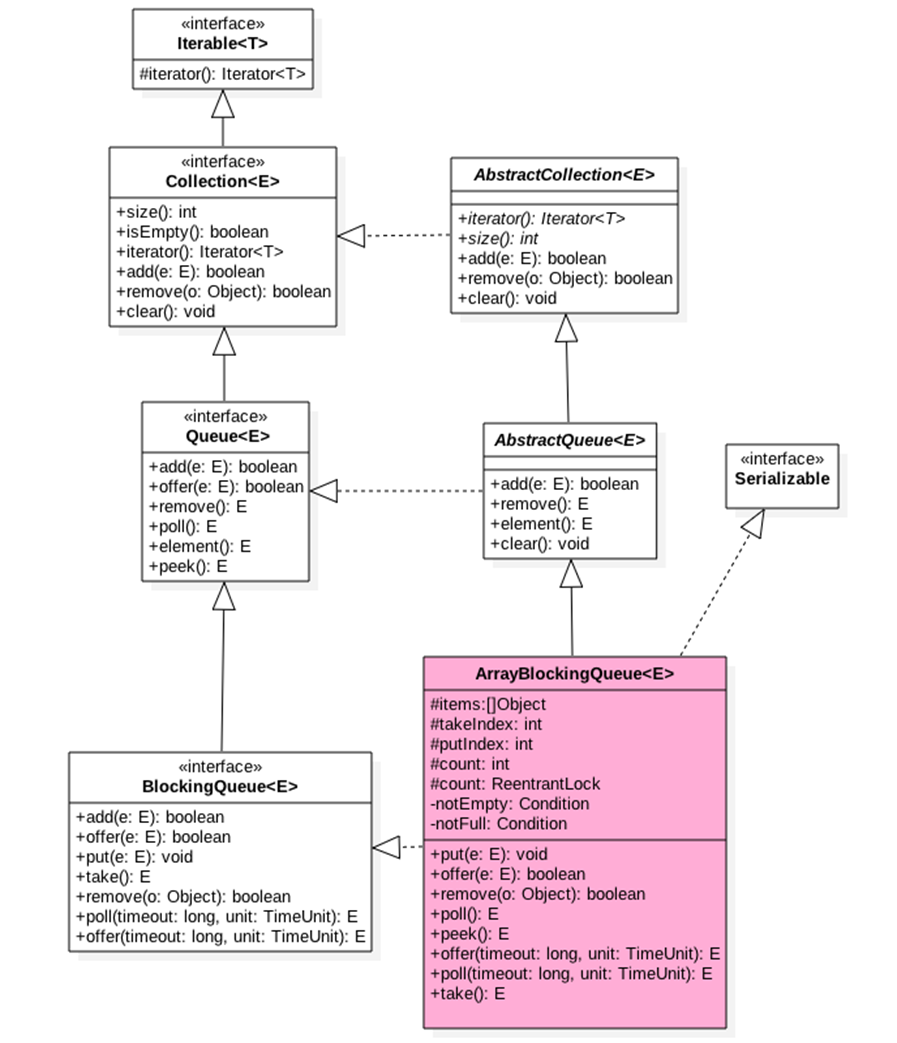
JDK 中无界优先级队列PriorityBlockingQueue 内部使用堆算法保证每次出队都是优先级最高的元素,元素入队时候是如何建堆的,元素出队后如何调整堆的平衡的? PriorityBlockingQueue是带优先级的无界阻塞队列,每次出队都返回优先级最好或者最低的元素,内部是平衡二叉树堆的实现。 首先看一下PriorityBlockingQueue类图结构,如下: 可以看到PriorityBlockingQueue内部有个数组queue用来存放队列元素,size用来存放队列元素个数,allocationSpinLock 是个自旋锁,用CAS操作来保证只有一个线程可以扩容队列, 状态为0 或者1,其中0标示当前没有在进行扩容,1标示当前正在扩容。 我们首先看看PriorityBlockingQueue的构造函数,源码如下: private static final int DEFAULT_INITIAL_CAPACITY = 11; public PriorityBlockingQueue() { this(DEFAULT_INITIAL_CAPACITY, null); } public PriorityBlockingQueue(int initialCapacity) { this(initialCapacity, null); } public PriorityBlockingQueue(int initialCapacity, Comparator<? super E> comparator) { if (initialCapacity < 1) throw new IllegalArgumentException(); this.lock = new ReentrantLock(); this.notEmpty = lock.newCondition(); this.comparator = comparator; this.queue = new Object[initialCapacity]; } 如上构造函数,默认队列容量为11,默认比较器为null,也就是使用元素的compareTo方法进行比较来确定元素的优先级,这意味着队列元素必须实现Comparable接口。 接下来我们主要看PriorityBlockingQueue的几个操作的源码,如下: 1.offer 操作,offer操作的作用是在队列插入一个元素,由于是无界队列,所以一直返回true,源码如下: public boolean offer(E e) { if (e == null) throw new NullPointerException(); //获取独占锁 final ReentrantLock lock = this.lock; lock.lock(); int n, cap; Object[] array; //如果当前元素个数>=队列容量,则扩容(1) while ((n = size) >= (cap = (array = queue).length)) tryGrow(array, cap); try { Comparator<? super E> cmp = comparator; //默认比较器为null (2) if (cmp == null) siftUpComparable(n, e, array); else //自定义比较器 (3) siftUpUsingComparator(n, e, array, cmp); //队列元素增加1,并且激活notEmpty的条件队列里面的一个阻塞线程(9) size = n + 1; notEmpty.signal();//激活调用take()方法被阻塞的线程 } finally { //释放独占锁 lock.unlock(); } return true; } 可以看到上面代码,offer操作主流程比较简单,接下来主要关注PriorityBlockingQueue是如何进行扩容的和内部如何建立堆的,首先看扩容源码如下: private void tryGrow(Object[] array, int oldCap) { lock.unlock(); //释放获取的锁 Object[] newArray = null; //cas成功则扩容(4) if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset, 0, 1)) { try { //oldGap<64则扩容新增oldcap+2,否者扩容50%,并且最大为MAX_ARRAY_SIZE int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : // 如果一开始容量很小,则扩容宽度变大 (oldCap >> 1)); if (newCap - MAX_ARRAY_SIZE > 0) { // 可能溢出 int minCap = oldCap + 1; if (minCap < 0 || minCap > MAX_ARRAY_SIZE) throw new OutOfMemoryError(); newCap = MAX_ARRAY_SIZE; } if (newCap > oldCap && queue == array) newArray = new Object[newCap]; } finally { allocationSpinLock = 0; } } //第一个线程cas成功后,第二个线程会进入这个地方,然后第二个线程让出cpu, //尽量让第一个线程执行下面点获取锁,但是这得不到肯定的保证。(5) if (newArray == null) // 如果两外一个线程正在分配,则让出 Thread.yield(); lock.lock();//(6) if (newArray != null && queue == array) { queue = newArray; System.arraycopy(array, 0, newArray, 0, oldCap); } } tryGrow 目的是扩容,这里要思考下为啥在扩容前要先释放锁,然后使用 cas 控制只有一个线程可以扩容成功呢? 其实这里不先释放锁也是可以的,也就是在整个扩容期间一直持有锁,但是扩容是需要花时间的,如果扩容的时候还占用锁,那么其他线程在这个时候是不能进行出队和入队操作的, 这大大降低了并发性。所以为了提高性能,使用CAS控制只有一个线程可以进行扩容,并且在扩容前释放了锁,让其他线程可以进行入队和出队操作。 spinlock锁使用CAS控制只有一个线程可以进行扩容,CAS失败的线程会调用Thread.yield() 让出 cpu,目的是为了让扩容线程扩容后优先调用lock.lock 重新获取锁, 但是这得不到一定的保证。有可能yield的线程在扩容线程扩容完成前已经退出,并执行了代码(6)获取到了锁。如果当前数组扩容还没完毕,当前线程会再次调用tryGrow方法, 然后释放锁,这又给扩容线程获取锁提供了机会,如果这时候扩容线程还没扩容完毕,则当前线程释放锁后又调用yield方法让出CPU。可知当扩容线程进行扩容期间, 其他线程是原地自旋通过代码(1)检查当前扩容是否完毕,等扩容完毕后才退出代码(1)的循环。 当扩容线程扩容完毕后会重置自旋锁变量allocationSpinLock 为 0,这里并没有使用UNSAFE方法的CAS进行设置是因为同时只可能有一个线程获取了该锁,并且 allocationSpinLock 被修饰为了 volatile。 当扩容线程扩容完毕后会执行代码 (6) 获取锁,获取锁后复制当前 queue 里面的元素到新数组。 接下来我们看看建堆算法,源码如下: private static <T> void siftUpComparable(int k, T x, Object[] array) { Comparable<? super T> key = (Comparable<? super T>) x; //队列元素个数>0则判断插入位置,否者直接入队(7) while (k > 0) { int parent = (k - 1) >>> 1; Object e = array[parent]; if (key.compareTo((T) e) >= 0) break; array[k] = e; k = parent; } array[k] = key;(8) } 接下来用图来解释上面的算法过程,假设队列初始化容量为2,创建的优先级队列的泛型参数为Integer。 首先调用队列offer(2)方法,希望插入元素2到队列,插入前队列状态如下图所示: 首先执行代码(1),从上图变量值可以知道判断值为false,所以紧接着执行代码(2),由于 k=n=size=0 所以代码(7)判断结果为 false,所以会执行代码(8)直接把元素 2 入队,最后执行代码(9)设置 size 的值加 1,这时候队列的状态如下图: 然后调用队列的 offer(4) 时候,首先执行代码(1),从上图变量值可知判断为 false,所以执行代码(2),由于 k=1, 所以进入 while 循环,由于 parent=0;e=2;key=4; 默认元素比较器是使用元素的 compareTo 方法, 可知 key>e 所以执行 break 退出 siftUpComparable 中的循环; 然后把元素存到数组下标为 1 的地方,最后执行代码(9)设置 size 的值加 1,这时候队列状态为: 然后调用队列的offer(6) 时候,首先执行代码(1),从上图变量值知道这时候判断值为true,所以嗲用tryGrow进行数组扩容,由于2 < 64 所以newCap=2 + (2+2)=6; 然后创建新数组并拷贝, 然后调用siftUpComparable 方法,由于 k=2>0 进入 while 循环,由于 parent=0;e=2;key=6;key>e 所以 break 后退出 while 循环; 并把元素 6 放入数组下标为 2 的地方,最后设置 size 的值加 1,现在队列状态: 然后调用队列的 offer(1) 时候,首先执行代码(1),从上图变量值知道这次判断值为 false,所以执行代码(2),由于k=3, 所以进入 while 循环,由于parent=0;e=4;key=1; key<e,所以把元素 4 复制到数组下标为 3 的地方, 然后 k=0 退出 while 循环;然后把元素 1 存放到下标为 0 地方,现在状态: 此时此刻的二叉树堆的树形图如下: 可知堆的根元素是 1,也就是这是一个最小堆,那么当调用这个优先级队列的 poll 方法时候,会一次返回堆里面值最小的元素。 2.poll操作,poll 操作作用是获取队列内部堆树的根节点元素,如果队列为空,则返回 null。源码如下: public E poll() { final ReentrantLock lock = this.lock; lock.lock();//获取独占锁 try { return dequeue(); } finally { lock.unlock();//释放独占锁 } } 如上代码可以知道在进行出队操作过程中要先加锁,这意味着,当前线程进行出队操作的时候,其他线程不能再进行入队和出队操作,但是从前面介绍offer函数的时候,知道这时候可以有其他线程进行扩容, 接下来,我们要看一下出队操作的dequeue方法的源码如下: private E dequeue() { //队列为空,则返回null int n = size - 1; if (n < 0) return null; else { //获取队头元素(1) Object[] array = queue; E result = (E) array[0]; //获取队尾元素,并值null(2) E x = (E) array[n]; array[n] = null; Comparator<? super E> cmp = comparator; if (cmp == null)//(3) siftDownComparable(0, x, array, n); else siftDownUsingComparator(0, x, array, n, cmp); size = n;//(4) return result; } } 如上代码,如果队列为空则直接返回 null,否者执行代码(1)获取数组第一个元素作为返回值存放到变量 Result,这里要注意一下数组里面第一个元素是优先级最小或者最大的元素,出队操作就是返回这个元素。 然后代码(2)获取队列尾部元素存放到变量X,并且置空尾部节点,然后执行代码(3)插入变量X 到数组下标为 0 的位置后,重新调整堆为最大或者最小堆,然后返回。 这里重要的是看如何去掉堆的根节点后,使用剩下的节点重新调整为一个最大或者最小堆。 接下来我们看看siftDownComparable 的源码,如下: private static <T> void siftDownComparable(int k, T x, Object[] array, int n) { if (n > 0) { Comparable<? super T> key = (Comparable<? super T>)x; int half = n >>> 1; // loop while a non-leaf while (k < half) { int child = (k << 1) + 1; // 假设左边子树最小 Object c = array[child];(5) int right = child + 1;(6) if (right < n && ((Comparable<? super T>) c).compareTo((T) array[right]) > 0)(7) c = array[child = right]; if (key.compareTo((T) c) <= 0)(8) break; array[k] = c; k = child; } array[k] = key;(9) } } 下面我们结合图来模拟上面调整堆的算法过程,接着上节队列的状态继续讲解,上节队列元素序列为 1,2,6,4: 第一次调用队列的 poll() 方法时候,首先执行代码(1)(2),这时候变量 size =4;n=3;result=1;x=4; 这时候队列状态图如下: 然后执行代码(3),调整堆后队列状态图,如下: 第二次调用队列的 poll() 方法时候,首先执行代码(1)(2),这时候变量 size =3;n=2;result=2;x=6; 这时候队列状态图,如下: 然后执行代码(3)调整堆后队列状态图,如下: 第三次调用队列的 poll() 方法时候,首先执行代码(1)(2),这时候变量 size =2;n=1;result=4;x=6; 这时候队列状态图,如下: 然后执行代码(3)调整堆后队列状态图,如下: 第四次直接返回元素 6. 接下来重点说说 siftDownComparable 这个调整堆的算法: 首先说下堆调整的思路,由于队列数组第 0 个元素为树根,出队时候要被移除,这时候数组就不在是最小堆了,所以需要调整堆, 具体是要从被移除的树根的左右子树中找一个最小的值来当树根,左右子树又会看自己作为树根节点的树的左右子树里面哪个是最小值,这是一个递归的过程,直到树叶节点结束递归, 如果不明白,下面结合图形来说明,假如当前队列内容如下: 对应的二叉堆树如下: 这时候如果调用了 poll(); 那么 result=2;x=11;队列末尾的元素设置为 null 后,剩下的元素调整堆的步骤如下图: 如上图(1)树根的 leftChildVal = 4;rightChildVal = 6; 4<6; 所以 c=4; 然后 11>4 也就是 key>c;所以使用元素 4 覆盖树根节点的值,现在堆对应的树如图(2)。 然后树根的左子树树根的左右孩子节点中 leftChildVal = 8;rightChildVal = 10; 8<10; 所以 c=8; 然后发现 11>8 也就是 key>c;所以元素 8 作为树根左子树的根节点,现在树的形状如图(3), 这时候判断 k<half 为 false 就会退出循环,然后把 x=11 设置到数组下标为 3 的地方,这时候堆树如图(4),至此调整堆完毕,siftDownComparable 返回 result=2,poll 方法也返回了。 3.put操作,put 操作内部调用的 offer, 由于是无界队列,所以不需要阻塞,源码如下: public void put(E e) { offer(e); // never need to block } 4.take 操作,take 操作作用是获取队列内部堆树的根节点元素,如果队列为空则阻塞,源码如下: public E take() throws InterruptedException { //获取锁,可被中断 final ReentrantLock lock = this.lock; lock.lockInterruptibly(); E result; try { //如果队列为空,则阻塞,把当前线程放入notEmpty的条件队列 while ( (result = dequeue()) == null) notEmpty.await();//阻塞当前线程 } finally { lock.unlock();//释放锁 } return result; } 如上代码,首先通过 lock.lockInterruptibly() 获取独占锁,这个方式获取的锁是对中断进行响应的。然后调用 dequeue 方法返回堆树根节点元素,如果队列为空,则返回 false, 然后当前线程调用 notEmpty.await() 阻塞挂起当前线程,直到有线程调用了 offer()方法(offer 方法内在添加元素成功后调用了 notEmpty.signal 方法会激活一个阻塞在 notEmpty 的条件队列里面的一个线程)。 另外这里使用 while 而不是 if 是为了避免虚假唤醒。 5.size操作,获取队列元个数,如下代码,在返回 size 前加了锁,保证在调用 size() 方法时候不会有其它线程进行入队和出队操作,另外由于 size 变量没有被修饰为 volatie,这里加锁也保证了多线程下 size 变量的内存可见性。源码如下: public int size() { final ReentrantLock lock = this.lock; lock.lock(); try { return size; } finally { lock.unlock(); } } 总结:PriorityBlockingQueue 队列内部使用二叉树堆维护元素优先级,内部使用数组作为元素存储的数据结构,这个数组是可以扩容的,当前元素个数 >= 最大容量的时候会通过算法扩容, 出队的时候始终保证出队的元素是堆树的根节点,而不是在队列里面停留时间最长的元素,默认元素优先级比较规则是使用元素的compareTo方法来做,用户可以自定义优先级的比较优先级。