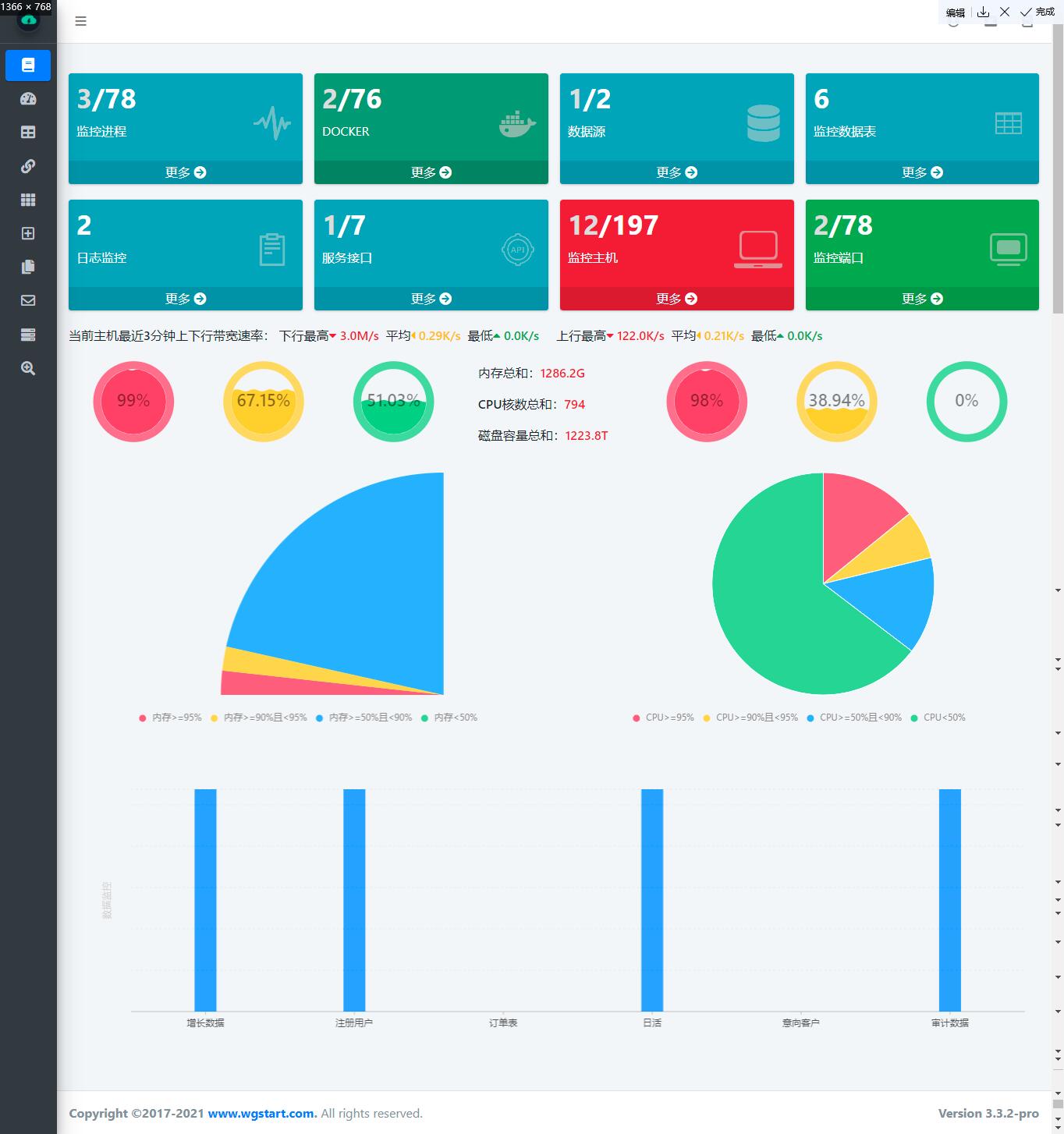
开源即时通讯应用 Tailchat v1.9.5 发布,插件化分布式 noIM 应用
介绍 Tailchat是一款插件化易拓展的开源 IM 应用。可拓展架构赋予Tailchat无限可能性。 前端微内核架构 + 后端微服务架构 使得Tailchat能够驾驭任何定制化 / 私有化的场景 面向企业与私域用户打造,高度自由的群组管理与定制化的面板展示可以让私域主能够更好的展示自己的作品,管理用户,打造自己的品牌与圈子。 官方网站:https://tailchat.msgbyte.com/ v1.9.5 更新内容 特性更新 livekit 插件增加成员面板 你可以在成员面板中查看所有参会者的列表,以及麦克风情况 livekit 插件增加多人会话发起音视频会话功能 现在你可以直接从私信会话中直接发起音视频呼叫了 livekit 插件增加多人会话自动邀请功能 当对方从私信会话中发送消息,则会自动发起邀请功能,如果接收方在线,则会弹出提示弹窗与铃声邀请加入会话(前提是接收方安装了livekit插件) 群组成员列表允许右键快速修改身份组 现在允许在群组成员列表中通过右键菜单快速分配成员身份组,这对于需要频繁分配身份的场景非常好用 增加好友列表搜索功能 为了进一步优化对于多好友情况的管理,增加了好友列表搜索框,用于基于好友昵称快速过滤好友,帮助用户找到好友。 其他更新 增加notification弹窗夜间模式支持 增加环境变量 MINIO_SSL 用于手动控制minio ssl,适用于使用外部s3存储 设置页面增加重新加载按钮,用于在非网页模式下方便重新加载tailchat 网页面板增加背景色选项,用于处理部分网页透明背景导致的样式问题 修复消息输入框背景色透明的bug 修复ban用户时清理缓存的时序问题可能导致的token过期不生效问题 修复了在私人对话中回复时收件箱 groupId 不正确的问题 (desktop): v0.1.0 改进了服务器列表的管理